 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Can Infer Political Alignment from Online Conversations
Mar 11, 2026Due to the correlational structure in our traits such as identities, cultures, and political attitudes, seemingly innocuous preferences such as following a band or using a specific slang, can reveal private traits. This possibility, especially when combined with massive, public social data and advanced computational methods, poses a fundamental privacy risk. Given our increasing data exposure online and the rapid advancement of AI are increasing the misuse potential of such risk, it is therefore critical to understand capacity of large language models (LLMs) to exploit it. Here, using online discussions on Debate.org and Reddit, we show that LLMs can reliably infer hidden political alignment, significantly outperforming traditional machine learning models. Prediction accuracy further improves as we aggregate multiple text-level inferences into a user-level prediction, and as we use more politics-adjacent domains. We demonstrate that LLMs leverage the words that can be highly predictive of political alignment while not being explicitly political. Our findings underscore the capacity and risks of LLMs for exploiting socio-cultural correlates.
Neural embedding of beliefs reveals the role of relative dissonance in human decision-making
Aug 13, 2024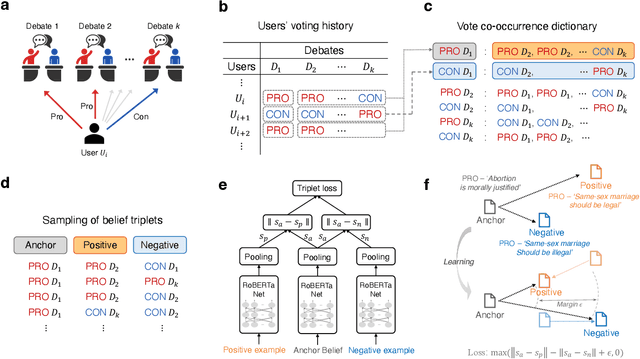
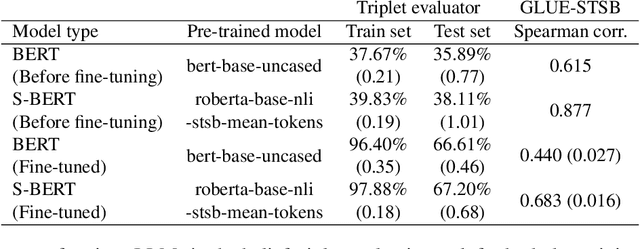
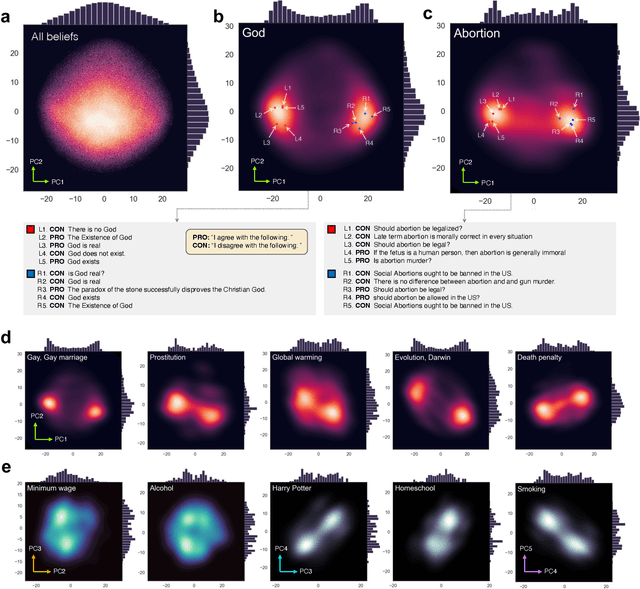
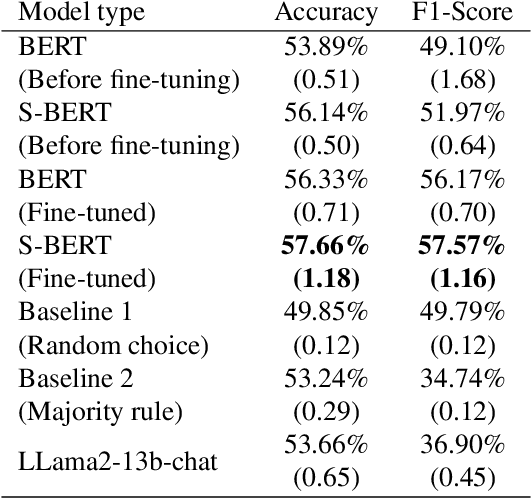
Beliefs serve as the foundation for human cognition and decision-making. They guide individuals in deriving meaning from their lives, shaping their behaviors, and forming social connections. Therefore, a model that encapsulates beliefs and their interrelationships is crucial for quantitatively studying the influence of beliefs on our actions. Despite its importance, research on the interplay between human beliefs has often been limited to a small set of beliefs pertaining to specific issues, with a heavy reliance on surveys or experiments. Here, we propose a method for extracting nuanced relations between thousands of beliefs by leveraging large-scale user participation data from an online debate platform and mapping these beliefs to an embedding space using a fine-tuned large language model (LLM). This belief embedding space effectively encapsulates the interconnectedness of diverse beliefs as well as polarization across