 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue Systems
Mar 06, 2025The proliferation of generative models has presented significant challenges in distinguishing authentic human-authored content from deepfake content. Collaborative human efforts, augmented by AI tools, present a promising solution. In this study, we explore the potential of DeepFakeDeLiBot, a deliberation-enhancing chatbot, to support groups in detecting deepfake text. Our findings reveal that group-based problem-solving significantly improves the accuracy of identifying machine-generated paragraphs compared to individual efforts. While engagement with DeepFakeDeLiBot does not yield substantial performance gains overall, it enhances group dynamics by fostering greater participant engagement, consensus building, and the frequency and diversity of reasoning-based utterances. Additionally, participants with higher perceived effectiveness of group collaboration exhibited performance benefits from DeepFakeDeLiBot. These findings underscore the potential of deliberative chatbots in fostering interactive and productive group dynamics while ensuring accuracy in collaborative deepfake text detection. \textit{Dataset and source code used in this study will be made publicly available upon acceptance of the manuscript.
Conformity in Large Language Models
Oct 16, 2024



The conformity effect describes the tendency of individuals to align their responses with the majority. Studying this bias in large language models (LLMs) is crucial, as LLMs are increasingly used in various information-seeking and decision-making tasks as conversation partners to improve productivity. Thus, conformity to incorrect responses can compromise their effectiveness. In this paper, we adapt psychological experiments to examine the extent of conformity in state-of-the-art LLMs. Our findings reveal that all models tested exhibit varying levels of conformity toward the majority, regardless of their initial choice or correctness, across different knowledge domains. Notably, we are the first to show that LLMs are more likely to conform when they are more uncertain in their own prediction. We further explore factors that influence conformity, such as training paradigms and input characteristics, finding that instruction-tuned models are less susceptible to conformity, while increasing the naturalness of majority tones amplifies conformity. Finally, we propose two interventions--Devil's Advocate and Question Distillation--to mitigate conformity, providing insights into building more robust language models.
The effect of diversity on group decision-making
Feb 02, 2024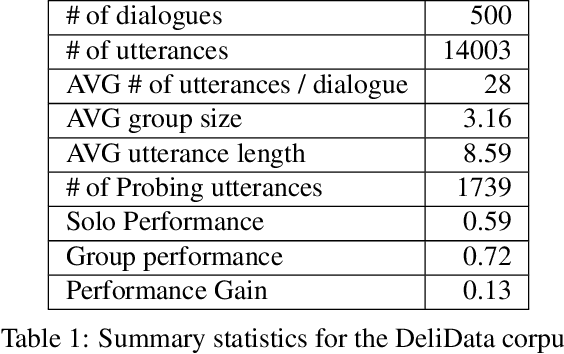
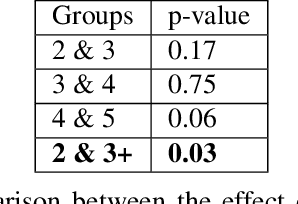
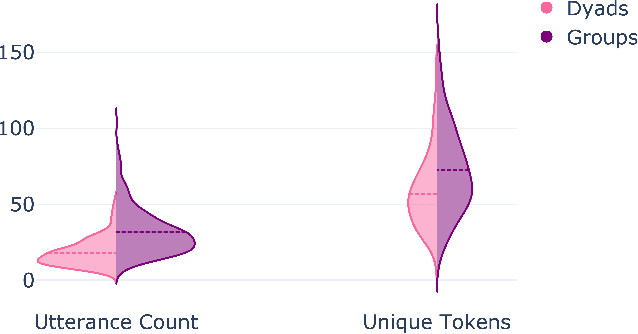
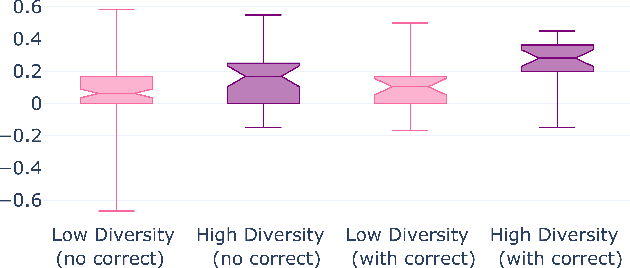
