 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural embedding of beliefs reveals the role of relative dissonance in human decision-making
Aug 13, 2024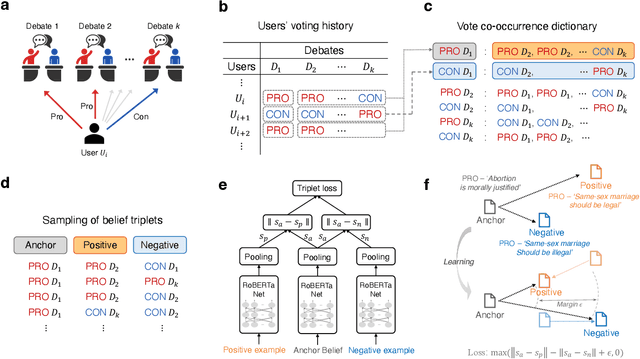
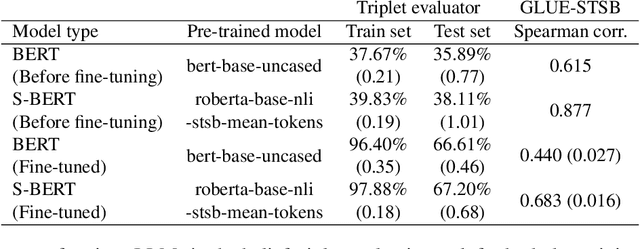
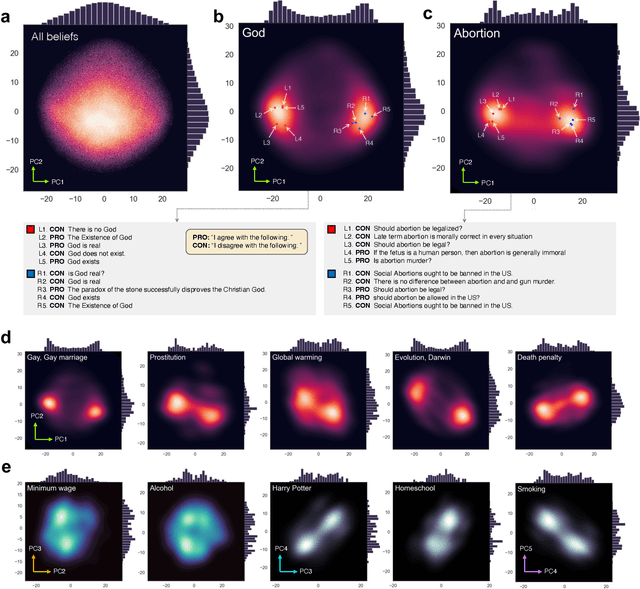
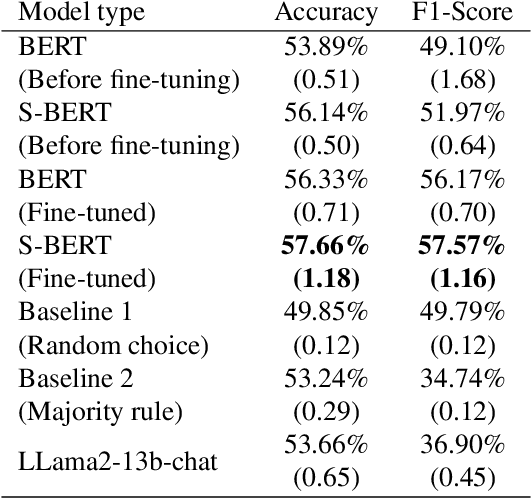
Beliefs serve as the foundation for human cognition and decision-making. They guide individuals in deriving meaning from their lives, shaping their behaviors, and forming social connections. Therefore, a model that encapsulates beliefs and their interrelationships is crucial for quantitatively studying the influence of beliefs on our actions. Despite its importance, research on the interplay between human beliefs has often been limited to a small set of beliefs pertaining to specific issues, with a heavy reliance on surveys or experiments. Here, we propose a method for extracting nuanced relations between thousands of beliefs by leveraging large-scale user participation data from an online debate platform and mapping these beliefs to an embedding space using a fine-tuned large language model (LLM). This belief embedding space effectively encapsulates the interconnectedness of diverse beliefs as well as polarization across various social issues. We discover that the positions within this belief space predict new beliefs of individuals. Furthermore, we find that the relative distance between one's existing beliefs and new beliefs can serve as a quantitative estimate of cognitive dissonance, allowing us to predict new beliefs. Our study highlights how modern LLMs, when combined with collective online records of human beliefs, can offer insights into the fundamental principles that govern human belief formation and decision-making processes.
Benchmarking zero-shot stance detection with FlanT5-XXL: Insights from training data, prompting, and decoding strategies into its near-SoTA performance
Mar 01, 2024
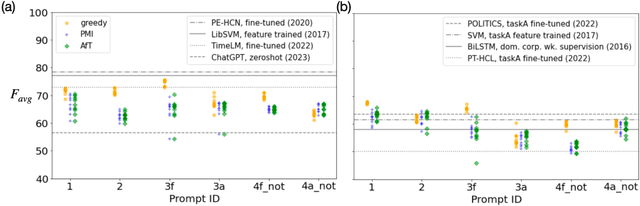
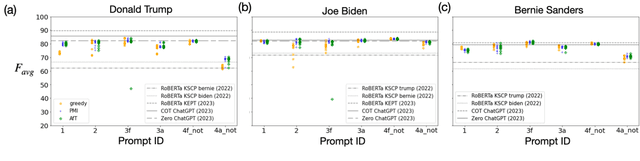
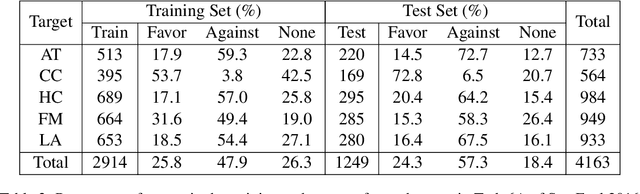
We investigate the performance of LLM-based zero-shot stance detection on tweets. Using FlanT5-XXL, an instruction-tuned open-source LLM, with the SemEval 2016 Tasks 6A, 6B, and P-Stance datasets, we study the performance and its variations under different prompts and decoding strategies, as well as the potential biases of the model. We show that the zero-shot approach can match or outperform state-of-the-art benchmarks, including fine-tuned models. We provide various insights into its performance including the sensitivity to instructions and prompts, the decoding strategies, the perplexity of the prompts, and to negations and oppositions present in prompts. Finally, we ensure that the LLM has not been trained on test datasets, and identify a positivity bias which may partially explain the performance differences across decoding strategie
Can we trust the evaluation on ChatGPT?
Mar 22, 2023ChatGPT, the first large language model (LLM) with mass adoption, has demonstrated remarkable performance in numerous natural language tasks. Despite its evident usefulness, evaluating ChatGPT's performance in diverse problem domains remains challenging due to the closed nature of the model and its continuous updates via Reinforcement Learning from Human Feedback (RLHF). We highlight the issue of data contamination in ChatGPT evaluations, with a case study of the task of stance detection. We discuss the challenge of preventing data contamination and ensuring fair model evaluation in the age of closed and continuously trained models.