 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue Systems
Mar 06, 2025The proliferation of generative models has presented significant challenges in distinguishing authentic human-authored content from deepfake content. Collaborative human efforts, augmented by AI tools, present a promising solution. In this study, we explore the potential of DeepFakeDeLiBot, a deliberation-enhancing chatbot, to support groups in detecting deepfake text. Our findings reveal that group-based problem-solving significantly improves the accuracy of identifying machine-generated paragraphs compared to individual efforts. While engagement with DeepFakeDeLiBot does not yield substantial performance gains overall, it enhances group dynamics by fostering greater participant engagement, consensus building, and the frequency and diversity of reasoning-based utterances. Additionally, participants with higher perceived effectiveness of group collaboration exhibited performance benefits from DeepFakeDeLiBot. These findings underscore the potential of deliberative chatbots in fostering interactive and productive group dynamics while ensuring accuracy in collaborative deepfake text detection. \textit{Dataset and source code used in this study will be made publicly available upon acceptance of the manuscript.
Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language Models
Dec 15, 2024



Diffusion models have shown promise in text generation but often struggle with generating long, coherent, and contextually accurate text. Token-level diffusion overlooks word-order dependencies and enforces short output windows, while passage-level diffusion struggles with learning robust representation for long-form text. To address these challenges, we propose Segment-Level Diffusion (SLD), a framework that enhances diffusion-based text generation through text segmentation, robust representation training with adversarial and contrastive learning, and improved latent-space guidance. By segmenting long-form outputs into separate latent representations and decoding them with an autoregressive decoder, SLD simplifies diffusion predictions and improves scalability. Experiments on XSum, ROCStories, DialogSum, and DeliData demonstrate that SLD achieves competitive or superior performance in fluency, coherence, and contextual compatibility across automatic and human evaluation metrics comparing with other diffusion and autoregressive baselines. Ablation studies further validate the effectiveness of our segmentation and representation learning strategies.
