 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink, Verbalize, then Speak: Bridging Complex Thoughts and Comprehensible Speech
Sep 19, 2025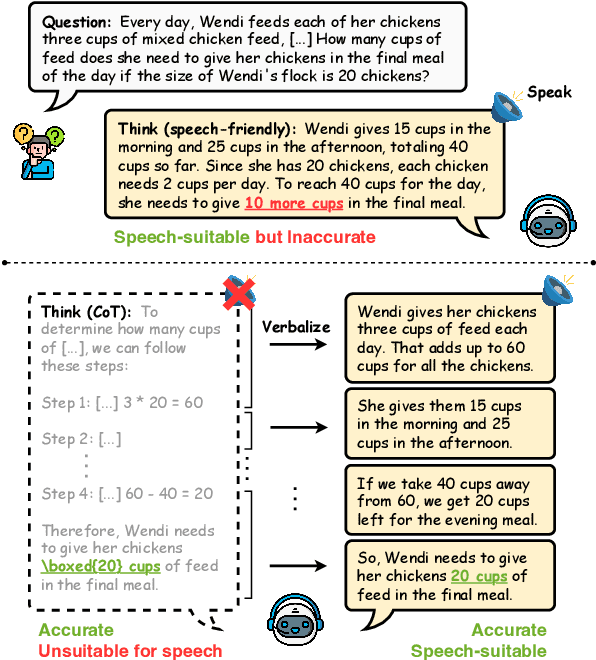

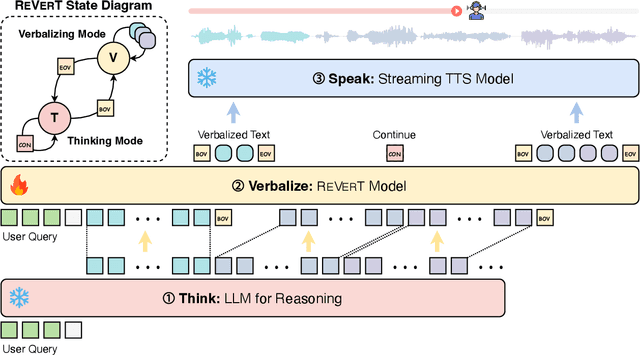
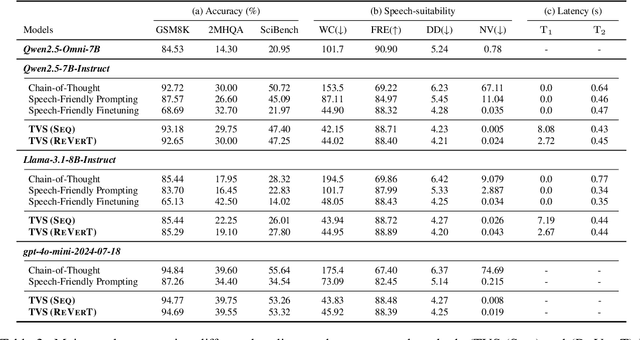
Spoken dialogue systems increasingly employ large language models (LLMs) to leverage their advanced reasoning capabilities. However, direct application of LLMs in spoken communication often yield suboptimal results due to mismatches between optimal textual and verbal delivery. While existing approaches adapt LLMs to produce speech-friendly outputs, their impact on reasoning performance remains underexplored. In this work, we propose Think-Verbalize-Speak, a framework that decouples reasoning from spoken delivery to preserve the full reasoning capacity of LLMs. Central to our method is verbalizing, an intermediate step that translates thoughts into natural, speech-ready text. We also introduce ReVerT, a latency-efficient verbalizer based on incremental and asynchronous summarization. Experiments across multiple benchmarks show that our method enhances speech naturalness and conciseness with minimal impact on reasoning. The project page with the dataset and the source code is available at https://yhytoto12.github.io/TVS-ReVerT
WoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal Vocalizations
Aug 28, 2025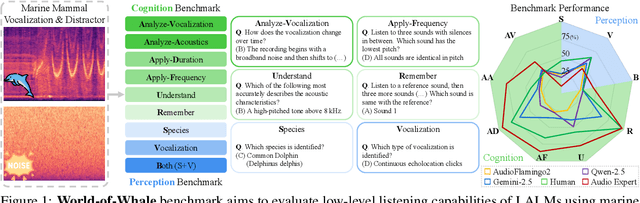

