 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink, Verbalize, then Speak: Bridging Complex Thoughts and Comprehensible Speech
Sep 19, 2025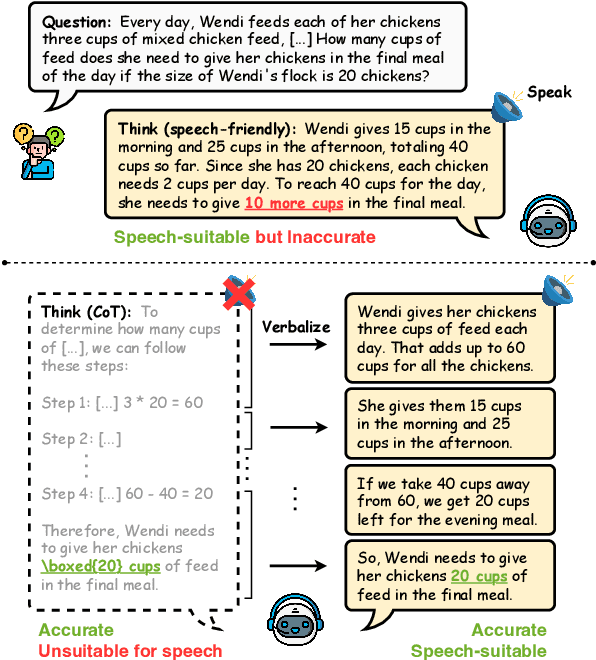

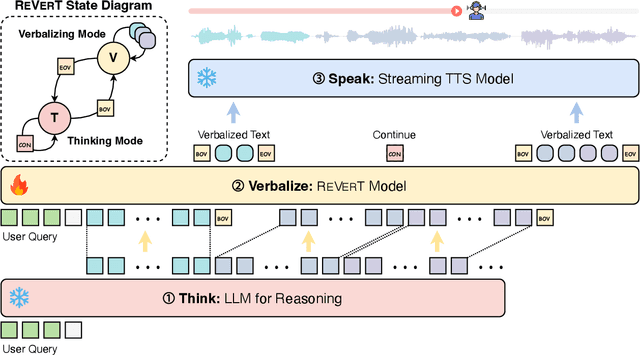
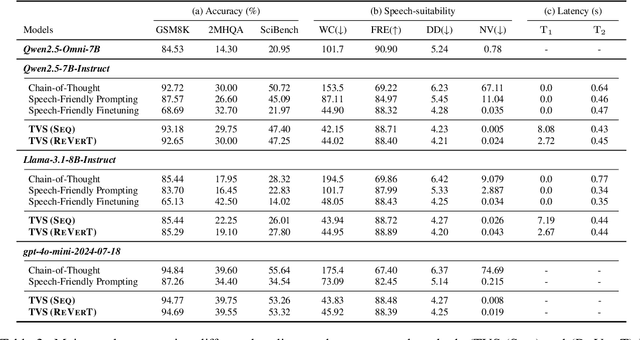
Spoken dialogue systems increasingly employ large language models (LLMs) to leverage their advanced reasoning capabilities. However, direct application of LLMs in spoken communication often yield suboptimal results due to mismatches between optimal textual and verbal delivery. While existing approaches adapt LLMs to produce speech-friendly outputs, their impact on reasoning performance remains underexplored. In this work, we propose Think-Verbalize-Speak, a framework that decouples reasoning from spoken delivery to preserve the full reasoning capacity of LLMs. Central to our method is verbalizing, an intermediate step that translates thoughts into natural, speech-ready text. We also introduce ReVerT, a latency-efficient verbalizer based on incremental and asynchronous summarization. Experiments across multiple benchmarks show that our method enhances speech naturalness and conciseness with minimal impact on reasoning. The project page with the dataset and the source code is available at https://yhytoto12.github.io/TVS-ReVerT
Talking Face Generation with Multilingual TTS
May 13, 2022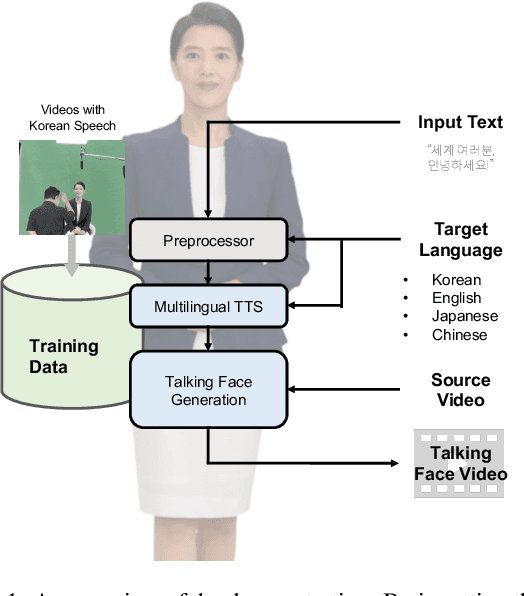
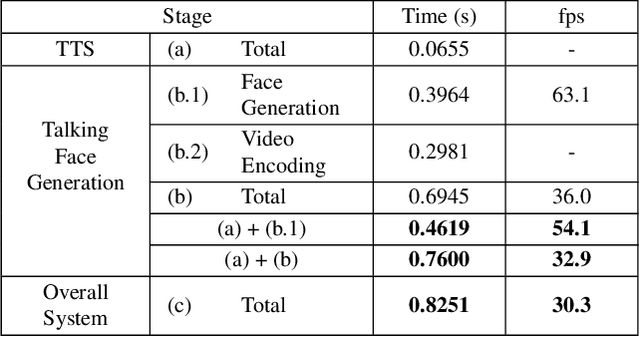