We explore different aspects of cognitive diversity and its effect on the success of group deliberation. To evaluate this, we use 500 dialogues from small, online groups discussing the Wason Card Selection task - the DeliData corpus. Leveraging the corpus, we perform quantitative analysis evaluating three different measures of cognitive diversity. First, we analyse the effect of group size as a proxy measure for diversity. Second, we evaluate the effect of the size of the initial idea pool. Finally, we look into the content of the discussion by analysing discussed solutions, discussion patterns, and how conversational probing can improve those characteristics. Despite the reputation of groups for compounding bias, we show that small groups can, through dialogue, overcome intuitive biases and improve individual decision-making. Across a large sample and different operationalisations, we consistently find that greater cognitive diversity is associated with more successful group deliberation. Code and data used for the analysis are available in the anonymised repository: https://anonymous.4open.science/ r/cogsci24-FD6D
Opening up Minds with Argumentative Dialogues
Jan 16, 2023
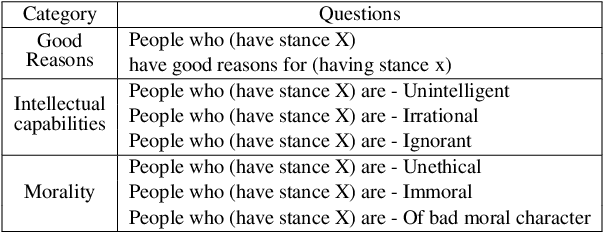

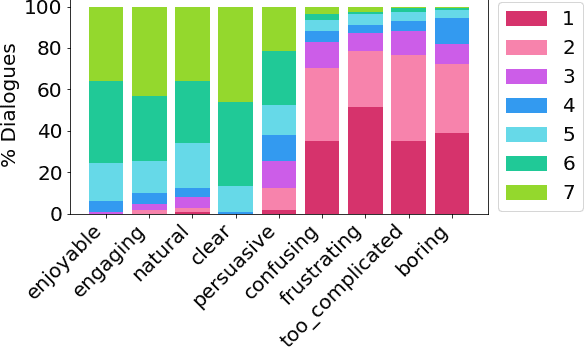
Recent research on argumentative dialogues has focused on persuading people to take some action, changing their stance on the topic of discussion, or winning debates. In this work, we focus on argumentative dialogues that aim to open up (rather than change) people's minds to help them become more understanding to views that are unfamiliar or in opposition to their own convictions. To this end, we present a dataset of 183 argumentative dialogues about 3 controversial topics: veganism, Brexit and COVID-19 vaccination. The dialogues were collected using the Wizard of Oz approach, where wizards leverage a knowledge-base of arguments to converse with participants. Open-mindedness is measured before and after engaging in the dialogue using a questionnaire from the psychology literature, and success of the dialogue is measured as the change in the participant's stance towards those who hold opinions different to theirs. We evaluate two dialogue models: a Wikipedia-based and an argument-based model. We show that while both models perform closely in terms of opening up minds, the argument-based model is significantly better on other dialogue properties such as engagement and clarity.
How to disagree well: Investigating the dispute tactics used on Wikipedia
Dec 16, 2022Disagreements are frequently studied from the perspective of either detecting toxicity or analysing argument structure. We propose a framework of dispute tactics that unifies these two perspectives, as well as other dialogue acts which play a role in resolving disputes, such as asking questions and providing clarification. This framework includes a preferential ordering among rebuttal-type tactics, ranging from ad hominem attacks to refuting the central argument. Using this framework, we annotate 213 disagreements (3,865 utterances) from Wikipedia Talk pages. This allows us to investigate research questions around the tactics used in disagreements; for instance, we provide empirical validation of the approach to disagreement recommended by Wikipedia. We develop models for multilabel prediction of dispute tactics in an utterance, achieving the best performance with a transformer-based label powerset model. Adding an auxiliary task to incorporate the ordering of rebuttal tactics further yields a statistically significant increase. Finally, we show that these annotations can be used to provide useful additional signals to improve performance on the task of predicting escalation.