various social issues. We discover that the positions within this belief space predict new beliefs of individuals. Furthermore, we find that the relative distance between one's existing beliefs and new beliefs can serve as a quantitative estimate of cognitive dissonance, allowing us to predict new beliefs. Our study highlights how modern LLMs, when combined with collective online records of human beliefs, can offer insights into the fundamental principles that govern human belief formation and decision-making processes.
Benchmarking zero-shot stance detection with FlanT5-XXL: Insights from training data, prompting, and decoding strategies into its near-SoTA performance
Mar 01, 2024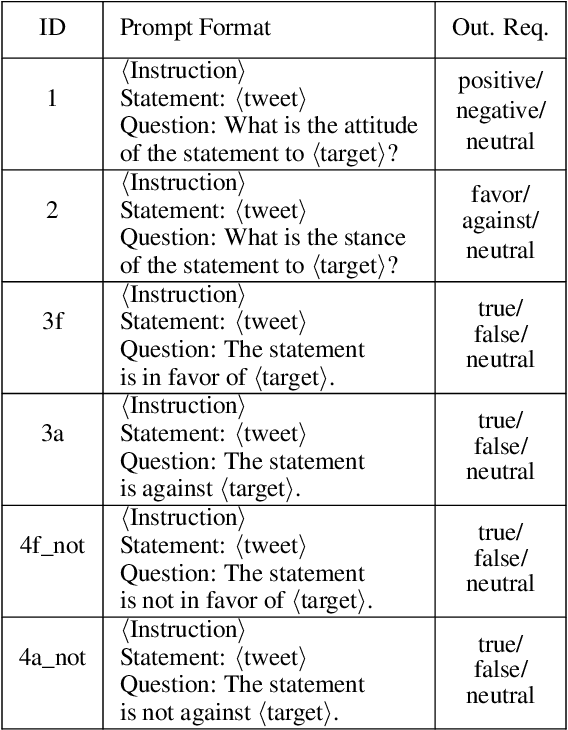
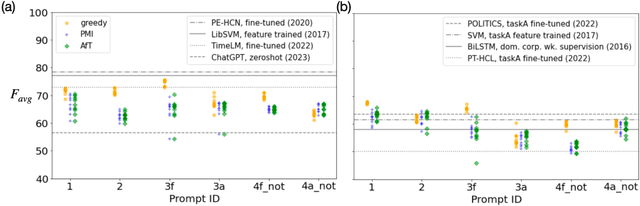
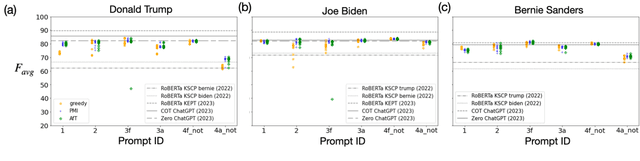
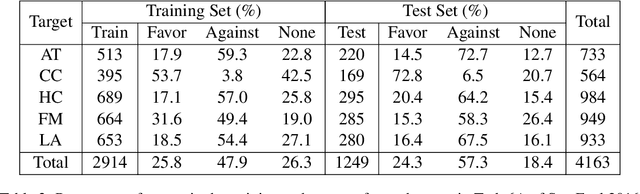
We investigate the performance of LLM-based zero-shot stance detection on tweets. Using FlanT5-XXL, an instruction-tuned open-source LLM, with the SemEval 2016 Tasks 6A, 6B, and P-Stance datasets, we study the performance and its variations under different prompts and decoding strategies, as well as the potential biases of the model. We show that the zero-shot approach can match or outperform state-of-the-art benchmarks, including fine-tuned models. We provide various insights into its performance including the sensitivity to instructions and prompts, the decoding strategies, the perplexity of the prompts, and to negations and oppositions present in prompts. Finally, we ensure that the LLM has not been trained on test datasets, and identify a positivity bias which may partially explain the performance differences across decoding strategie
$\textit{Labor Space}$: A Unifying Representation of the Labor Market via Large Language Models
Nov 20, 2023The labor market is a complex ecosystem comprising diverse, interconnected entities, such as industries, occupations, skills, and firms. Due to the lack of a systematic method to map these heterogeneous entities together, each entity has been analyzed in isolation or only through pairwise relationships, inhibiting comprehensive understanding of the whole ecosystem. Here, we introduce $\textit{Labor Space}$, a vector-space embedding of heterogeneous labor market entities, derived through applying a large language model with fine-tuning. Labor Space exposes the complex relational fabric of various labor market constituents, facilitating coherent integrative analysis