 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogBias: Measuring and Mitigating Cognitive Bias in Large Language Models
Apr 01, 2026Large Language Models (LLMs) are increasingly deployed in high-stakes decision-making contexts. While prior work has shown that LLMs exhibit cognitive biases behaviorally, whether these biases correspond to identifiable internal representations and can be mitigated through targeted intervention remains an open question. We define LLM cognitive bias as systematic, reproducible deviations from correct answers in tasks with computable ground-truth baselines, and introduce LLM CogBias, a benchmark organized around four families of cognitive biases: Judgment, Information Processing, Social, and Response. We evaluate three LLMs and find that cognitive biases emerge systematically across all four families, with magnitudes and debiasing responses that are strongly family-dependent: prompt-level debiasing substantially reduces Response biases but backfires for Judgment biases. Using linear probes under a contrastive design, we show that these biases are encoded as linearly separable directions in model activation space. Finally, we apply activation steering to modulate biased behavior, achieving 26--32\% reduction in bias score (fraction of biased responses) while preserving downstream capability on 25 benchmarks (Llama: negligible degradation; Qwen: up to $-$19.0pp for Judgment biases). Despite near-orthogonal bias representations across models (mean cosine similarity 0.01), steering reduces bias at similar rates across architectures ($r(246)$=.621, $p$<.001), suggesting shared functional organization.
SynSym: A Synthetic Data Generation Framework for Psychiatric Symptom Identification
Mar 23, 2026Psychiatric symptom identification on social media aims to infer fine-grained mental health symptoms from user-generated posts, allowing a detailed understanding of users' mental states. However, the construction of large-scale symptom-level datasets remains challenging due to the resource-intensive nature of expert labeling and the lack of standardized annotation guidelines, which in turn limits the generalizability of models to identify diverse symptom expressions from user-generated text. To address these issues, we propose SynSym, a synthetic data generation framework for constructing generalizable datasets for symptom identification. Leveraging large language models (LLMs), SynSym constructs high-quality training samples by (1) expanding each symptom into sub-concepts to enhance the diversity of generated expressions, (2) producing synthetic expressions that reflect psychiatric symptoms in diverse linguistic styles, and (3) composing realistic multi-symptom expressions, informed by clinical co-occurrence patterns. We validate SynSym on three benchmark datasets covering different styles of depressive symptom expression. Experimental results demonstrate that models trained solely on the synthetic data generated by SynSym perform comparably to those trained on real data, and benefit further from additional fine-tuning with real data. These findings underscore the potential of synthetic data as an alternative resource to real-world annotations in psychiatric symptom modeling, and SynSym serves as a practical framework for generating clinically relevant and realistic symptom expressions.
Understanding Moral Reasoning Trajectories in Large Language Models: Toward Probing-Based Explainability
Mar 16, 2026Large language models (LLMs) increasingly participate in morally sensitive decision-making, yet how they organize ethical frameworks across reasoning steps remains underexplored. We introduce \textit{moral reasoning trajectories}, sequences of ethical framework invocations across intermediate reasoning steps, and analyze their dynamics across six models and three benchmarks. We find that moral reasoning involves systematic multi-framework deliberation: 55.4--57.7\% of consecutive steps involve framework switches, and only 16.4--17.8\% of trajectories remain framework-consistent. Unstable trajectories remain 1.29$\times$ more susceptible to persuasive attacks ($p=0.015$). At the representation level, linear probes localize framework-specific encoding to model-specific layers (layer 63/81 for Llama-3.3-70B; layer 17/81 for Qwen2.5-72B), achieving 13.8--22.6\% lower KL divergence than the training-set prior baseline. Lightweight activation steering modulates framework integration patterns (6.7--8.9\% drift reduction) and amplifies the stability--accuracy relationship. We further propose a Moral Representation Consistency (MRC) metric that correlates strongly ($r=0.715$, $p<0.0001$) with LLM coherence ratings, whose underlying framework attributions are validated by human annotators (mean cosine similarity $= 0.859$).
LLMs Can Infer Political Alignment from Online Conversations
Mar 11, 2026Due to the correlational structure in our traits such as identities, cultures, and political attitudes, seemingly innocuous preferences such as following a band or using a specific slang, can reveal private traits. This possibility, especially when combined with massive, public social data and advanced computational methods, poses a fundamental privacy risk. Given our increasing data exposure online and the rapid advancement of AI are increasing the misuse potential of such risk, it is therefore critical to understand capacity of large language models (LLMs) to exploit it. Here, using online discussions on Debate.org and Reddit, we show that LLMs can reliably infer hidden political alignment, significantly outperforming traditional machine learning models. Prediction accuracy further improves as we aggregate multiple text-level inferences into a user-level prediction, and as we use more politics-adjacent domains. We demonstrate that LLMs leverage the words that can be highly predictive of political alignment while not being explicitly political. Our findings underscore the capacity and risks of LLMs for exploiting socio-cultural correlates.
