 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTC-Depth: Pose-Refined Monocular Depth Estimation with Temporal Consistency
Apr 02, 2026Monocular depth estimation (MDE) has been widely adopted in the perception systems of autonomous vehicles and mobile robots. However, existing approaches often struggle to maintain temporal consistency in depth estimation across consecutive frames. This inconsistency not only causes jitter but can also lead to estimation failures when the depth range changes abruptly. To address these challenges, this paper proposes a consistency-aware monocular depth estimation framework that leverages wheel odometry from a mobile robot to achieve stable and coherent depth predictions over time. Specifically, we estimate camera pose and sparse depth from triangulation using optical flow between consecutive frames. The sparse depth estimates are used to update a recursive Bayesian estimate of the metric scale, which is then applied to rescale the relative depth predicted by a pre-trained depth estimation foundation model. The proposed method is evaluated on the KITTI, TartanAir, MS2, and our own dataset, demonstrating robust and accurate depth estimation performance.
Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models
Feb 25, 2026Scaling multimodal alignment between video and audio is challenging, particularly due to limited data and the mismatch between text descriptions and frame-level video information. In this work, we tackle the scaling challenge in multimodal-to-audio generation, examining whether models trained on short instances can generalize to longer ones during testing. To tackle this challenge, we present multimodal hierarchical networks so-called MMHNet, an enhanced extension of state-of-the-art video-to-audio models. Our approach integrates a hierarchical method and non-causal Mamba to support long-form audio generation. Our proposed method significantly improves long audio generation up to more than 5 minutes. We also prove that training short and testing long is possible in the video-to-audio generation tasks without training on the longer durations. We show in our experiments that our proposed method could achieve remarkable results on long-video to audio benchmarks, beating prior works in video-to-audio tasks. Moreover, we showcase our model capability in generating more than 5 minutes, while prior video-to-audio methods fall short in generating with long durations.
EUGens: Efficient, Unified, and General Dense Layers
Jan 30, 2026Efficient neural networks are essential for scaling machine learning models to real-time applications and resource-constrained environments. Fully-connected feedforward layers (FFLs) introduce computation and parameter count bottlenecks within neural network architectures. To address this challenge, in this work, we propose a new class of dense layers that generalize standard fully-connected feedforward layers, \textbf{E}fficient, \textbf{U}nified and \textbf{Gen}eral dense layers (EUGens). EUGens leverage random features to approximate standard FFLs and go beyond them by incorporating a direct dependence on the input norms in their computations. The proposed layers unify existing efficient FFL extensions and improve efficiency by reducing inference complexity from quadratic to linear time. They also lead to \textbf{the first} unbiased algorithms approximating FFLs with arbitrary polynomial activation functions. Furthermore, EuGens reduce the parameter count and computational overhead while preserving the expressive power and adaptability of FFLs. We also present a layer-wise knowledge transfer technique that bypasses backpropagation, enabling efficient adaptation of EUGens to pre-trained models. Empirically, we observe that integrating EUGens into Transformers and MLPs yields substantial improvements in inference speed (up to \textbf{27}\%) and memory efficiency (up to \textbf{30}\%) across a range of tasks, including image classification, language model pre-training, and 3D scene reconstruction. Overall, our results highlight the potential of EUGens for the scalable deployment of large-scale neural networks in real-world scenarios.
MVLight: Relightable Text-to-3D Generation via Light-conditioned Multi-View Diffusion
Nov 18, 2024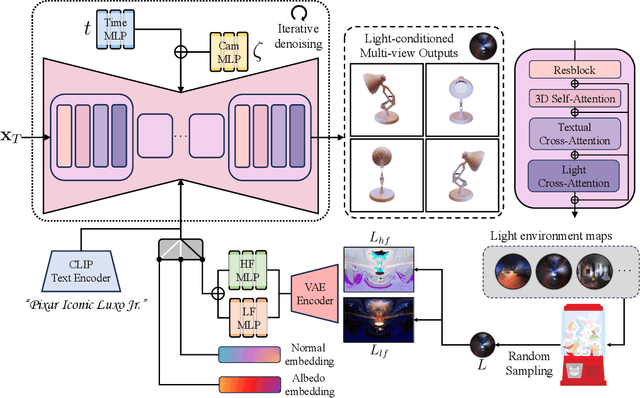

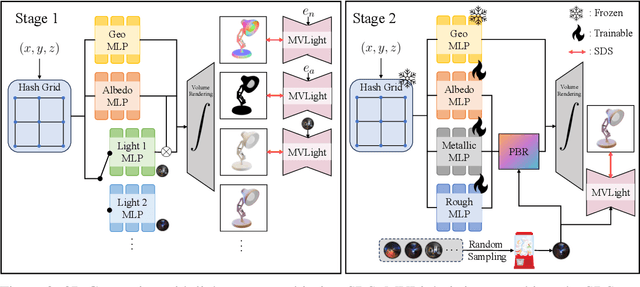

Recent advancements in text-to-3D generation, building on the success of high-performance text-to-image generative models, have made it possible to create imaginative and richly textured 3D objects from textual descriptions. However, a key challenge remains in effectively decoupling light-independent and lighting-dependent components to enhance the quality of generated 3D models and their relighting performance. In this paper, we present MVLight, a novel light-conditioned multi-view diffusion model that explicitly integrates lighting conditions directly into the generation process. This enables the model to synthesize high-quality images that faithfully reflect the specified lighting environment across multiple camera views. By leveraging this capability to Score Distillation Sampling (SDS), we can effectively synthesize 3D models with improved geometric precision and relighting capabilities. We validate the effectiveness of MVLight through extensive experiments and a user study.
Magnituder Layers for Implicit Neural Representations in 3D
Oct 13, 2024



