 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHISMA: A Speech-LLM to Perform Zero-shot Spoken Language Understanding
Aug 29, 2024



Speech large language models (speech-LLMs) integrate speech and text-based foundation models to provide a unified framework for handling a wide range of downstream tasks. In this paper, we introduce WHISMA, a speech-LLM tailored for spoken language understanding (SLU) that demonstrates robust performance in various zero-shot settings. WHISMA combines the speech encoder from Whisper with the Llama-3 LLM, and is fine-tuned in a parameter-efficient manner on a comprehensive collection of SLU-related datasets. Our experiments show that WHISMA significantly improves the zero-shot slot filling performance on the SLURP benchmark, achieving a relative gain of 26.6% compared to the current state-of-the-art model. Furthermore, to evaluate WHISMA's generalisation capabilities to unseen domains, we develop a new task-agnostic benchmark named SLU-GLUE. The evaluation results indicate that WHISMA outperforms an existing speech-LLM (Qwen-Audio) with a relative gain of 33.0%.
Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
Jun 21, 2024



Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
Evaluating Large Language Models for Document-grounded Response Generation in Information-Seeking Dialogues
Sep 21, 2023
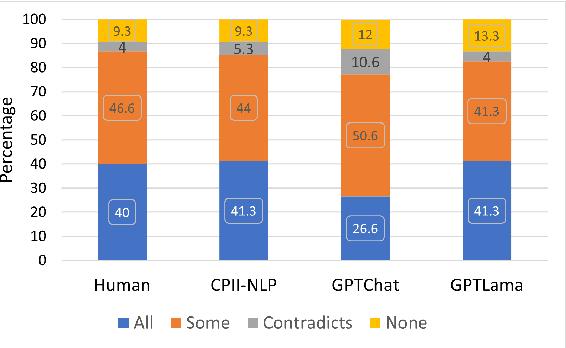


In this paper, we investigate the use of large language models (LLMs) like ChatGPT for document-grounded response generation in the context of information-seeking dialogues. For evaluation, we use the MultiDoc2Dial corpus of task-oriented dialogues in four social service domains previously used in the DialDoc 2022 Shared Task. Information-seeking dialogue turns are grounded in multiple documents providing relevant information. We generate dialogue completion responses by prompting a ChatGPT model, using two methods: Chat-Completion and LlamaIndex. ChatCompletion uses knowledge from ChatGPT model pretraining while LlamaIndex also extracts relevant information from documents. Observing that document-grounded response generation via LLMs cannot be adequately assessed by automatic evaluation metrics as they are significantly more verbose, we perform a human evaluation where annotators rate the output of the shared task winning system, the two Chat-GPT variants outputs, and human responses. While both ChatGPT variants are more likely to include information not present in the relevant segments, possibly including a presence of hallucinations, they are rated higher than both the shared task winning system and human responses.
Adversarial learning of neural user simulators for dialogue policy optimisation
Jun 01, 2023