Vulnerability of LLMs' Belief Systems? LLMs Belief Resistance Check Through Strategic Persuasive Conversation Interventions
Jan 20, 2026Large Language Models (LLMs) are increasingly employed in various question-answering tasks. However, recent studies showcase that LLMs are susceptible to persuasion and could adopt counterfactual beliefs. We present a systematic evaluation of LLM susceptibility to persuasion under the Source--Message--Channel--Receiver (SMCR) communication framework. Across five mainstream Large Language Models (LLMs) and three domains (factual knowledge, medical QA, and social bias), we analyze how different persuasive strategies influence belief stability over multiple interaction turns. We further examine whether meta-cognition prompting (i.e., eliciting self-reported confidence) affects resistance to persuasion. Results show that smaller models exhibit extreme compliance, with over 80% of belief changes occurring at the first persuasive turn (average end turn of 1.1--1.4). Contrary to expectations, meta-cognition prompting increases vulnerability by accelerating belief erosion rather than enhancing robustness. Finally, we evaluate adversarial fine-tuning as a defense. While GPT-4o-mini achieves near-complete robustness (98.6%) and Mistral~7B improves substantially (35.7% $\rightarrow$ 79.3%), Llama models remain highly susceptible (<14%) even when fine-tuned on their own failure cases. Together, these findings highlight substantial model-dependent limits of current robustness interventions and offer guidance for developing more trustworthy LLMs.
XChoice: Explainable Evaluation of AI-Human Alignment in LLM-based Constrained Choice Decision Making
Jan 16, 2026We present XChoice, an explainable framework for evaluating AI-human alignment in constrained decision making. Moving beyond outcome agreement such as accuracy and F1 score, XChoice fits a mechanism-based decision model to human data and LLM-generated decisions, recovering interpretable parameters that capture the relative importance of decision factors, constraint sensitivity, and implied trade-offs. Alignment is assessed by comparing these parameter vectors across models, options, and subgroups. We demonstrate XChoice on Americans' daily time allocation using the American Time Use Survey (ATUS) as human ground truth, revealing heterogeneous alignment across models and activities and salient misalignment concentrated in Black and married groups. We further validate robustness of XChoice via an invariance analysis and evaluate targeted mitigation with a retrieval augmented generation (RAG) intervention. Overall, XChoice provides mechanism-based metrics that diagnose misalignment and support informed improvements beyond surface outcome matching.
PrivacyBench: A Conversational Benchmark for Evaluating Privacy in Personalized AI
Dec 31, 2025Personalized AI agents rely on access to a user's digital footprint, which often includes sensitive data from private emails, chats and purchase histories. Yet this access creates a fundamental societal and privacy risk: systems lacking social-context awareness can unintentionally expose user secrets, threatening digital well-being. We introduce PrivacyBench, a benchmark with socially grounded datasets containing embedded secrets and a multi-turn conversational evaluation to measure secret preservation. Testing Retrieval-Augmented Generation (RAG) assistants reveals that they leak secrets in up to 26.56% of interactions. A privacy-aware prompt lowers leakage to 5.12%, yet this measure offers only partial mitigation. The retrieval mechanism continues to access sensitive data indiscriminately, which shifts the entire burden of privacy preservation onto the generator. This creates a single point of failure, rendering current architectures unsafe for wide-scale deployment. Our findings underscore the urgent need for structural, privacy-by-design safeguards to ensure an ethical and inclusive web for everyone.
Enhancing Regional Airbnb Trend Forecasting Using LLM-Based Embeddings of Accessibility and Human Mobility
Nov 18, 2025The expansion of short-term rental platforms, such as Airbnb, has significantly disrupted local housing markets, often leading to increased rental prices and housing affordability issues. Accurately forecasting regional Airbnb market trends can thus offer critical insights for policymakers and urban planners aiming to mitigate these impacts. This study proposes a novel time-series forecasting framework to predict three key Airbnb indicators -- Revenue, Reservation Days, and Number of Reservations -- at the regional level. Using a sliding-window approach, the model forecasts trends 1 to 3 months ahead. Unlike prior studies that focus on individual listings at fixed time points, our approach constructs regional representations by integrating listing features with external contextual factors such as urban accessibility and human mobility. We convert structured tabular data into prompt-based inputs for a Large Language Model (LLM), producing comprehensive regional embeddings. These embeddings are then fed into advanced time-series models (RNN, LSTM, Transformer) to better capture complex spatio-temporal dynamics. Experiments on Seoul's Airbnb dataset show that our method reduces both average RMSE and MAE by approximately 48% compared to conventional baselines, including traditional statistical and machine learning models. Our framework not only improves forecasting accuracy but also offers practical insights for detecting oversupplied regions and supporting data-driven urban policy decisions.
