 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentSwap: An Efficient Latent Code Mapping Framework for Face Swapping
Mar 02, 2024



We propose LatentSwap, a simple face swapping framework generating a face swap latent code of a given generator. Utilizing randomly sampled latent codes, our framework is light and does not require datasets besides employing the pre-trained models, with the training procedure also being fast and straightforward. The loss objective consists of only three terms, and can effectively control the face swap results between source and target images. By attaching a pre-trained GAN inversion model independent to the model and using the StyleGAN2 generator, our model produces photorealistic and high-resolution images comparable to other competitive face swap models. We show that our framework is applicable to other generators such as StyleNeRF, paving a way to 3D-aware face swapping and is also compatible with other downstream StyleGAN2 generator tasks. The source code and models can be found at \url{https://github.com/usingcolor/LatentSwap}.
FS-NCSR: Increasing Diversity of the Super-Resolution Space via Frequency Separation and Noise-Conditioned Normalizing Flow
Apr 20, 2022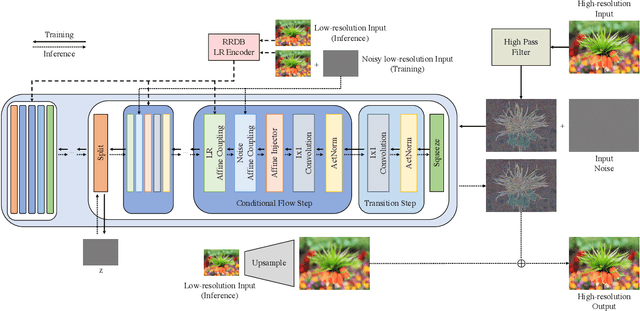
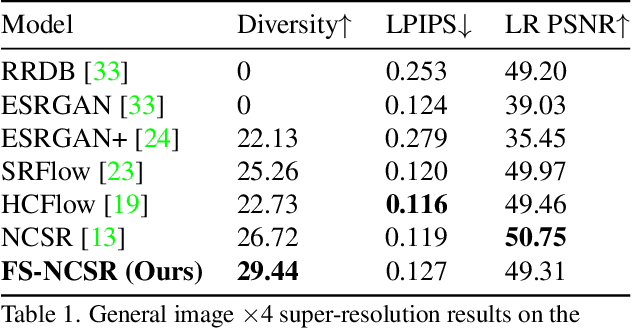

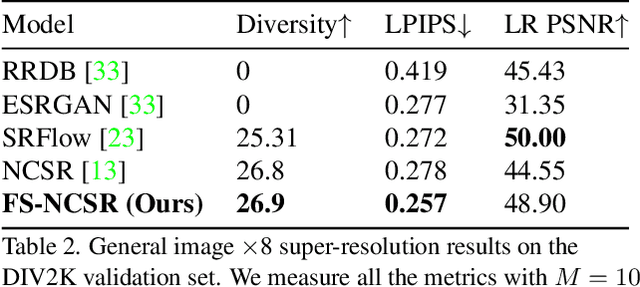
Super-resolution suffers from an innate ill-posed problem that a single low-resolution (LR) image can be from multiple high-resolution (HR) images. Recent studies on the flow-based algorithm solve this ill-posedness by learning the super-resolution space and predicting diverse HR outputs. Unfortunately, the diversity of the super-resolution outputs is still unsatisfactory, and the outputs from the flow-based model usually suffer from undesired artifacts which causes low-quality outputs. In this paper, we propose FS-NCSR which produces diverse and high-quality super-resolution outputs using frequency separation and noise conditioning compared to the existing flow-based approaches. As the sharpness and high-quality detail of the image rely on its high-frequency information, FS-NCSR only estimates the high-frequency information of the high-resolution outputs without redundant low-frequency components. Through this, FS-NCSR significantly improves the diversity score without significant image quality degradation compared to the NCSR, the winner of the previous NTIRE 2021 challenge.
Styleformer: Transformer based Generative Adversarial Networks with Style Vector
Jul 05, 2021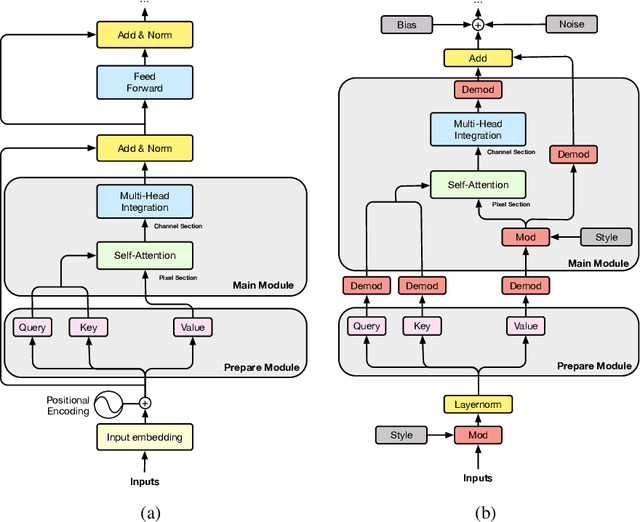
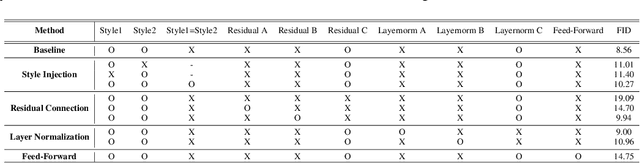
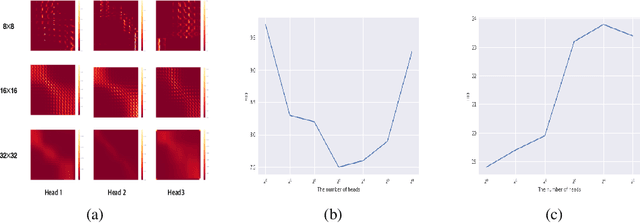