* Accepted to EMNLP 2022 (Long paper)
What makes you change your mind? An empirical investigation in online group decision-making conversations
Jul 25, 2022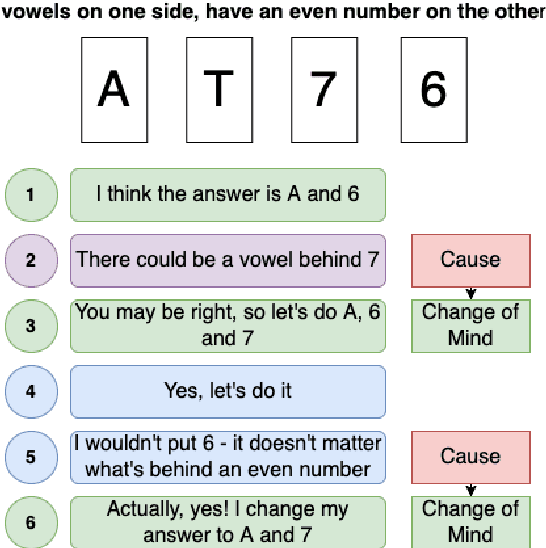
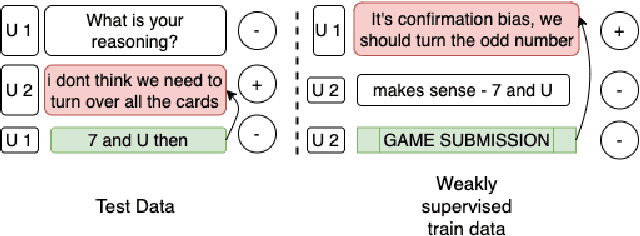
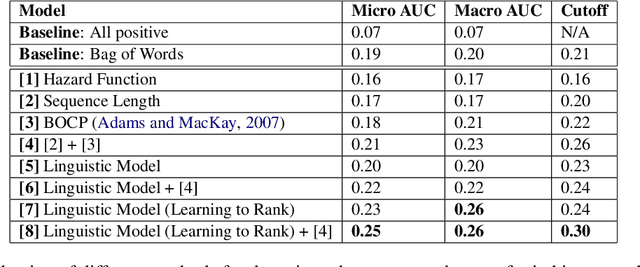
People leverage group discussions to collaborate in order to solve complex tasks, e.g. in project meetings or hiring panels. By doing so, they engage in a variety of conversational strategies where they try to convince each other of the best approach and ultimately reach a decision. In this work, we investigate methods for detecting what makes someone change their mind. To this end, we leverage a recently introduced dataset containing group discussions of people collaborating to solve a task. To find out what makes someone change their mind, we incorporate various techniques such as neural text classification and language-agnostic change point detection. Evaluation of these methods shows that while the task is not trivial, the best way to approach it is using a language-aware model with learning-to-rank training. Finally, we examine the cues that the models develop as indicative of the cause of a change of mind.
DeliData: A dataset for deliberation in multi-party problem solving
Aug 11, 2021



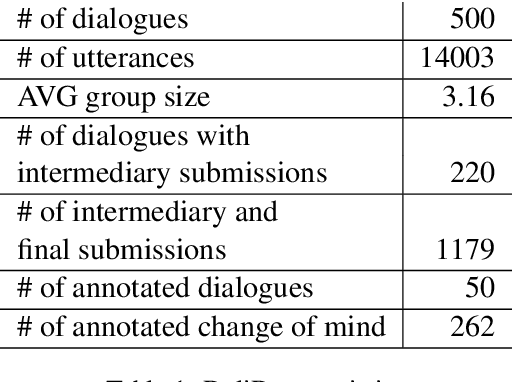
Dialogue systems research is traditionally focused on dialogues between two interlocutors, largely ignoring group conversations. Moreover, most previous research is focused either on task-oriented dialogue (e.g.\ restaurant bookings) or user engagement (chatbots), while research on systems for collaborative dialogues is an under-explored area. To this end, we introduce the first publicly available dataset containing collaborative conversations on solving a cognitive task, consisting of 500 group dialogues and 14k utterances. Furthermore, we propose a novel annotation schema that captures deliberation cues and release 50 dialogues annotated with it. Finally, we demonstrate the usefulness of the annotated data in training classifiers to predict the constructiveness of a conversation. The data collection platform, dataset and annotated corpus are publicly available at https://delibot.xyz