 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Mar 17, 2026Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
VILLAIN at AVerImaTeC: Verifying Image-Text Claims via Multi-Agent Collaboration
Feb 04, 2026This paper describes VILLAIN, a multimodal fact-checking system that verifies image-text claims through prompt-based multi-agent collaboration. For the AVerImaTeC shared task, VILLAIN employs vision-language model agents across multiple stages of fact-checking. Textual and visual evidence is retrieved from the knowledge store enriched through additional web collection. To identify key information and address inconsistencies among evidence items, modality-specific and cross-modal agents generate analysis reports. In the subsequent stage, question-answer pairs are produced based on these reports. Finally, the Verdict Prediction agent produces the verification outcome based on the image-text claim and the generated question-answer pairs. Our system ranked first on the leaderboard across all evaluation metrics. The source code is publicly available at https://github.com/ssu-humane/VILLAIN.
Exploring Fine-Tuning of Large Audio Language Models for Spoken Language Understanding under Limited Speech data
Sep 18, 2025Large Audio Language Models (LALMs) have emerged as powerful tools for speech-related tasks but remain underexplored for fine-tuning, especially with limited speech data. To bridge this gap, we systematically examine how different fine-tuning schemes including text-only, direct mixing, and curriculum learning affect spoken language understanding (SLU), focusing on scenarios where text-label pairs are abundant while paired speech-label data are limited. Results show that LALMs already achieve competitive performance with text-only fine-tuning, highlighting their strong generalization ability. Adding even small amounts of speech data (2-5%) yields substantial further gains, with curriculum learning particularly effective under scarce data. In cross-lingual SLU, combining source-language speech data with target-language text and minimal target-language speech data enables effective adaptation. Overall, this study provides practical insights into the LALM fine-tuning under realistic data constraints.
Hypothetical Documents or Knowledge Leakage? Rethinking LLM-based Query Expansion
Apr 19, 2025



