 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs a Picture Worth a Thousand Words? Adaptive Multimodal Fact-Checking with Visual Evidence Necessity
Apr 06, 2026Automated fact-checking is a crucial task not only in journalism but also across web platforms, where it supports a responsible information ecosystem and mitigates the harms of misinformation. While recent research has progressed from text-only to multimodal fact-checking, a prevailing assumption is that incorporating visual evidence universally improves performance. In this work, we challenge this assumption and show that indiscriminate use of multimodal evidence can reduce accuracy. To address this challenge, we propose AMuFC, a multimodal fact-checking framework that employs two collaborative agents with distinct roles for the adaptive use of visual evidence: An Analyzer determines whether visual evidence is necessary for claim verification, and a Verifier predicts claim veracity conditioned on both the retrieved evidence and the Analyzer's assessment. Experimental results on three datasets show that incorporating the Analyzer's assessment of visual evidence necessity into the Verifier's prediction yields substantial improvements in verification performance. In addition to all code, we release WebFC, a newly constructed dataset for evaluating fact-checking modules in a more realistic scenario, available at https://github.com/ssu-humane/AMuFC.
VILLAIN at AVerImaTeC: Verifying Image-Text Claims via Multi-Agent Collaboration
Feb 04, 2026This paper describes VILLAIN, a multimodal fact-checking system that verifies image-text claims through prompt-based multi-agent collaboration. For the AVerImaTeC shared task, VILLAIN employs vision-language model agents across multiple stages of fact-checking. Textual and visual evidence is retrieved from the knowledge store enriched through additional web collection. To identify key information and address inconsistencies among evidence items, modality-specific and cross-modal agents generate analysis reports. In the subsequent stage, question-answer pairs are produced based on these reports. Finally, the Verdict Prediction agent produces the verification outcome based on the image-text claim and the generated question-answer pairs. Our system ranked first on the leaderboard across all evaluation metrics. The source code is publicly available at https://github.com/ssu-humane/VILLAIN.
Hypothetical Documents or Knowledge Leakage? Rethinking LLM-based Query Expansion
Apr 19, 2025



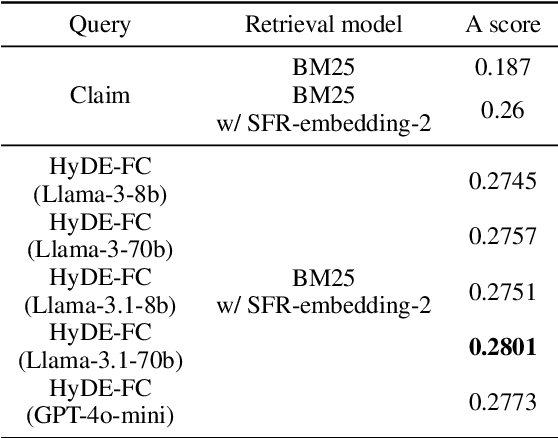
Query expansion methods powered by large language models (LLMs) have demonstrated effectiveness in zero-shot retrieval tasks. These methods assume that LLMs can generate hypothetical documents that, when incorporated into a query vector, enhance the retrieval of real evidence. However, we challenge this assumption by investigating whether knowledge leakage in benchmarks contributes to the observed performance gains. Using fact verification as a testbed, we analyzed whether the generated documents contained information entailed by ground truth evidence and assessed their impact on performance. Our findings indicate that performance improvements occurred consistently only for claims whose generated documents included sentences entailed by ground truth evidence. This suggests that knowledge leakage may be present in these benchmarks, inflating the perceived performance of LLM-based query expansion methods, particularly in real-world scenarios that require retrieving niche or novel knowledge.
HerO at AVeriTeC: The Herd of Open Large Language Models for Verifying Real-World Claims
Oct 16, 2024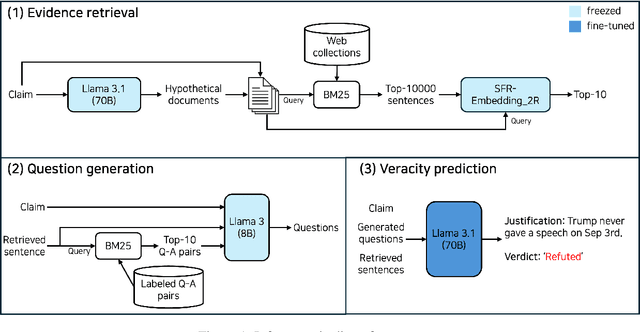


To tackle the AVeriTeC shared task hosted by the FEVER-24, we introduce a system that only employs publicly available large language models (LLMs) for each step of automated fact-checking, dubbed the Herd of Open LLMs for verifying real-world claims (HerO). HerO employs multiple LLMs for each step of automated fact-checking. For evidence retrieval, a language model is used to enhance a query by generating hypothetical fact-checking documents. We prompt pretrained and fine-tuned LLMs for question generation and veracity prediction by crafting prompts with retrieved in-context samples. HerO achieved 2nd place on the leaderboard with the AVeriTeC score of 0.57, suggesting the potential of open LLMs for verifying real-world claims. For future research, we make our code publicly available at https://github.com/ssu-humane/HerO.
ChatGPT Rates Natural Language Explanation Quality Like Humans: But on Which Scales?
Mar 26, 2024



