Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Paper and Code
Apr 20, 2022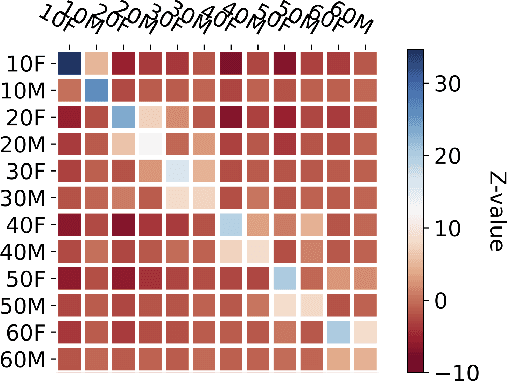
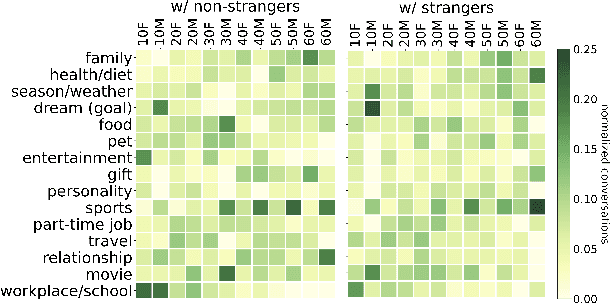
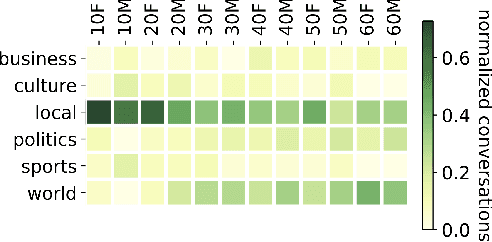
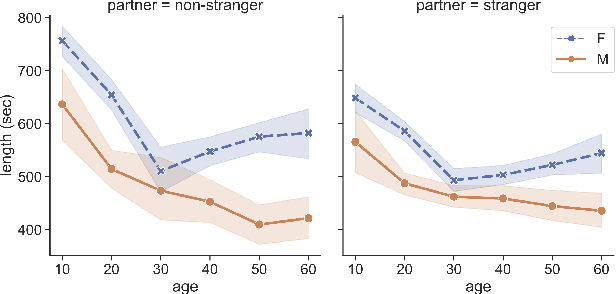
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.
* Accepted in AAAI ICWSM'22
View paper on