of industries, occupations, skills, and firms, while retaining type-specific clustering. We demonstrate its unprecedented analytical capacities, including positioning heterogeneous entities on an economic axes, such as `Manufacturing--Healthcare'. Furthermore, by allowing vector arithmetic of these entities, Labor Space enables the exploration of complex inter-unit relations, and subsequently the estimation of the ramifications of economic shocks on individual units and their ripple effect across the labor market. We posit that Labor Space provides policymakers and business leaders with a comprehensive unifying framework for labor market analysis and simulation, fostering more nuanced and effective strategic decision-making.
Discovering collective narratives shifts in online discussions
Jul 17, 2023



Narrative is a foundation of human cognition and decision making. Because narratives play a crucial role in societal discourses and spread of misinformation and because of the pervasive use of social media, the narrative dynamics on social media can have profound societal impact. Yet, systematic and computational understanding of online narratives faces critical challenge of the scale and dynamics; how can we reliably and automatically extract narratives from massive amount of texts? How do narratives emerge, spread, and die? Here, we propose a systematic narrative discovery framework that fill this gap by combining change point detection, semantic role labeling (SRL), and automatic aggregation of narrative fragments into narrative networks. We evaluate our model with synthetic and empirical data two-Twitter corpora about COVID-19 and 2017 French Election. Results demonstrate that our approach can recover major narrative shifts that correspond to the major events.
Can we trust the evaluation on ChatGPT?
Mar 22, 2023ChatGPT, the first large language model (LLM) with mass adoption, has demonstrated remarkable performance in numerous natural language tasks. Despite its evident usefulness, evaluating ChatGPT's performance in diverse problem domains remains challenging due to the closed nature of the model and its continuous updates via Reinforcement Learning from Human Feedback (RLHF). We highlight the issue of data contamination in ChatGPT evaluations, with a case study of the task of stance detection. We discuss the challenge of preventing data contamination and ensuring fair model evaluation in the age of closed and continuously trained models.