Reinforcement learning based dialogue policies are typically trained in interaction with a user simulator. To obtain an effective and robust policy, this simulator should generate user behaviour that is both realistic and varied. Current data-driven simulators are trained to accurately model the user behaviour in a dialogue corpus. We propose an alternative method using adversarial learning, with the aim to simulate realistic user behaviour with more variation. We train and evaluate several simulators on a corpus of restaurant search dialogues, and then use them to train dialogue system policies. In policy cross-evaluation experiments we demonstrate that an adversarially trained simulator produces policies with 8.3% higher success rate than those trained with a maximum likelihood simulator. Subjective results from a crowd-sourced dialogue system user evaluation confirm the effectiveness of adversarially training user simulators.
Dialogue Strategy Adaptation to New Action Sets Using Multi-dimensional Modelling
Apr 14, 2022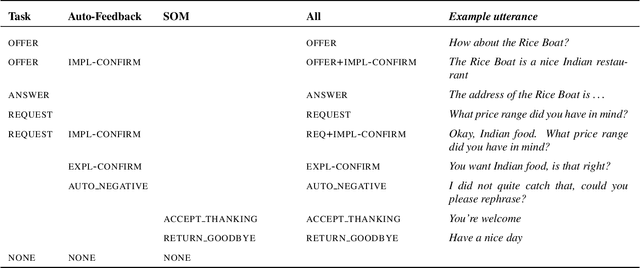
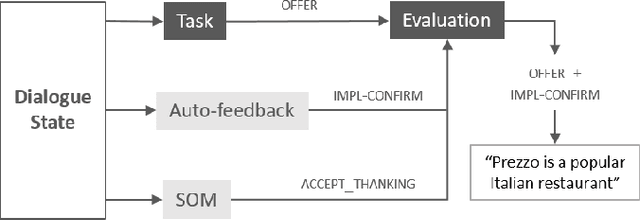
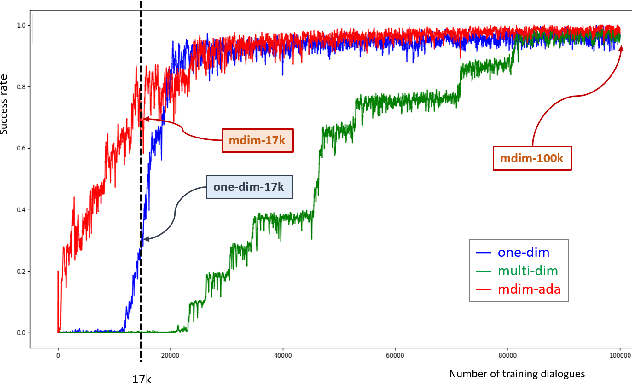
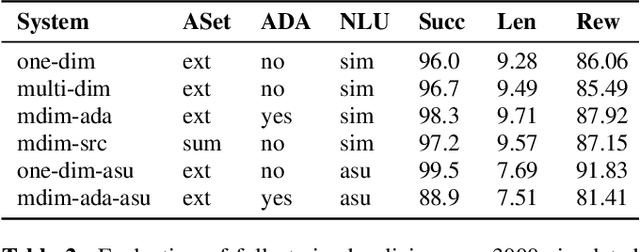
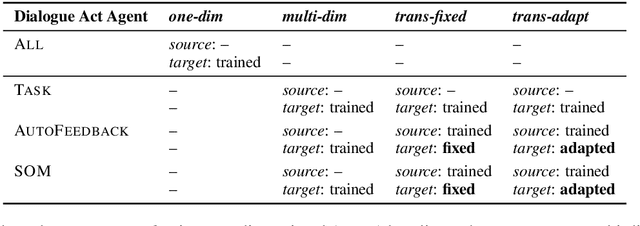
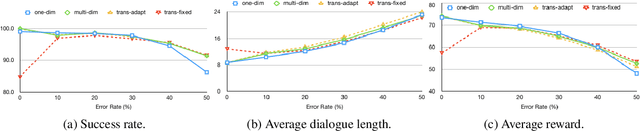
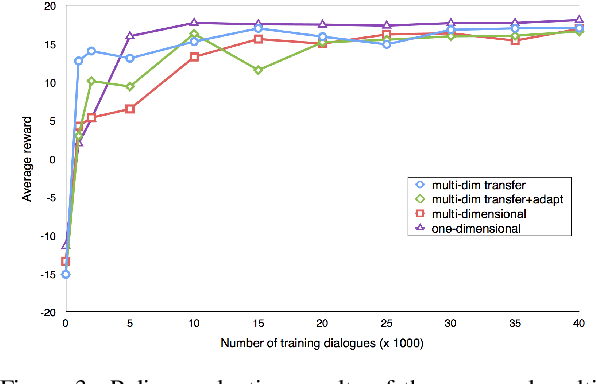
A major bottleneck for building statistical spoken dialogue systems for new domains and applications is the need for large amounts of training data. To address this problem, we adopt the multi-dimensional approach to dialogue management and evaluate its potential for transfer learning. Specifically, we exploit pre-trained task-independent policies to speed up training for an extended task-specific action set, in which the single summary action for requesting a slot is replaced by multiple slot-specific request actions. Policy optimisation and evaluation experiments using an agenda-based user simulator show that with limited training data, much better performance levels can be achieved when using the proposed multi-dimensional adaptation method. We confirm this improvement in a crowd-sourced human user evaluation of our spoken dialogue system, comparing partially trained policies. The multi-dimensional system (with adaptation on limited training data in the target scenario) outperforms the one-dimensional baseline (without adaptation on the same amount of training data) by 7% perceived success rate.
A study on cross-corpus speech emotion recognition and data augmentation
Jan 10, 2022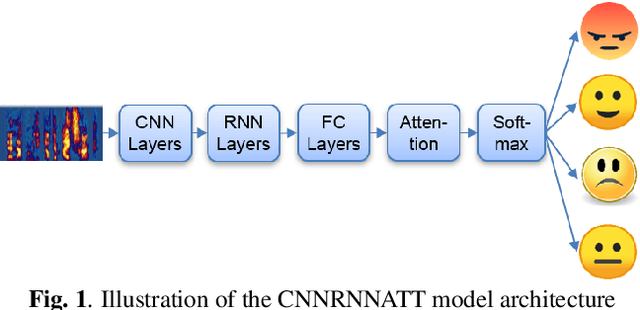
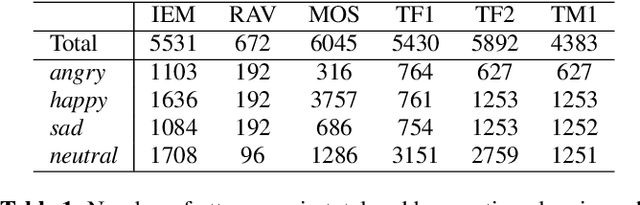