As AI becomes more integral in our lives, the need for transparency and responsibility grows. While natural language explanations (NLEs) are vital for clarifying the reasoning behind AI decisions, evaluating them through human judgments is complex and resource-intensive due to subjectivity and the need for fine-grained ratings. This study explores the alignment between ChatGPT and human assessments across multiple scales (i.e., binary, ternary, and 7-Likert scale). We sample 300 data instances from three NLE datasets and collect 900 human annotations for both informativeness and clarity scores as the text quality measurement. We further conduct paired comparison experiments under different ranges of subjectivity scores, where the baseline comes from 8,346 human annotations. Our results show that ChatGPT aligns better with humans in more coarse-grained scales. Also, paired comparisons and dynamic prompting (i.e., providing semantically similar examples in the prompt) improve the alignment. This research advances our understanding of large language models' capabilities to assess the text explanation quality in different configurations for responsible AI development.
Understanding News Thumbnail Representativeness by Counterfactual Text-Guided Contrastive Language-Image Pretraining
Feb 21, 2024This paper delves into the critical challenge of understanding the representativeness of news thumbnail images, which often serve as the first visual engagement for readers when an article is disseminated on social media. We focus on whether a news image represents the main subject discussed in the news text. To serve the challenge, we introduce NewsTT, a manually annotated dataset of news thumbnail image and text pairs. We found that pretrained vision and language models, such as CLIP and BLIP-2, struggle with this task. Since news subjects frequently involve named entities or proper nouns, a pretrained model could not have the ability to match its visual and textual appearances. To fill the gap, we propose CFT-CLIP, a counterfactual text-guided contrastive language-image pretraining framework. We hypothesize that learning to contrast news text with its counterfactual, of which named entities are replaced, can enhance the cross-modal matching ability in the target task. Evaluation experiments using NewsTT show that CFT-CLIP outperforms the pretrained models, such as CLIP and BLIP-2. Our code and data will be made accessible to the public after the paper is accepted.
K-HATERS: A Hate Speech Detection Corpus in Korean with Target-Specific Ratings
Oct 24, 2023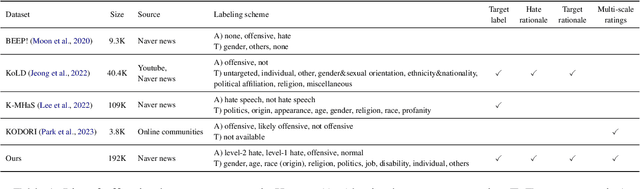


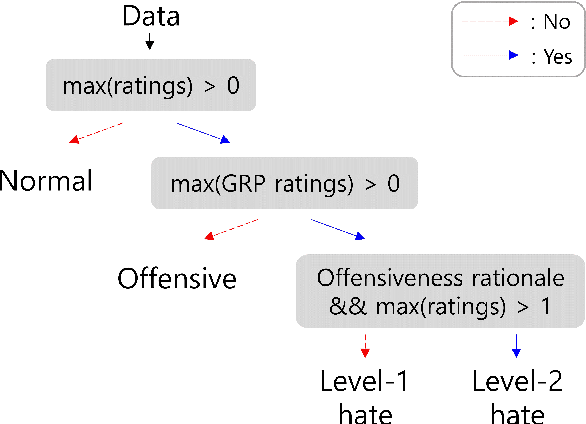
Numerous datasets have been proposed to combat the spread of online hate. Despite these efforts, a majority of these resources are English-centric, primarily focusing on overt forms of hate. This research gap calls for developing high-quality corpora in diverse languages that also encapsulate more subtle hate expressions. This study introduces K-HATERS, a new corpus for hate speech detection in Korean, comprising approximately 192K news comments with target-specific offensiveness ratings. This resource is the largest offensive language corpus in Korean and is the first to offer target-specific ratings on a three-point Likert scale, enabling the detection of hate expressions in Korean across varying degrees of offensiveness. We conduct experiments showing the effectiveness of the proposed corpus, including a comparison with existing datasets. Additionally, to address potential noise and bias in human annotations, we explore a novel idea of adopting the Cognitive Reflection Test, which is widely used in social science for assessing an individual's cognitive ability, as a proxy of labeling quality. Findings indicate that annotations from individuals with the lowest test scores tend to yield detection models that make biased predictions toward specific target groups and are less accurate. This study contributes to the NLP research on hate speech detection and resource construction. The code and dataset can be accessed at https://github.com/ssu-humane/K-HATERS.
Detecting Contextomized Quotes in News Headlines by Contrastive Learning
Feb 09, 2023



