 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWHISMA: A Speech-LLM to Perform Zero-shot Spoken Language Understanding
Aug 29, 2024



Speech large language models (speech-LLMs) integrate speech and text-based foundation models to provide a unified framework for handling a wide range of downstream tasks. In this paper, we introduce WHISMA, a speech-LLM tailored for spoken language understanding (SLU) that demonstrates robust performance in various zero-shot settings. WHISMA combines the speech encoder from Whisper with the Llama-3 LLM, and is fine-tuned in a parameter-efficient manner on a comprehensive collection of SLU-related datasets. Our experiments show that WHISMA significantly improves the zero-shot slot filling performance on the SLURP benchmark, achieving a relative gain of 26.6% compared to the current state-of-the-art model. Furthermore, to evaluate WHISMA's generalisation capabilities to unseen domains, we develop a new task-agnostic benchmark named SLU-GLUE. The evaluation results indicate that WHISMA outperforms an existing speech-LLM (Qwen-Audio) with a relative gain of 33.0%.
An LLM Feature-based Framework for Dialogue Constructiveness Assessment
Jun 20, 2024



Research on dialogue constructiveness assessment focuses on (i) analysing conversational factors that influence individuals to take specific actions, win debates, change their perspectives or broaden their open-mindedness and (ii) predicting constructive outcomes following dialogues for such use cases. These objectives can be achieved by training either interpretable feature-based models (which often involve costly human annotations) or neural models such as pre-trained language models (which have empirically shown higher task accuracy but lack interpretability). We propose a novel LLM feature-based framework that combines the strengths of feature-based and neural approaches while mitigating their downsides, in assessing dialogue constructiveness. The framework first defines a set of dataset-independent and interpretable linguistic features, which can be extracted by both prompting an LLM and simple heuristics. Such features are then used to train LLM feature-based models. We apply this framework to three datasets of dialogue constructiveness and find that our LLM feature-based models significantly outperform standard feature-based models and neural models, and tend to learn more robust prediction rules instead of relying on superficial shortcuts (as seen with neural models). Further, we demonstrate that interpreting these LLM feature-based models can yield valuable insights into what makes a dialogue constructive.
Opening up Minds with Argumentative Dialogues
Jan 16, 2023
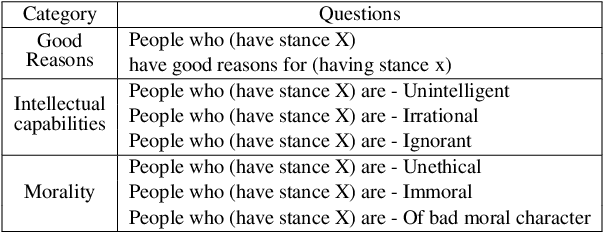

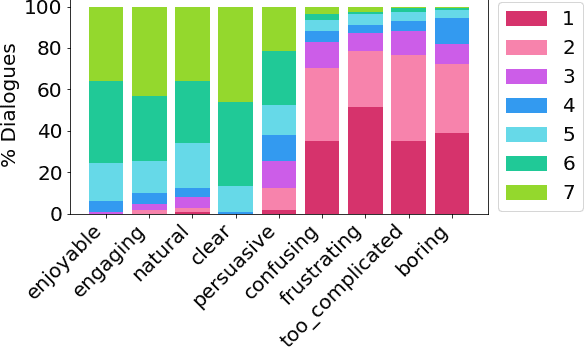
Recent research on argumentative dialogues has focused on persuading people to take some action, changing their stance on the topic of discussion, or winning debates. In this work, we focus on argumentative dialogues that aim to open up (rather than change) people's minds to help them become more understanding to views that are unfamiliar or in opposition to their own convictions. To this end, we present a dataset of 183 argumentative dialogues about 3 controversial topics: veganism, Brexit and COVID-19 vaccination. The dialogues were collected using the Wizard of Oz approach, where wizards leverage a knowledge-base of arguments to converse with participants. Open-mindedness is measured before and after engaging in the dialogue using a questionnaire from the psychology literature, and success of the dialogue is measured as the change in the participant's stance towards those who hold opinions different to theirs. We evaluate two dialogue models: a Wikipedia-based and an argument-based model. We show that while both models perform closely in terms of opening up minds, the argument-based model is significantly better on other dialogue properties such as engagement and clarity.
Analyzing Neural Discourse Coherence Models
Nov 12, 2020



In this work, we systematically investigate how well current models of coherence can capture aspects of text implicated in discourse organisation. We devise two datasets of various linguistic alterations that undermine coherence and test model sensitivity to changes in syntax and semantics. We furthermore probe discourse embedding space and examine the knowledge that is encoded in representations of coherence. We hope this study shall provide further insight into how to frame the task and improve models of coherence assessment further. Finally, we make our datasets publicly available as a resource for researchers to use to test discourse coherence models.
Multi-Task Learning for Coherence Modeling
Jul 04, 2019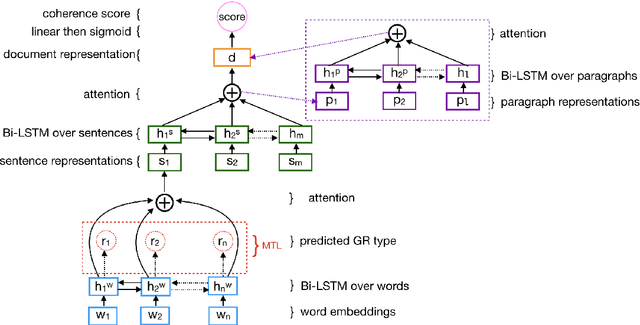