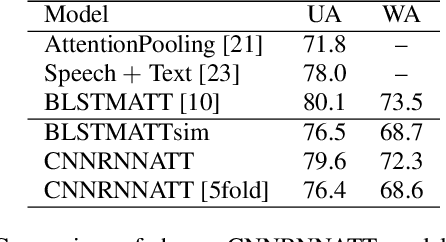
Models that can handle a wide range of speakers and acoustic conditions are essential in speech emotion recognition (SER). Often, these models tend to show mixed results when presented with speakers or acoustic conditions that were not visible during training. This paper investigates the impact of cross-corpus data complementation and data augmentation on the performance of SER models in matched (test-set from same corpus) and mismatched (test-set from different corpus) conditions. Investigations using six emotional speech corpora that include single and multiple speakers as well as variations in emotion style (acted, elicited, natural) and recording conditions are presented. Observations show that, as expected, models trained on single corpora perform best in matched conditions while performance decreases between 10-40% in mismatched conditions, depending on corpus specific features. Models trained on mixed corpora can be more stable in mismatched contexts, and the performance reductions range from 1 to 8% when compared with single corpus models in matched conditions. Data augmentation yields additional gains up to 4% and seem to benefit mismatched conditions more than matched ones.
Action State Update Approach to Dialogue Management
Nov 10, 2020
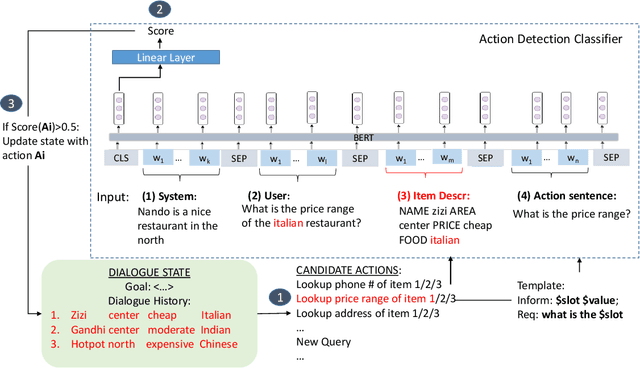


Utterance interpretation is one of the main functions of a dialogue manager, which is the key component of a dialogue system. We propose the action state update approach (ASU) for utterance interpretation, featuring a statistically trained binary classifier used to detect dialogue state update actions in the text of a user utterance. Our goal is to interpret referring expressions in user input without a domain-specific natural language understanding component. For training the model, we use active learning to automatically select simulated training examples. With both user-simulated and interactive human evaluations, we show that the ASU approach successfully interprets user utterances in a dialogue system, including those with referring expressions.
User Evaluation of a Multi-dimensional Statistical Dialogue System
Sep 06, 2019

We present the first complete spoken dialogue system driven by a multi-dimensional statistical dialogue manager. This framework has been shown to substantially reduce data needs by leveraging domain-independent dimensions, such as social obligations or feedback, which (as we show) can be transferred between domains. In this paper, we conduct a user study and show that the performance of a multi-dimensional system, which can be adapted from a source domain, is equivalent to that of a one-dimensional baseline, which can only be trained from scratch.
Towards Learning Transferable Conversational Skills using Multi-dimensional Dialogue Modelling
Mar 31, 2018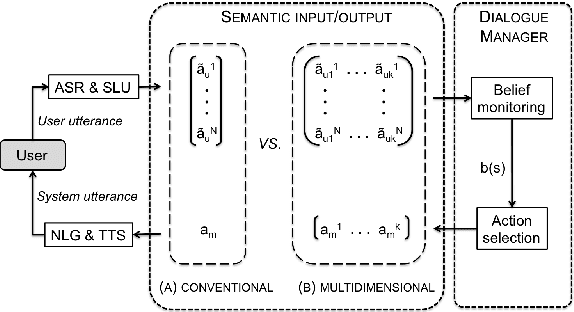

