 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking zero-shot stance detection with FlanT5-XXL: Insights from training data, prompting, and decoding strategies into its near-SoTA performance
Mar 01, 2024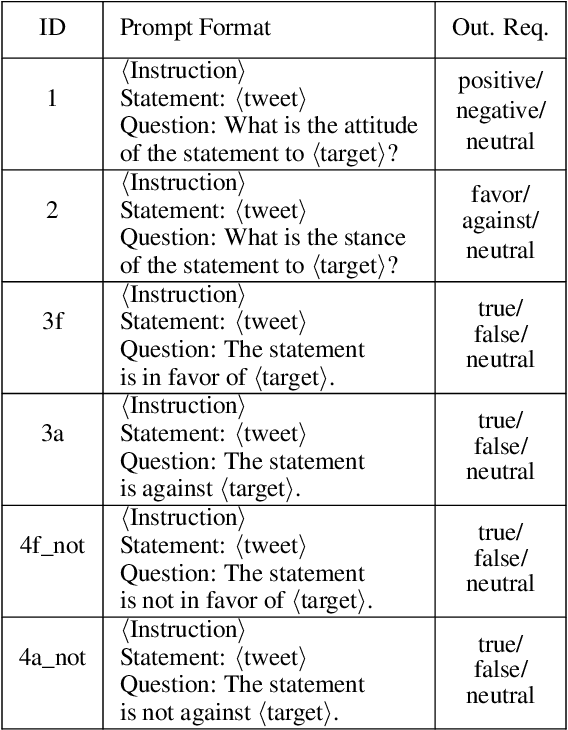
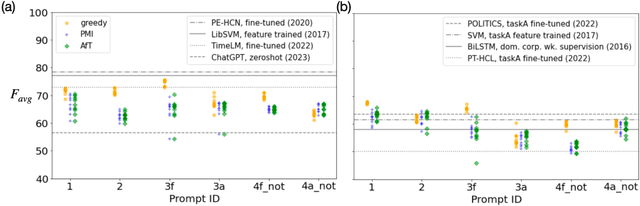
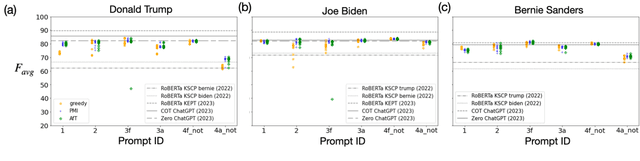
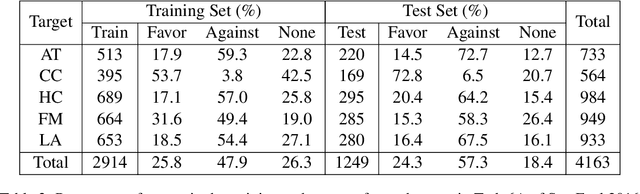
We investigate the performance of LLM-based zero-shot stance detection on tweets. Using FlanT5-XXL, an instruction-tuned open-source LLM, with the SemEval 2016 Tasks 6A, 6B, and P-Stance datasets, we study the performance and its variations under different prompts and decoding strategies, as well as the potential biases of the model. We show that the zero-shot approach can match or outperform state-of-the-art benchmarks, including fine-tuned models. We provide various insights into its performance including the sensitivity to instructions and prompts, the decoding strategies, the perplexity of the prompts, and to negations and oppositions present in prompts. Finally, we ensure that the LLM has not been trained on test datasets, and identify a positivity bias which may partially explain the performance differences across decoding strategie