We address the task of assessing discourse coherence, an aspect of text quality that is essential for many NLP tasks, such as summarization and language assessment. We propose a hierarchical neural network trained in a multi-task fashion that learns to predict a document-level coherence score (at the network's top layers) along with word-level grammatical roles (at the bottom layers), taking advantage of inductive transfer between the two tasks. We assess the extent to which our framework generalizes to different domains and prediction tasks, and demonstrate its effectiveness not only on standard binary evaluation coherence tasks, but also on real-world tasks involving the prediction of varying degrees of coherence, achieving a new state of the art.
* 11 pages, 3 figures, Accepted at ACL 2019
Neural Automated Essay Scoring and Coherence Modeling for Adversarially Crafted Input
Apr 23, 2018
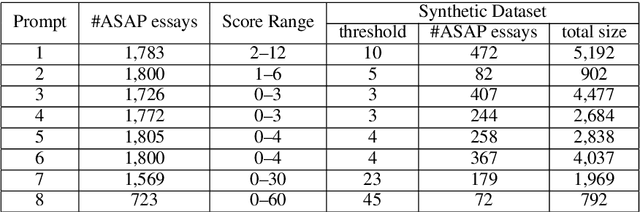

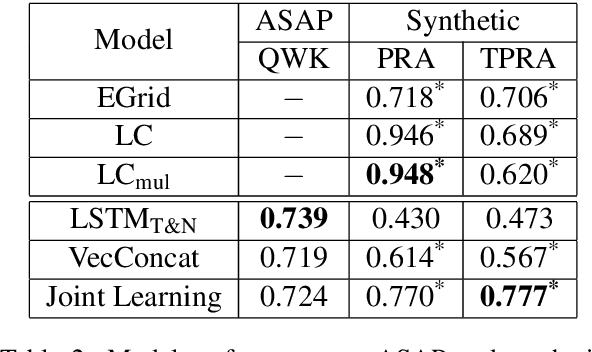
We demonstrate that current state-of-the-art approaches to Automated Essay Scoring (AES) are not well-suited to capturing adversarially crafted input of grammatical but incoherent sequences of sentences. We develop a neural model of local coherence that can effectively learn connectedness features between sentences, and propose a framework for integrating and jointly training the local coherence model with a state-of-the-art AES model. We evaluate our approach against a number of baselines and experimentally demonstrate its effectiveness on both the AES task and the task of flagging adversarial input, further contributing to the development of an approach that strengthens the validity of neural essay scoring models.
An Error-Oriented Approach to Word Embedding Pre-Training
Jul 21, 2017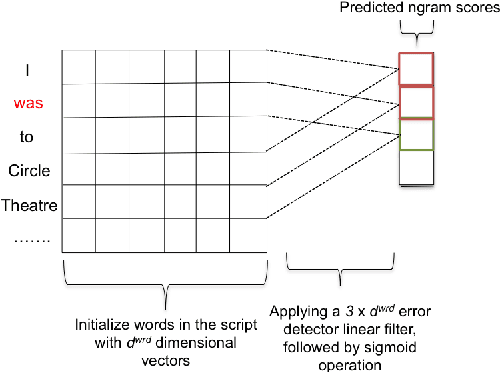

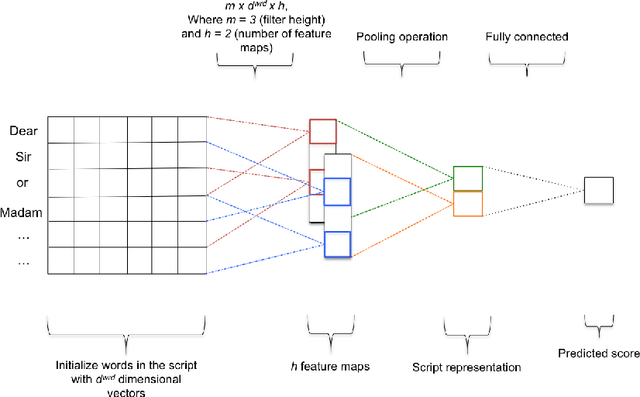

We propose a novel word embedding pre-training approach that exploits writing errors in learners' scripts. We compare our method to previous models that tune the embeddings based on script scores and the discrimination between correct and corrupt word contexts in addition to the generic commonly-used embeddings pre-trained on large corpora. The comparison is achieved by using the aforementioned models to bootstrap a neural network that learns to predict a holistic score for scripts. Furthermore, we investigate augmenting our model with error corrections and monitor the impact on performance. Our results show that our error-oriented approach outperforms other comparable ones which is further demonstrated when training on more data. Additionally, extending the model with corrections provides further performance gains when data sparsity is an issue.