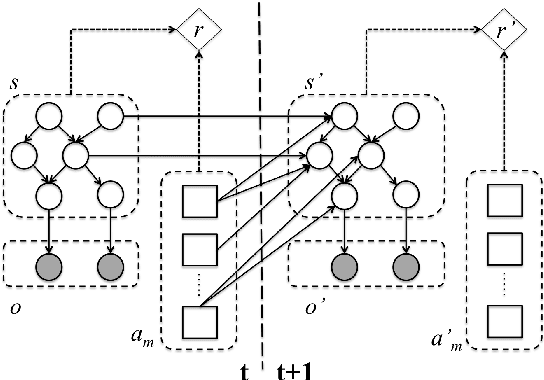
Recent statistical approaches have improved the robustness and scalability of spoken dialogue systems. However, despite recent progress in domain adaptation, their reliance on in-domain data still limits their cross-domain scalability. In this paper, we argue that this problem can be addressed by extending current models to reflect and exploit the multi-dimensional nature of human dialogue. We present our multi-dimensional, statistical dialogue management framework, in which transferable conversational skills can be learnt by separating out domain-independent dimensions of communication and using multi-agent reinforcement learning. Our initial experiments with a simulated user show that we can speed up the learning process by transferring learnt policies.
Strategic Dialogue Management via Deep Reinforcement Learning
Nov 25, 2015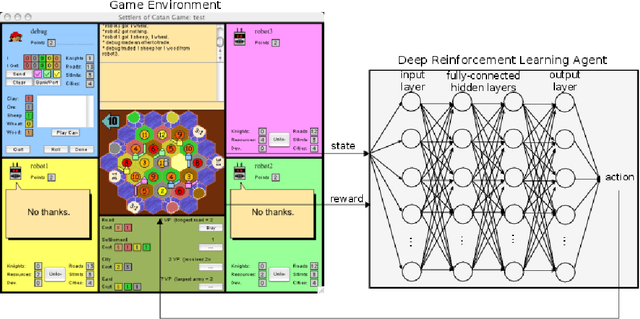

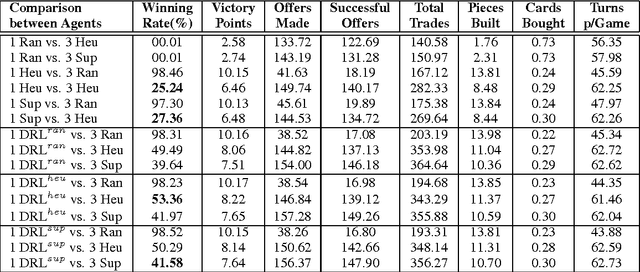
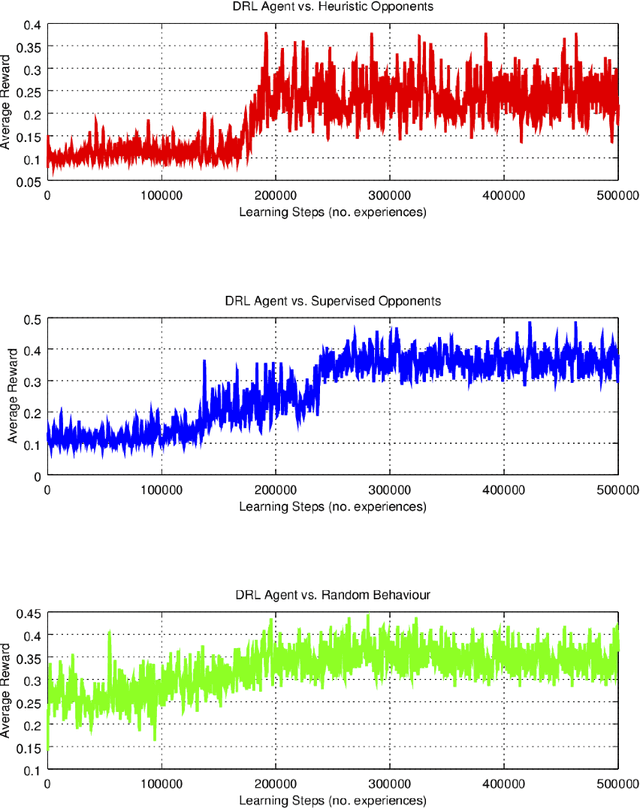
Artificially intelligent agents equipped with strategic skills that can negotiate during their interactions with other natural or artificial agents are still underdeveloped. This paper describes a successful application of Deep Reinforcement Learning (DRL) for training intelligent agents with strategic conversational skills, in a situated dialogue setting. Previous studies have modelled the behaviour of strategic agents using supervised learning and traditional reinforcement learning techniques, the latter using tabular representations or learning with linear function approximation. In this study, we apply DRL with a high-dimensional state space to the strategic board game of Settlers of Catan---where players can offer resources in exchange for others and they can also reply to offers made by other players. Our experimental results report that the DRL-based learnt policies significantly outperformed several baselines including random, rule-based, and supervised-based behaviours. The DRL-based policy has a 53% win rate versus 3 automated players (`bots'), whereas a supervised player trained on a dialogue corpus in this setting achieved only 27%, versus the same 3 bots. This result supports the claim that DRL is a promising framework for training dialogue systems, and strategic agents with negotiation abilities.