Query expansion methods powered by large language models (LLMs) have demonstrated effectiveness in zero-shot retrieval tasks. These methods assume that LLMs can generate hypothetical documents that, when incorporated into a query vector, enhance the retrieval of real evidence. However, we challenge this assumption by investigating whether knowledge leakage in benchmarks contributes to the observed performance gains. Using fact verification as a testbed, we analyzed whether the generated documents contained information entailed by ground truth evidence and assessed their impact on performance. Our findings indicate that performance improvements occurred consistently only for claims whose generated documents included sentences entailed by ground truth evidence. This suggests that knowledge leakage may be present in these benchmarks, inflating the perceived performance of LLM-based query expansion methods, particularly in real-world scenarios that require retrieving niche or novel knowledge.
KOFFVQA: An Objectively Evaluated Free-form VQA Benchmark for Large Vision-Language Models in the Korean Language
Mar 31, 2025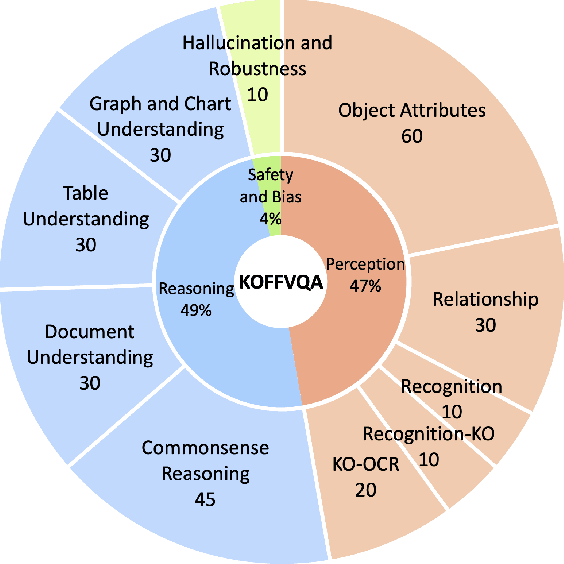
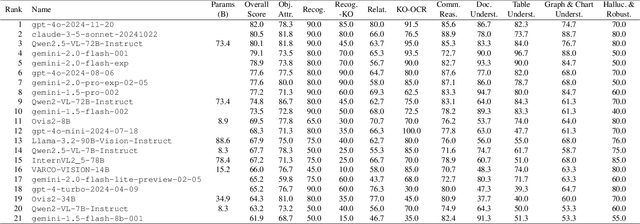

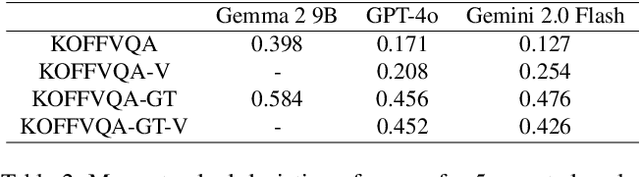
The recent emergence of Large Vision-Language Models(VLMs) has resulted in a variety of different benchmarks for evaluating such models. Despite this, we observe that most existing evaluation methods suffer from the fact that they either require the model to choose from pre-determined responses, sacrificing open-endedness, or evaluate responses using a judge model, resulting in subjective and unreliable evaluation. In addition, we observe a lack of benchmarks for VLMs in the Korean language, which are necessary as a separate metric from more common English language benchmarks, as the performance of generative language models can differ significantly based on the language being used. Therefore, we present KOFFVQA, a general-purpose free-form visual question answering benchmark in the Korean language for the evaluation of VLMs. Our benchmark consists of 275 carefully crafted questions each paired with an image and grading criteria covering 10 different aspects of VLM performance. The grading criteria eliminate the problem of unreliability by allowing the judge model to grade each response based on a pre-determined set of rules. By defining the evaluation criteria in an objective manner, even a small open-source model can be used to evaluate models on our benchmark reliably. In addition to evaluating a large number of existing VLMs on our benchmark, we also experimentally verify that our method of using pre-existing grading criteria for evaluation is much more reliable than existing methods. Our evaluation code is available at https://github.com/maum-ai/KOFFVQA