Multiple Areal Feature Aware Transportation Demand Prediction
Aug 23, 2024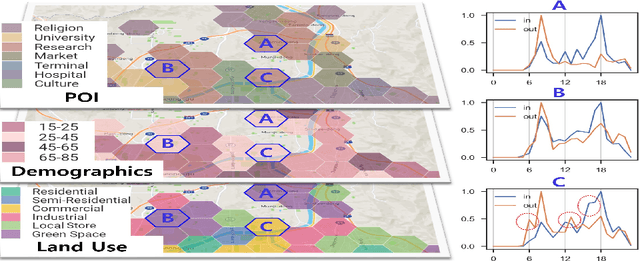
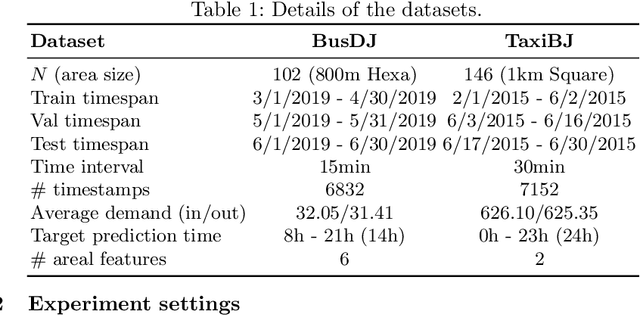
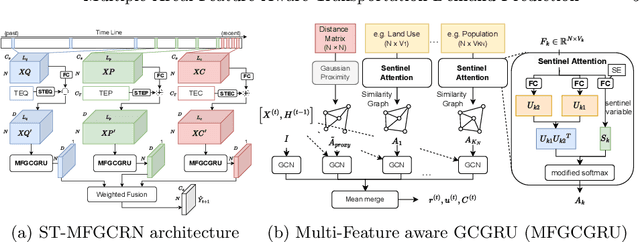
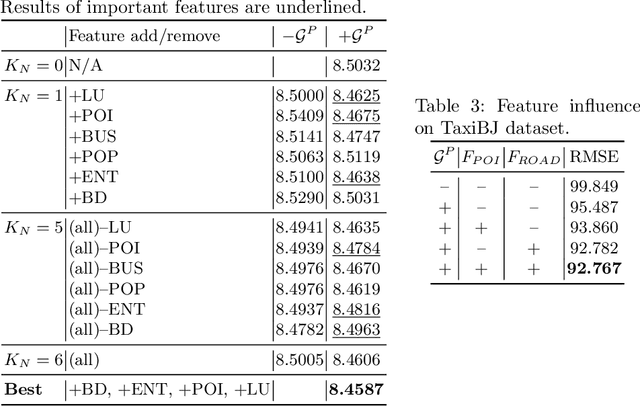
A reliable short-term transportation demand prediction supports the authorities in improving the capability of systems by optimizing schedules, adjusting fleet sizes, and generating new transit networks. A handful of research efforts incorporate one or a few areal features while learning spatio-temporal correlation, to capture similar demand patterns between similar areas. However, urban characteristics are polymorphic, and they need to be understood by multiple areal features such as land use, sociodemographics, and place-of-interest (POI) distribution. In this paper, we propose a novel spatio-temporal multi-feature-aware graph convolutional recurrent network (ST-MFGCRN) that fuses multiple areal features during spatio-temproal understanding. Inside ST-MFGCRN, we devise sentinel attention to calculate the areal similarity matrix by allowing each area to take partial attention if the feature is not useful. We evaluate the proposed model on two real-world transportation datasets, one with our constructed BusDJ dataset and one with benchmark TaxiBJ. Results show that our model outperforms the state-of-the-art baselines up to 7\% on BusDJ and 8\% on TaxiBJ dataset.
Spatio-Temporal Road Traffic Prediction using Real-time Regional Knowledge
Aug 23, 2024For traffic prediction in transportation services such as car-sharing and ride-hailing, mid-term road traffic prediction (within a few hours) is considered essential. However, the existing road-level traffic prediction has mainly studied how significantly micro traffic events propagate to the adjacent roads in terms of short-term prediction. On the other hand, recent attempts have been made to incorporate regional knowledge such as POIs, road characteristics, and real-time social events to help traffic prediction. However, these studies lack in understandings of different modalities of road-level and region-level spatio-temporal correlations and how to combine such knowledge. This paper proposes a novel method that embeds real-time region-level knowledge using POIs, satellite images, and real-time LTE access traces via a regional spatio-temporal module that consists of dynamic convolution and temporal attention, and conducts bipartite spatial transform attention to convert into road-level knowledge. Then the model ingests this embedded knowledge into a road-level attention-based prediction model. Experimental results on real-world road traffic prediction show that our model outperforms the baselines.