Residual2Vec: Debiasing graph embedding with random graphs
Oct 14, 2021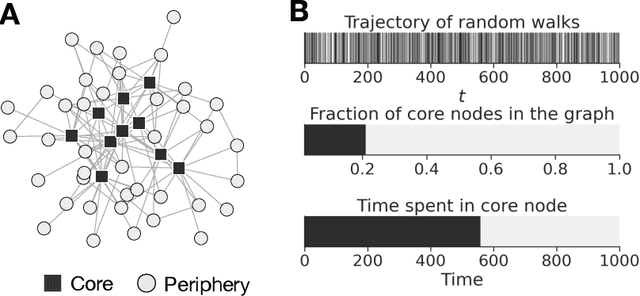

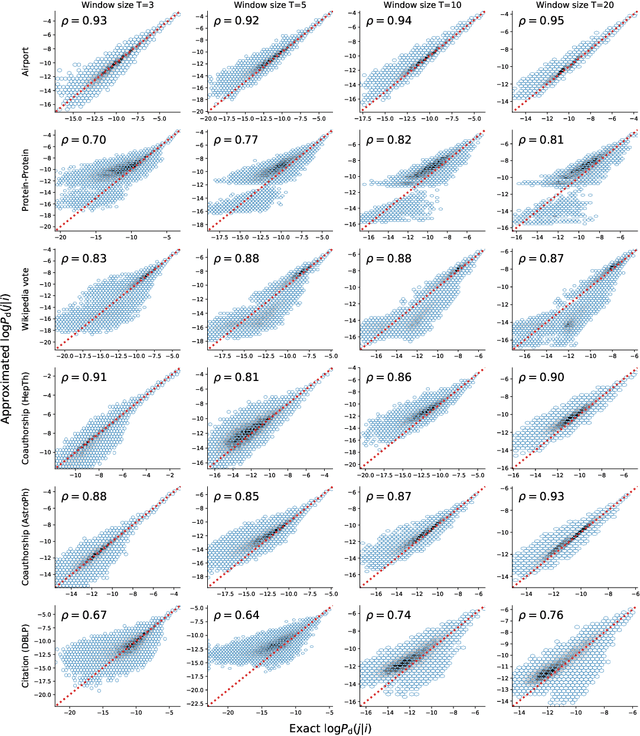
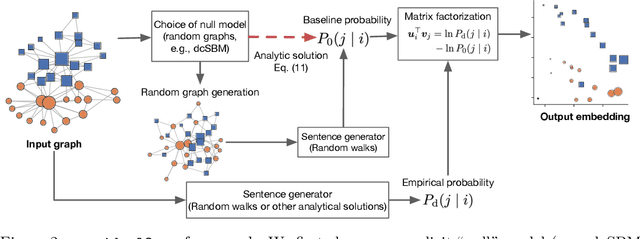
Graph embedding maps a graph into a convenient vector-space representation for graph analysis and machine learning applications. Many graph embedding methods hinge on a sampling of context nodes based on random walks. However, random walks can be a biased sampler due to the structural properties of graphs. Most notably, random walks are biased by the degree of each node, where a node is sampled proportionally to its degree. The implication of such biases has not been clear, particularly in the context of graph representation learning. Here, we investigate the impact of the random walks' bias on graph embedding and propose residual2vec, a general graph embedding method that can debias various structural biases in graphs by using random graphs. We demonstrate that this debiasing not only improves link prediction and clustering performance but also allows us to explicitly model salient structural properties in graph embedding.
* 28 pages, 8 figures, 3 tables
Characterizing Partisan Political Narratives about COVID-19 on Twitter
Mar 11, 2021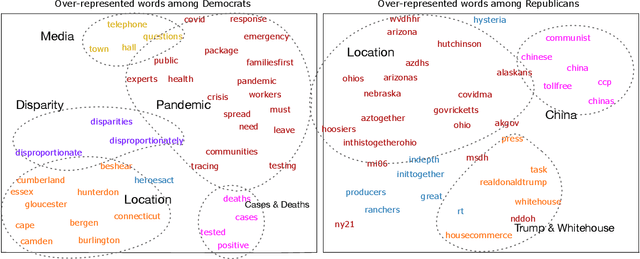

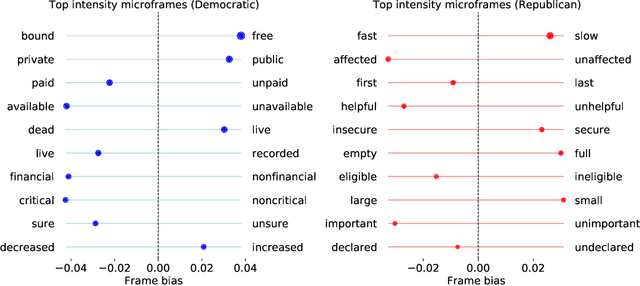
The COVID-19 pandemic is a global crisis that has been testing every society and exposing the critical role of local politics in crisis response. In the United States, there has been a strong partisan divide which resulted in polarization of individual behaviors and divergent policy adoption across regions. Here, to better understand such divide, we characterize and compare the pandemic narratives of the Democratic and Republican politicians on social media using novel computational methods including computational framing analysis and semantic role analysis. By analyzing tweets from the politicians in the U.S., including the president, members of Congress, and state governors, we systematically uncover the contrasting narratives in terms of topics, frames, and agents that shape their narratives. We found that the Democrats' narrative tends to be more concerned with the pandemic as well as financial and social support, while the Republicans discuss more about other political entities such as China. By using contrasting framing and semantic roles, the Democrats emphasize the government's role in responding to the pandemic, and the Republicans emphasize the roles of individuals and support for small businesses. Both parties' narratives also include shout-outs to their followers and blaming of the other party. Our findings concretely expose the gaps in the "elusive consensus" between the two parties. Our methodologies may be applied to computationally study narratives in various domains.