Quotes are critical for establishing credibility in news articles. A direct quote enclosed in quotation marks has a strong visual appeal and is a sign of a reliable citation. Unfortunately, this journalistic practice is not strictly followed, and a quote in the headline is often "contextomized." Such a quote uses words out of context in a way that alters the speaker's intention so that there is no semantically matching quote in the body text. We present QuoteCSE, a contrastive learning framework that represents the embedding of news quotes based on domain-driven positive and negative samples to identify such an editorial strategy. The dataset and code are available at https://github.com/ssu-humane/contextomized-quote-contrastive.
How does fake news use a thumbnail? CLIP-based Multimodal Detection on the Unrepresentative News Image
Apr 27, 2022
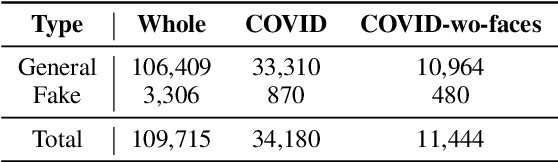
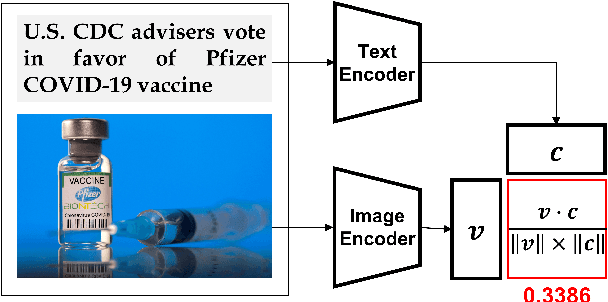
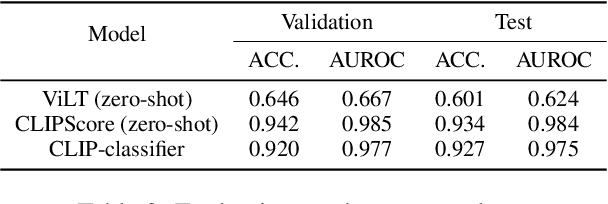
This study investigates how fake news uses a thumbnail for a news article with a focus on whether a news article's thumbnail represents the news content correctly. A news article shared with an irrelevant thumbnail can mislead readers into having a wrong impression of the issue, especially in social media environments where users are less likely to click the link and consume the entire content. We propose to capture the degree of semantic incongruity in the multimodal relation by using the pretrained CLIP representation. From a source-level analysis, we found that fake news employs a more incongruous image to the main content than general news. Going further, we attempted to detect news articles with image-text incongruity. Evaluation experiments suggest that CLIP-based methods can successfully detect news articles in which the thumbnail is semantically irrelevant to news text. This study contributes to the research by providing a novel view on tackling online fake news and misinformation. Code and datasets are available at https://github.com/ssu-humane/fake-news-thumbnail.
Who Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Apr 20, 2022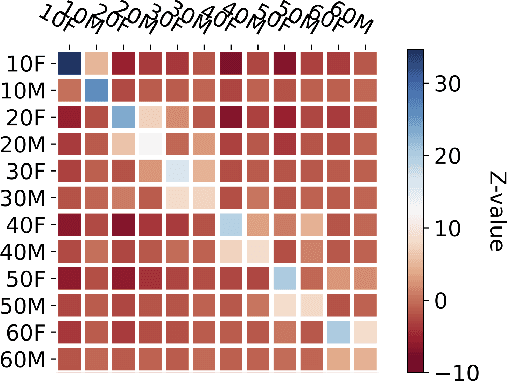
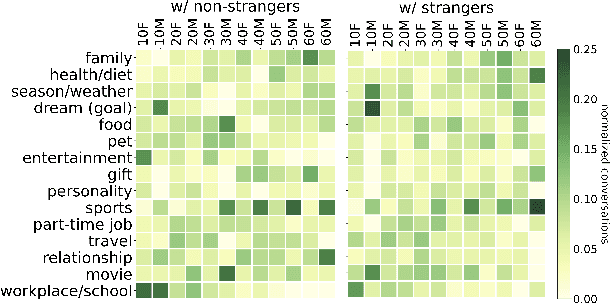
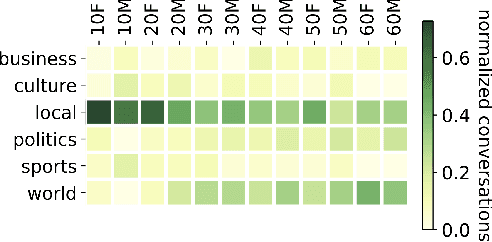
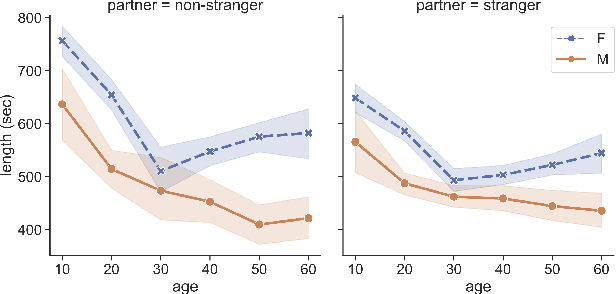
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.