The effect of diversity on group decision-making
Feb 02, 2024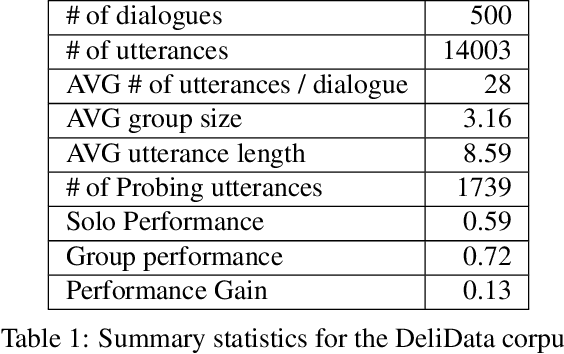
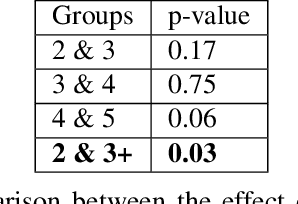
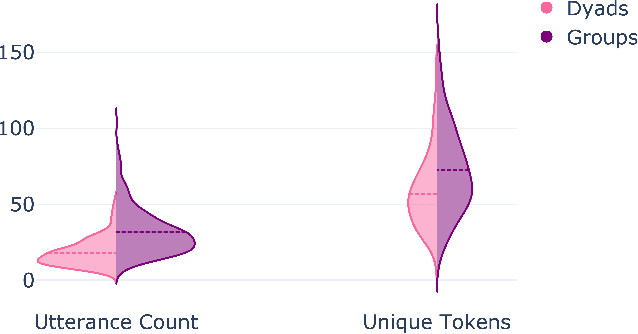
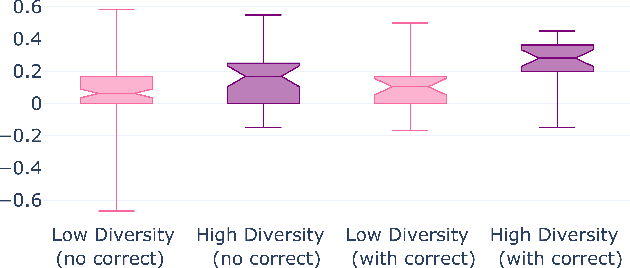
We explore different aspects of cognitive diversity and its effect on the success of group deliberation. To evaluate this, we use 500 dialogues from small, online groups discussing the Wason Card Selection task - the DeliData corpus. Leveraging the corpus, we perform quantitative analysis evaluating three different measures of cognitive diversity. First, we analyse the effect of group size as a proxy measure for diversity. Second, we evaluate the effect of the size of the initial idea pool. Finally, we look into the content of the discussion by analysing discussed solutions, discussion patterns, and how conversational probing can improve those characteristics. Despite the reputation of groups for compounding bias, we show that small groups can, through dialogue, overcome intuitive biases and improve individual decision-making. Across a large sample and different operationalisations, we consistently find that greater cognitive diversity is associated with more successful group deliberation. Code and data used for the analysis are available in the anonymised repository: https://anonymous.4open.science/ r/cogsci24-FD6D
What makes you change your mind? An empirical investigation in online group decision-making conversations
Jul 25, 2022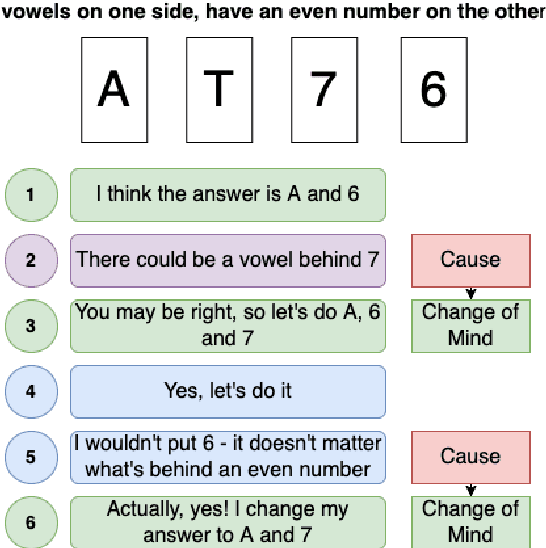
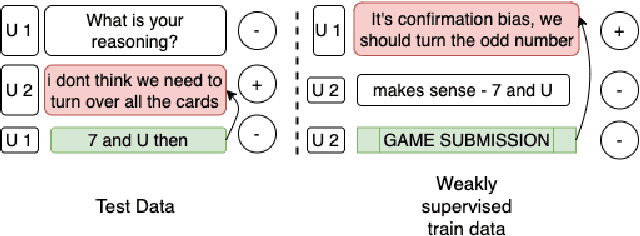
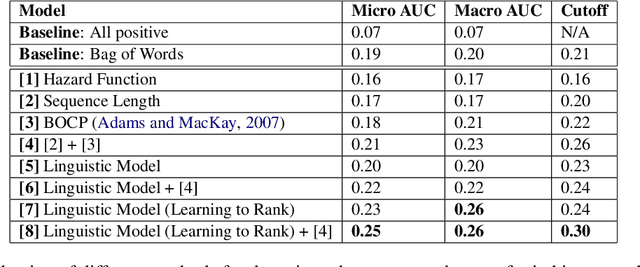
People leverage group discussions to collaborate in order to solve complex tasks, e.g. in project meetings or hiring panels. By doing so, they engage in a variety of conversational strategies where they try to convince each other of the best approach and ultimately reach a decision. In this work, we investigate methods for detecting what makes someone change their mind. To this end, we leverage a recently introduced dataset containing group discussions of people collaborating to solve a task. To find out what makes someone change their mind, we incorporate various techniques such as neural text classification and language-agnostic change point detection. Evaluation of these methods shows that while the task is not trivial, the best way to approach it is using a language-aware model with learning-to-rank training. Finally, we examine the cues that the models develop as indicative of the cause of a change of mind.