People, Places, and Ties: Landscape of social places and their social network structures
Jan 12, 2021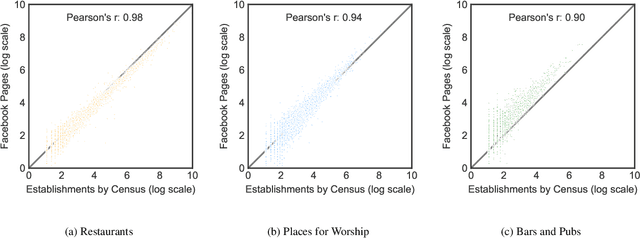
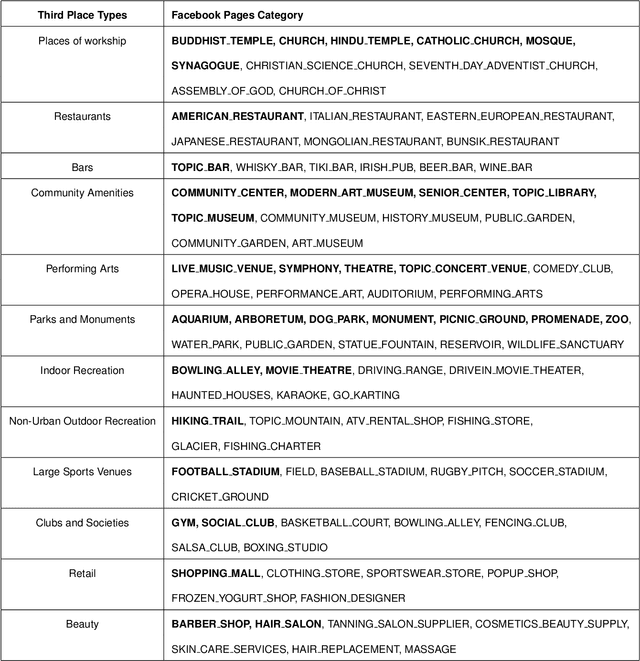
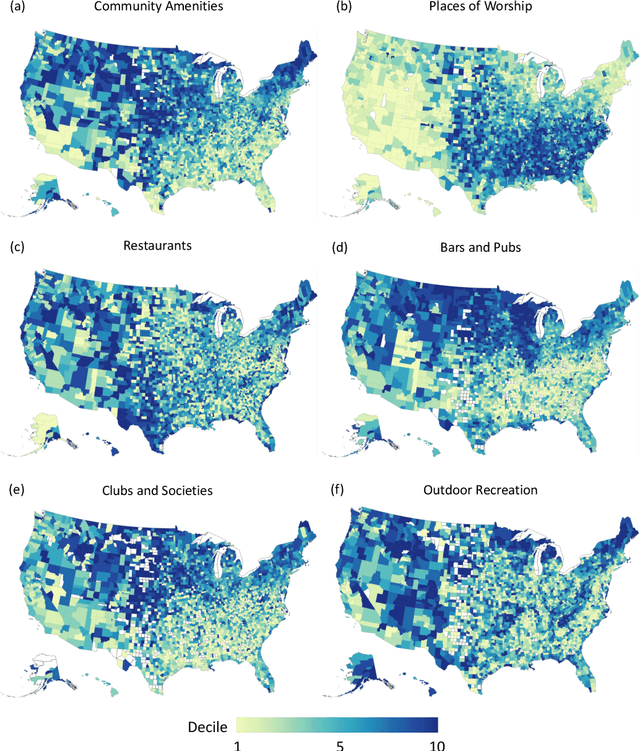
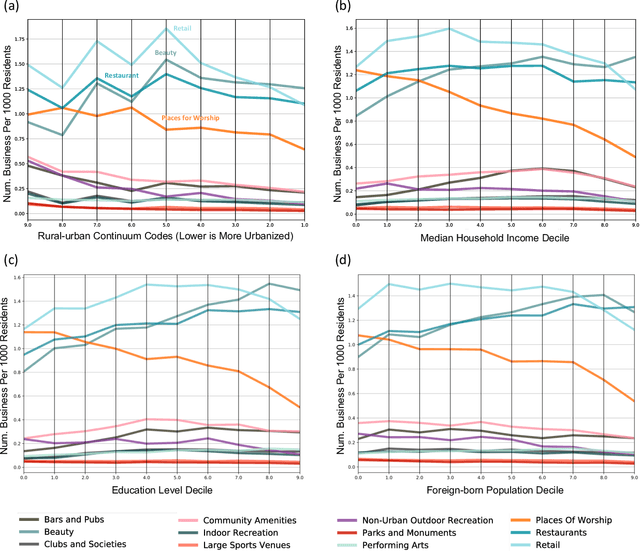
Due to their essential role as places for socialization, "third places" - social places where people casually visit and communicate with friends and neighbors - have been studied by a wide range of fields including network science, sociology, geography, urban planning, and regional studies. However, the lack of a large-scale census on third places kept researchers from systematic investigations. Here we provide a systematic nationwide investigation of third places and their social networks, by using Facebook pages. Our analysis reveals a large degree of geographic heterogeneity in the distribution of the types of third places, which is highly correlated with baseline demographics and county characteristics. Certain types of pages like "Places of Worship" demonstrate a large degree of clustering suggesting community preference or potential