In this work, we propose a joint system combining a talking face generation system with a text-to-speech system that can generate multilingual talking face videos from only the text input. Our system can synthesize natural multilingual speeches while maintaining the vocal identity of the speaker, as well as lip movements synchronized to the synthesized speech. We demonstrate the generalization capabilities of our system by selecting four languages (Korean, English, Japanese, and Chinese) each from a different language family. We also compare the outputs of our talking face generation model to outputs of a prior work that claims multilingual support. For our demo, we add a translation API to the preprocessing stage and present it in the form of a neural dubber so that users can utilize the multilingual property of our system more easily.
FS-NCSR: Increasing Diversity of the Super-Resolution Space via Frequency Separation and Noise-Conditioned Normalizing Flow
Apr 20, 2022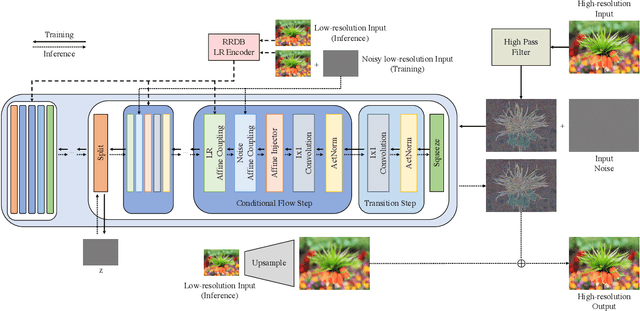
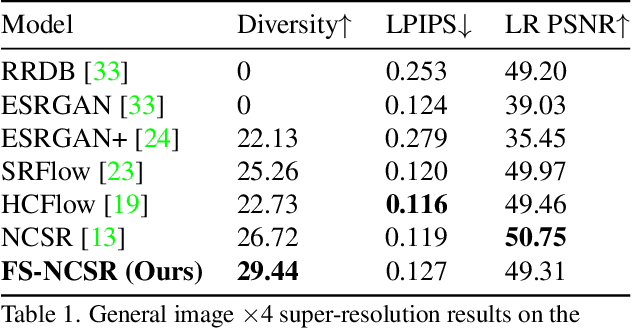