Leaf: Multiple-Choice Question Generation
Jan 22, 2022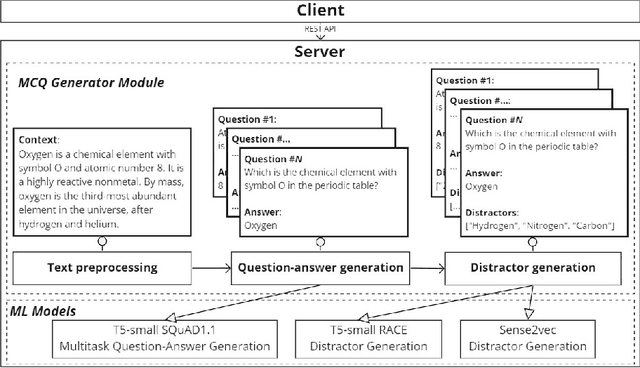
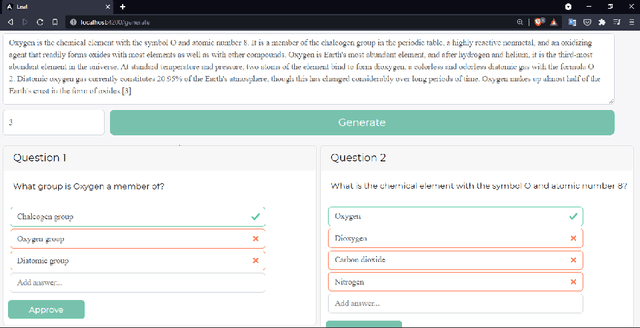
Testing with quiz questions has proven to be an effective way to assess and improve the educational process. However, manually creating quizzes is tedious and time-consuming. To address this challenge, we present Leaf, a system for generating multiple-choice questions from factual text. In addition to being very well suited for the classroom, Leaf could also be used in an industrial setting, e.g., to facilitate onboarding and knowledge sharing, or as a component of chatbots, question answering systems, or Massive Open Online Courses (MOOCs). The code and the demo are available on https://github.com/KristiyanVachev/Leaf-Question-Generation.
Generating Answer Candidates for Quizzes and Answer-Aware Question Generators
Aug 29, 2021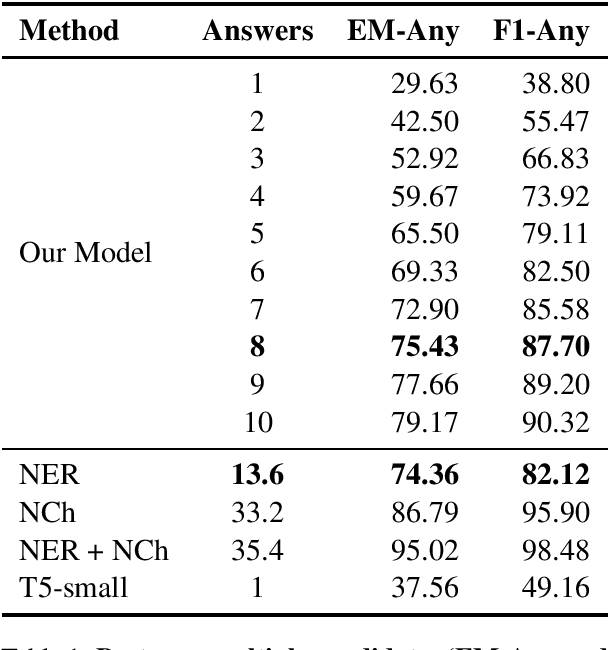
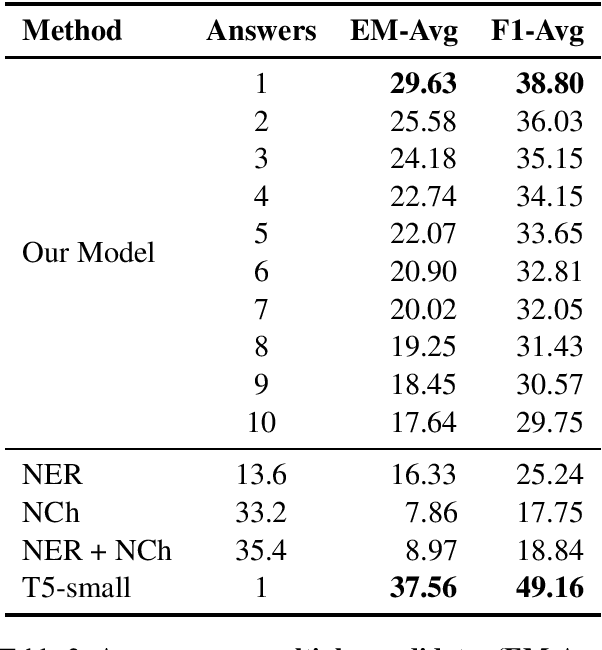

In education, open-ended quiz questions have become an important tool for assessing the knowledge of students. Yet, manually preparing such questions is a tedious task, and thus automatic question generation has been proposed as a possible alternative. So far, the vast majority of research has focused on generating the question text, relying on question answering datasets with readily picked answers, and the problem of how to come up with answer candidates in the first place has been largely ignored. Here, we aim to bridge this gap. In particular, we propose a model that can generate a specified number of answer candidates for a given passage of text, which can then be used by instructors to write questions manually or can be passed as an input to automatic answer-aware question generators. Our experiments show that our proposed answer candidate generation model outperforms several baselines.