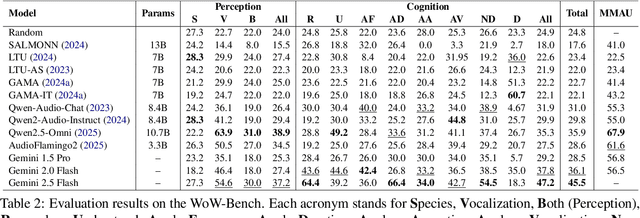
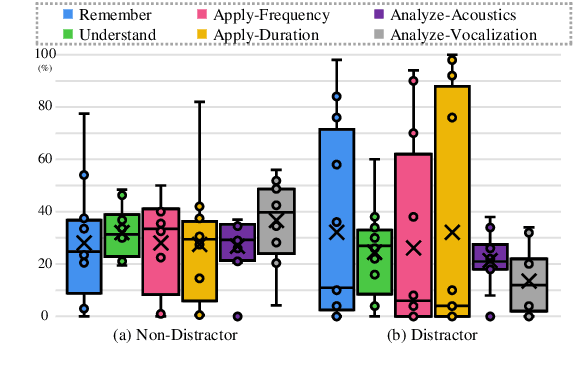
Large audio language models (LALMs) extend language understanding into the auditory domain, yet their ability to perform low-level listening, such as pitch and duration detection, remains underexplored. However, low-level listening is critical for real-world, out-of-distribution tasks where models must reason about unfamiliar sounds based on fine-grained acoustic cues. To address this gap, we introduce the World-of-Whale benchmark (WoW-Bench) to evaluate low-level auditory perception and cognition using marine mammal vocalizations. WoW-bench is composed of a Perception benchmark for categorizing novel sounds and a Cognition benchmark, inspired by Bloom's taxonomy, to assess the abilities to remember, understand, apply, and analyze sound events. For the Cognition benchmark, we additionally introduce distractor questions to evaluate whether models are truly solving problems through listening rather than relying on other heuristics. Experiments with state-of-the-art LALMs show performance far below human levels, indicating a need for stronger auditory grounding in LALMs.
Expanding on EnCLAP with Auxiliary Retrieval Model for Automated Audio Captioning
Sep 02, 2024In this technical report, we describe our submission to DCASE2024 Challenge Task6 (Automated Audio Captioning) and Task8 (Language-based Audio Retrieval). We develop our approach building upon the EnCLAP audio captioning framework and optimizing it for Task6 of the challenge. Notably, we outline the changes in the underlying components and the incorporation of the reranking process. Additionally, we submit a supplementary retriever model, a byproduct of our modified framework, to Task8. Our proposed systems achieve FENSE score of 0.542 on Task6 and mAP@10 score of 0.386 on Task8, significantly outperforming the baseline models.
EnCLAP++: Analyzing the EnCLAP Framework for Optimizing Automated Audio Captioning Performance
Sep 02, 2024



In this work, we aim to analyze and optimize the EnCLAP framework, a state-of-the-art model in automated audio captioning. We investigate the impact of modifying the acoustic encoder components, explore pretraining with different dataset scales, and study the effectiveness of a reranking scheme. Through extensive experimentation and quantitative analysis of generated captions, we develop EnCLAP++, an enhanced version that significantly surpasses the original.
EnCLAP: Combining Neural Audio Codec and Audio-Text Joint Embedding for Automated Audio Captioning
Jan 31, 2024We propose EnCLAP, a novel framework for automated audio captioning. EnCLAP employs two acoustic representation models, EnCodec and CLAP, along with a pretrained language model, BART. We also introduce a new training objective called masked codec modeling that improves acoustic awareness of the pretrained language model. Experimental results on AudioCaps and Clotho demonstrate that our model surpasses the performance of baseline models. Source code will be available at https://github.com/jaeyeonkim99/EnCLAP . An online demo is available at https://huggingface.co/spaces/enclap-team/enclap .
SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech
Jun 24, 2022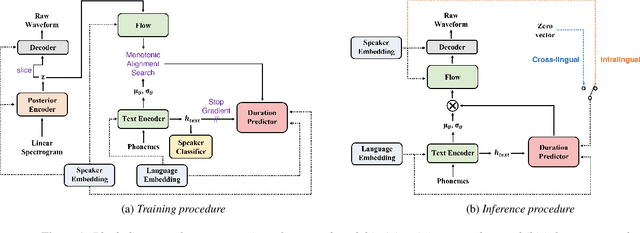
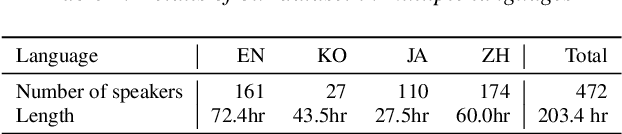
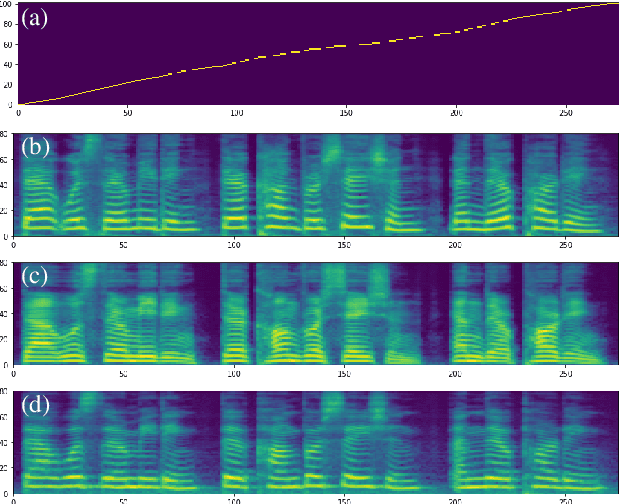