complementarities to concentration. We also found that the social networks of different types of social place differ in important ways: The social networks of 'Restaurants' and 'Indoor Recreation' pages are more likely to be tight-knit communities of pre-existing friendships whereas 'Places of Worship' and 'Community Amenities' page categories are more likely to bridge new friendship ties. We believe that this study can serve as an important milestone for future studies on the systematic comparative study of social spaces and their social relationships.
Unsupervised embedding of trajectories captures the latent structure of mobility
Dec 04, 2020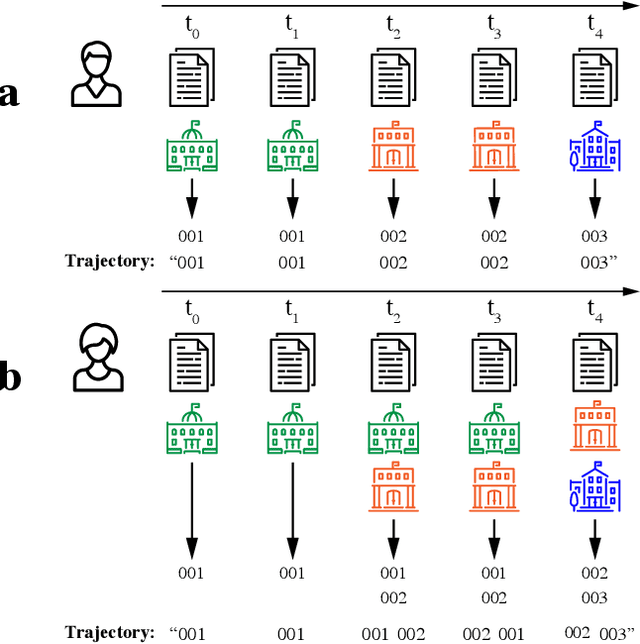
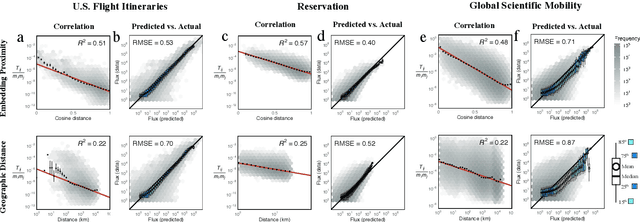
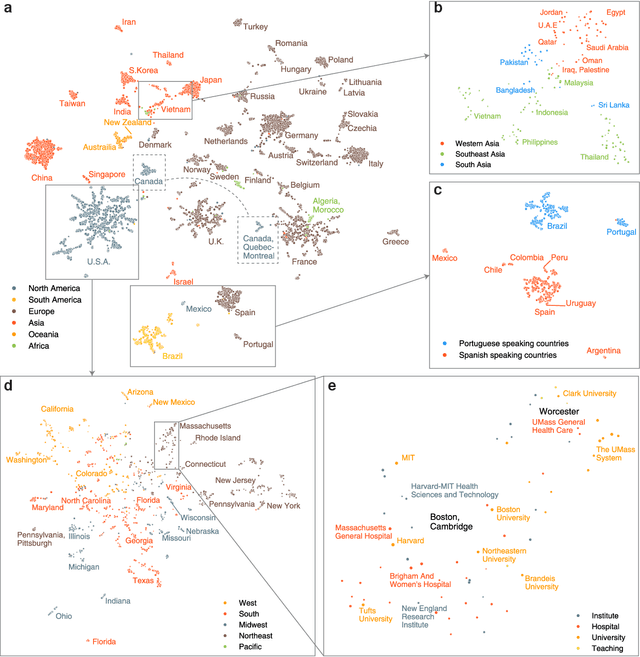
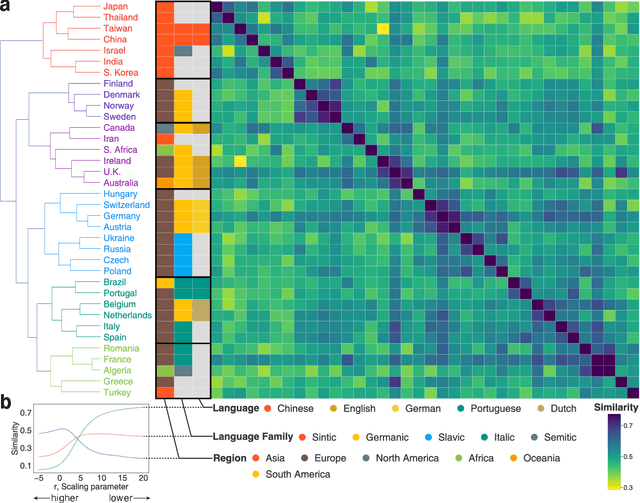
Human mobility and migration drive major societal phenomena such as the growth and evolution of cities, epidemics, economies, and innovation. Historically, human mobility has been strongly constrained by physical separation -- geographic distance. However, geographic distance is becoming less relevant in the increasingly-globalized world in which physical barriers are shrinking while linguistic, cultural, and historical relationships are becoming more important. As understanding mobility is becoming critical for contemporary society, finding frameworks that can capture this complexity is of paramount importance. Here, using three distinct human trajectory datasets, we demonstrate that a neural embedding model can encode nuanced relationships between locations into a vector-space, providing an effective measure of distance that reflects the multi-faceted structure of human mobility. Focusing on the case of scientific mobility, we show that embeddings of scientific organizations uncover cultural and linguistic relations, and even academic prestige, at multiple levels of granularity. Furthermore, the embedding vectors reveal universal relationships between organizational characteristics and their place in the global landscape of scientific mobility. The ability to learn scalable, dense, and meaningful representations of mobility directly from the data can open up a new avenue of studying mobility across domains.