We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 15.17, IS 11.01, and FID 3.66, respectively on STL-10 and CelebA. We release our code at https://github.com/Jeeseung-Park/Styleformer.
Noise Conditional Flow Model for Learning the Super-Resolution Space
Jun 06, 2021
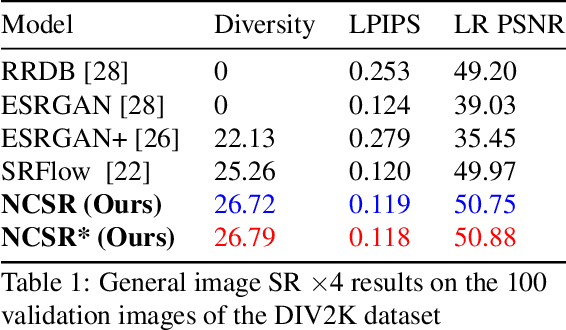

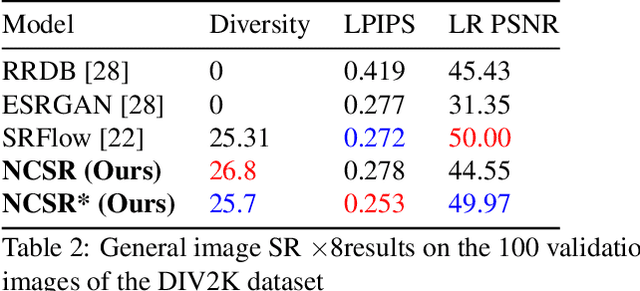
Fundamentally, super-resolution is ill-posed problem because a low-resolution image can be obtained from many high-resolution images. Recent studies for super-resolution cannot create diverse super-resolution images. Although SRFlow tried to account for ill-posed nature of the super-resolution by predicting multiple high-resolution images given a low-resolution image, there is room to improve the diversity and visual quality. In this paper, we propose Noise Conditional flow model for Super-Resolution, NCSR, which increases the visual quality and diversity of images through noise conditional layer. To learn more diverse data distribution, we add noise to training data. However, low-quality images are resulted from adding noise. We propose the noise conditional layer to overcome this phenomenon. The noise conditional layer makes our model generate more diverse images with higher visual quality than other works. Furthermore, we show that this layer can overcome data distribution mismatch, a problem that arises in normalizing flow models. With these benefits, NCSR outperforms baseline in diversity and visual quality and achieves better visual quality than traditional GAN-based models. We also get outperformed scores at NTIRE 2021 challenge.