In this paper, we present SANE-TTS, a stable and natural end-to-end multilingual TTS model. By the difficulty of obtaining multilingual corpus for given speaker, training multilingual TTS model with monolingual corpora is unavoidable. We introduce speaker regularization loss that improves speech naturalness during cross-lingual synthesis as well as domain adversarial training, which is applied in other multilingual TTS models. Furthermore, by adding speaker regularization loss, replacing speaker embedding with zero vector in duration predictor stabilizes cross-lingual inference. With this replacement, our model generates speeches with moderate rhythm regardless of source speaker in cross-lingual synthesis. In MOS evaluation, SANE-TTS achieves naturalness score above 3.80 both in cross-lingual and intralingual synthesis, where the ground truth score is 3.99. Also, SANE-TTS maintains speaker similarity close to that of ground truth even in cross-lingual inference. Audio samples are available on our web page.
Talking Face Generation with Multilingual TTS
May 13, 2022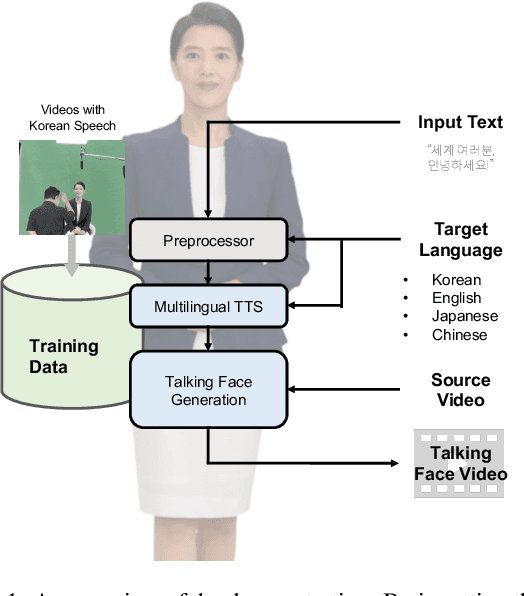
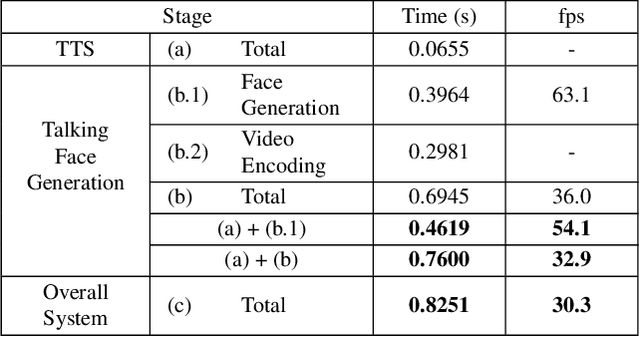


In this work, we propose a joint system combining a talking face generation system with a text-to-speech system that can generate multilingual talking face videos from only the text input. Our system can synthesize natural multilingual speeches while maintaining the vocal identity of the speaker, as well as lip movements synchronized to the synthesized speech. We demonstrate the generalization capabilities of our system by selecting four languages (Korean, English, Japanese, and Chinese) each from a different language family. We also compare the outputs of our talking face generation model to outputs of a prior work that claims multilingual support. For our demo, we add a translation API to the preprocessing stage and present it in the form of a neural dubber so that users can utilize the multilingual property of our system more easily.