* answer generation, question generation, answer-aware question generation, quiz questions, question answering
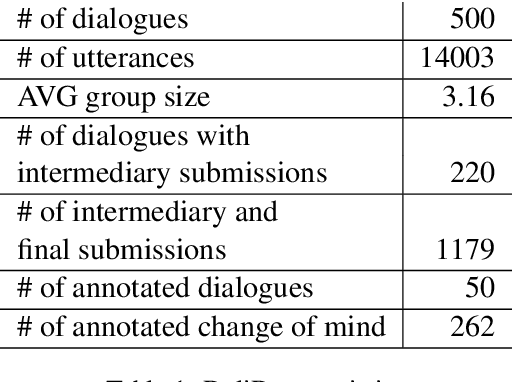
DeliData: A dataset for deliberation in multi-party problem solving
Aug 11, 2021



Dialogue systems research is traditionally focused on dialogues between two interlocutors, largely ignoring group conversations. Moreover, most previous research is focused either on task-oriented dialogue (e.g.\ restaurant bookings) or user engagement (chatbots), while research on systems for collaborative dialogues is an under-explored area. To this end, we introduce the first publicly available dataset containing collaborative conversations on solving a cognitive task, consisting of 500 group dialogues and 14k utterances. Furthermore, we propose a novel annotation schema that captures deliberation cues and release 50 dialogues annotated with it. Finally, we demonstrate the usefulness of the annotated data in training classifiers to predict the constructiveness of a conversation. The data collection platform, dataset and annotated corpus are publicly available at https://delibot.xyz
SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020)
Jun 12, 2020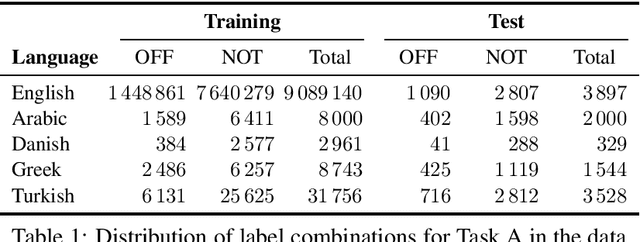
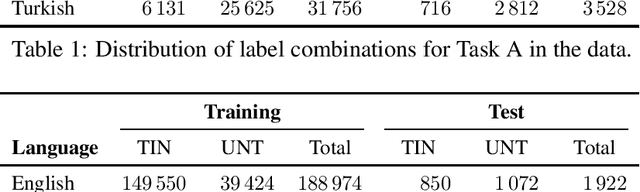
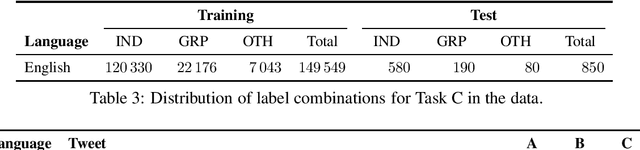

We present the results and main findings of SemEval-2020 Task 12 on Multilingual Offensive Language Identification in Social Media (OffensEval 2020). The task involves three subtasks corresponding to the hierarchical taxonomy of the OLID schema (Zampieri et al., 2019a) from OffensEval 2019. The task featured five languages: English, Arabic, Danish, Greek, and Turkish for Subtask A. In addition, English also featured Subtasks B and C. OffensEval 2020 was one of the most popular tasks at SemEval-2020 attracting a large number of participants across all subtasks and also across all languages. A total of 528 teams signed up to participate in the task, 145 teams submitted systems during the evaluation period, and 70 submitted system description papers.
What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context
May 09, 2020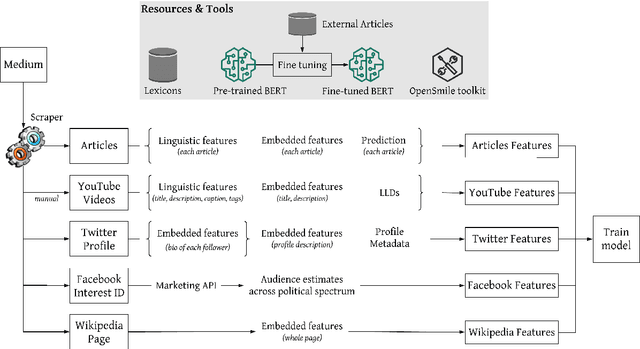
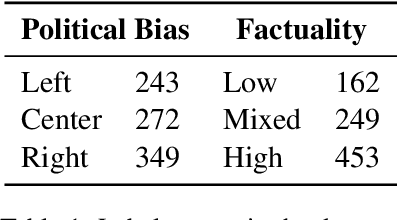
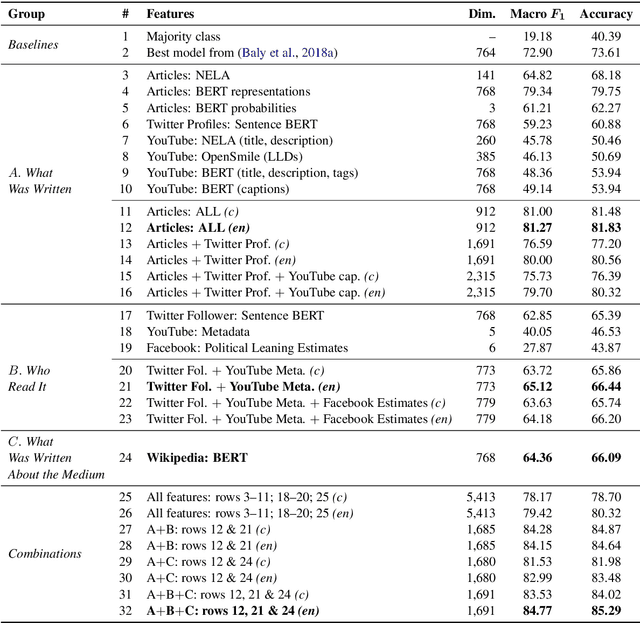
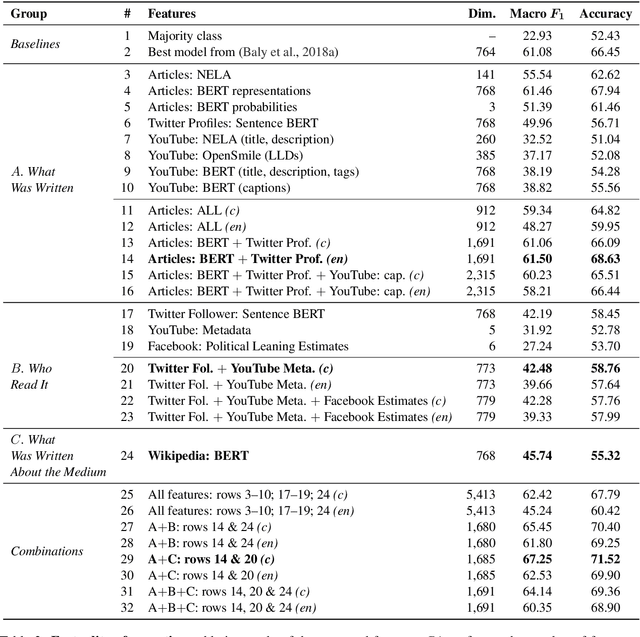
Predicting the political bias and the factuality of reporting of entire news outlets are critical elements of media profiling, which is an understudied but an increasingly important research direction. The present level of proliferation of fake, biased, and propagandistic content online, has made it impossible to fact-check every single suspicious claim, either manually or automatically. Alternatively, we can profile entire news outlets and look for those that are likely to publish fake or biased content. This approach makes it possible to detect likely "fake news" the moment they are published, by simply checking the reliability of their source. From a practical perspective, political bias and factuality of reporting have a linguistic aspect but also a social context. Here, we study the impact of both, namely (i) what was written (i.e., what was published by the target medium, and how it describes itself on Twitter) vs. (ii) who read it (i.e., analyzing the readers of the target medium on Facebook, Twitter, and YouTube). We further study (iii) what was written about the target medium on Wikipedia. The evaluation results show that what was written matters most, and that putting all information sources together yields huge improvements over the current state-of-the-art.