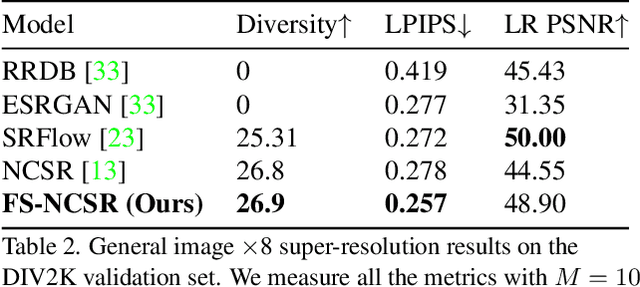
Super-resolution suffers from an innate ill-posed problem that a single low-resolution (LR) image can be from multiple high-resolution (HR) images. Recent studies on the flow-based algorithm solve this ill-posedness by learning the super-resolution space and predicting diverse HR outputs. Unfortunately, the diversity of the super-resolution outputs is still unsatisfactory, and the outputs from the flow-based model usually suffer from undesired artifacts which causes low-quality outputs. In this paper, we propose FS-NCSR which produces diverse and high-quality super-resolution outputs using frequency separation and noise conditioning compared to the existing flow-based approaches. As the sharpness and high-quality detail of the image rely on its high-frequency information, FS-NCSR only estimates the high-frequency information of the high-resolution outputs without redundant low-frequency components. Through this, FS-NCSR significantly improves the diversity score without significant image quality degradation compared to the NCSR, the winner of the previous NTIRE 2021 challenge.
Controllable and Interpretable Singing Voice Decomposition via Assem-VC
Oct 25, 2021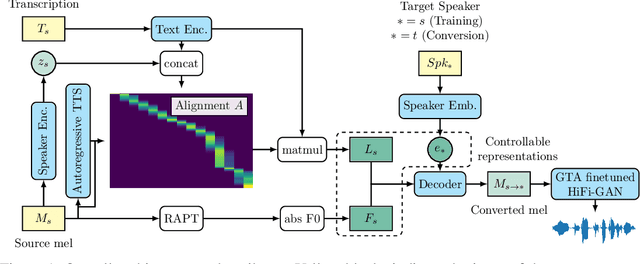


We propose a singing decomposition system that encodes time-aligned linguistic content, pitch, and source speaker identity via Assem-VC. With decomposed speaker-independent information and the target speaker's embedding, we could synthesize the singing voice of the target speaker. In conclusion, we made a perfectly synced duet with the user's singing voice and the target singer's converted singing voice.
Assem-VC: Realistic Voice Conversion by Assembling Modern Speech Synthesis Techniques
Apr 02, 2021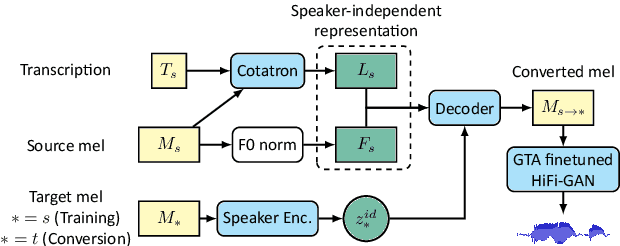
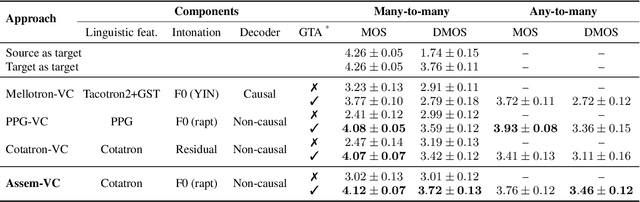
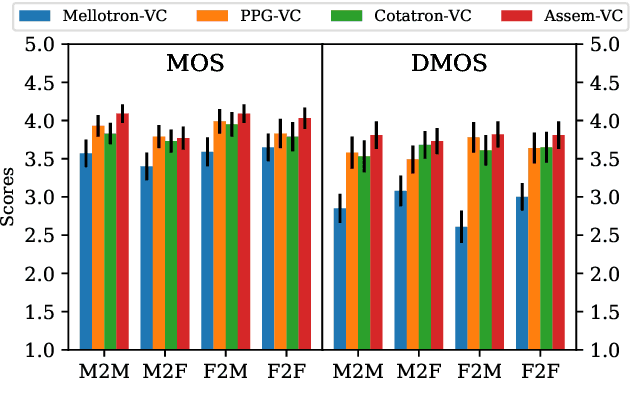

In this paper, we pose the current state-of-the-art voice conversion (VC) systems as two-encoder-one-decoder models. After comparing these models, we combine the best features and propose Assem-VC, a new state-of-the-art any-to-many non-parallel VC system. This paper also introduces the GTA finetuning in VC, which significantly improves the quality and the speaker similarity of the outputs. Assem-VC outperforms the previous state-of-the-art approaches in both the naturalness and the speaker similarity on the VCTK dataset. As an objective result, the degree of speaker disentanglement of features such as phonetic posteriorgrams (PPG) is also explored. Our investigation indicates that many-to-many VC results are no longer distinct from human speech and similar quality can be achieved with any-to-many models. Audio samples are available at https://mindslab-ai.github.io/assem-vc/