HerO at AVeriTeC: The Herd of Open Large Language Models for Verifying Real-World Claims
Oct 16, 2024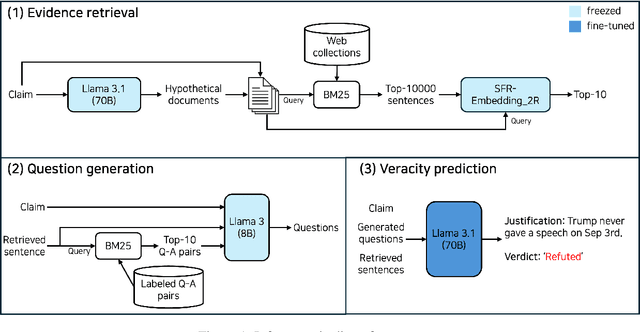


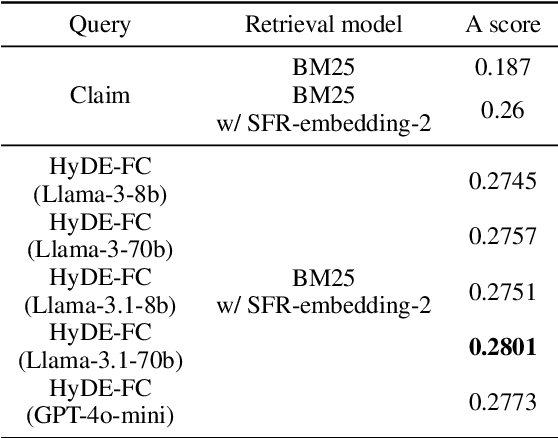
To tackle the AVeriTeC shared task hosted by the FEVER-24, we introduce a system that only employs publicly available large language models (LLMs) for each step of automated fact-checking, dubbed the Herd of Open LLMs for verifying real-world claims (HerO). HerO employs multiple LLMs for each step of automated fact-checking. For evidence retrieval, a language model is used to enhance a query by generating hypothetical fact-checking documents. We prompt pretrained and fine-tuned LLMs for question generation and veracity prediction by crafting prompts with retrieved in-context samples. HerO achieved 2nd place on the leaderboard with the AVeriTeC score of 0.57, suggesting the potential of open LLMs for verifying real-world claims. For future research, we make our code publicly available at https://github.com/ssu-humane/HerO.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024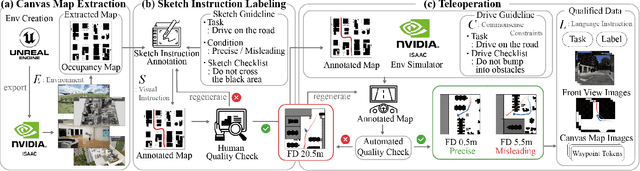
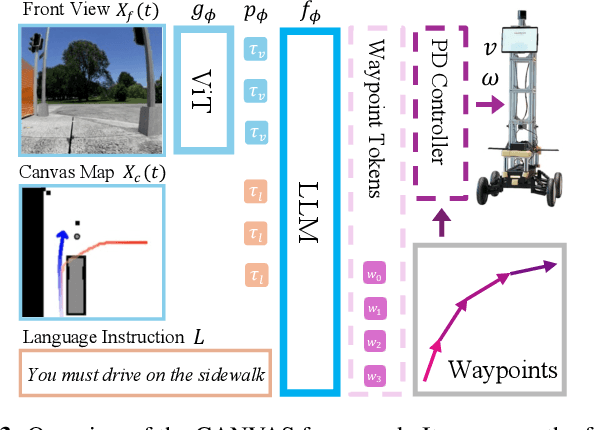
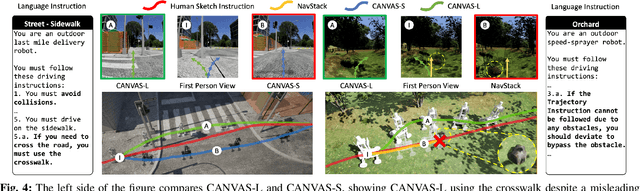
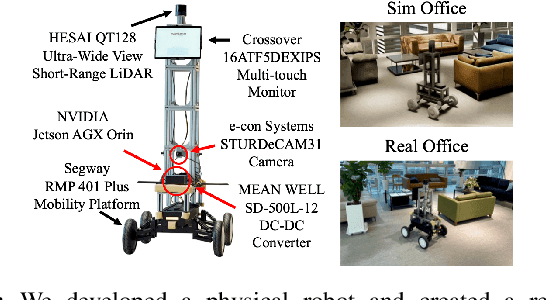
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.
Expanding on EnCLAP with Auxiliary Retrieval Model for Automated Audio Captioning
Sep 02, 2024In this technical report, we describe our submission to DCASE2024 Challenge Task6 (Automated Audio Captioning) and Task8 (Language-based Audio Retrieval). We develop our approach building upon the EnCLAP audio captioning framework and optimizing it for Task6 of the challenge. Notably, we outline the changes in the underlying components and the incorporation of the reranking process. Additionally, we submit a supplementary retriever model, a byproduct of our modified framework, to Task8. Our proposed systems achieve FENSE score of 0.542 on Task6 and mAP@10 score of 0.386 on Task8, significantly outperforming the baseline models.
EnCLAP++: Analyzing the EnCLAP Framework for Optimizing Automated Audio Captioning Performance
Sep 02, 2024



In this work, we aim to analyze and optimize the EnCLAP framework, a state-of-the-art model in automated audio captioning. We investigate the impact of modifying the acoustic encoder components, explore pretraining with different dataset scales, and study the effectiveness of a reranking scheme. Through extensive experimentation and quantitative analysis of generated captions, we develop EnCLAP++, an enhanced version that significantly surpasses the original.