* Factuality of reporting, fact-checking, political ideology, media bias, disinformation, propaganda, social media, news media
A Large-Scale Semi-Supervised Dataset for Offensive Language Identification
Apr 29, 2020
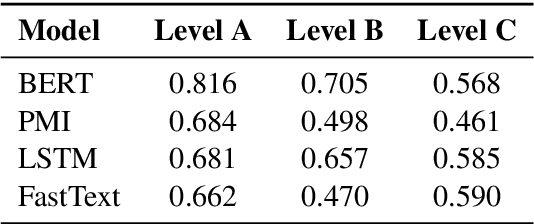

The use of offensive language is a major problem in social media which has led to an abundance of research in detecting content such as hate speech, cyberbulling, and cyber-aggression. There have been several attempts to consolidate and categorize these efforts. Recently, the OLID dataset used at SemEval-2019 proposed a hierarchical three-level annotation taxonomy which addresses different types of offensive language as well as important information such as the target of such content. The categorization provides meaningful and important information for understanding offensive language. However, the OLID dataset is limited in size, especially for some of the low-level categories, which included only a few hundred instances, thus making it challenging to train robust deep learning models. Here, we address this limitation by creating the largest available dataset for this task, SOLID. SOLID contains over nine million English tweets labeled in a semi-supervised manner. We further demonstrate experimentally that using SOLID along with OLID yields improved performance on the OLID test set for two different models, especially for the lower levels of the taxonomy. Finally, we perform analysis of the models' performance on easy and hard examples of offensive language using data annotated in a semi-supervised way.