Improving the efficiency and performance of implicit neural representations in 3D, particularly Neural Radiance Fields (NeRF) and Signed Distance Fields (SDF) is crucial for enabling their use in real-time applications. These models, while capable of generating photo-realistic novel views and detailed 3D reconstructions, often suffer from high computational costs and slow inference times. To address this, we introduce a novel neural network layer called the "magnituder", designed to reduce the number of training parameters in these models without sacrificing their expressive power. By integrating magnituders into standard feed-forward layer stacks, we achieve improved inference speed and adaptability. Furthermore, our approach enables a zero-shot performance boost in trained implicit neural representation models through layer-wise knowledge transfer without backpropagation, leading to more efficient scene reconstruction in dynamic environments.
Object Remover Performance Evaluation Methods using Class-wise Object Removal Images
Apr 17, 2024



Object removal refers to the process of erasing designated objects from an image while preserving the overall appearance, and it is one area where image inpainting is widely used in real-world applications. The performance of an object remover is quantitatively evaluated by measuring the quality of object removal results, similar to how the performance of an image inpainter is gauged. Current works reporting quantitative performance evaluations utilize original images as references. In this letter, to validate the current evaluation methods cannot properly evaluate the performance of an object remover, we create a dataset with object removal ground truth and compare the evaluations made by the current methods using original images to those utilizing object removal ground truth images. The disparities between two evaluation sets validate that the current methods are not suitable for measuring the performance of an object remover. Additionally, we propose new evaluation methods tailored to gauge the performance of an object remover. The proposed methods evaluate the performance through class-wise object removal results and utilize images without the target class objects as a comparison set. We confirm that the proposed methods can make judgments consistent with human evaluators in the COCO dataset, and that they can produce measurements aligning with those using object removal ground truth in the self-acquired dataset.
AURA : Automatic Mask Generator using Randomized Input Sampling for Object Removal
May 13, 2023
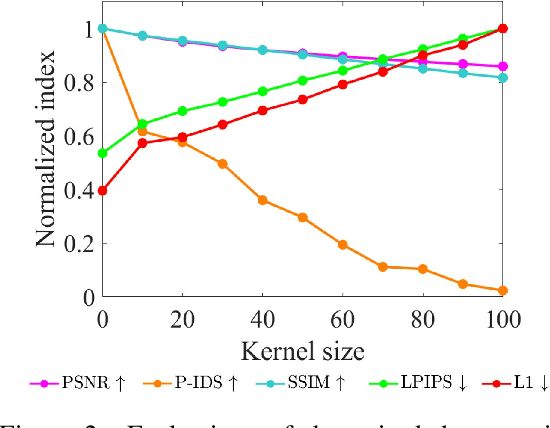
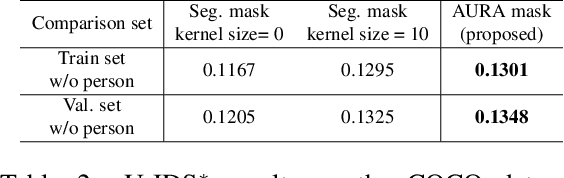
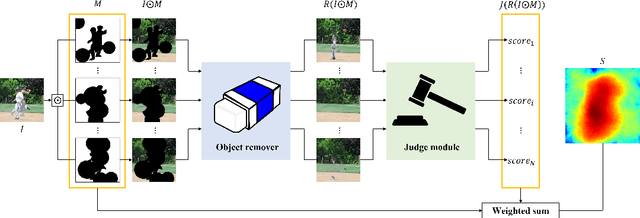
The objective of the image inpainting task is to fill missing regions of an image in a visually plausible way. Recently, deep-learning-based image inpainting networks have generated outstanding results, and some utilize their models as object removers by masking unwanted objects in an image. However, while trying to better remove objects using their networks, the previous works pay less attention to the importance of the input mask. In this paper, we focus on generating the input mask to better remove objects using the off-the-shelf image inpainting network. We propose an automatic mask generator inspired by the explainable AI (XAI) method, whose output can better remove objects than a semantic segmentation mask. The proposed method generates an importance map using randomly sampled input masks and quantitatively estimated scores of the completed images obtained from the random masks. The output mask is selected by a judge module among the candidate masks which are generated from the importance map. We design the judge module to quantitatively estimate the quality of the object removal results. In addition, we empirically find that the evaluation methods used in the previous works reporting object removal results are not appropriate for estimating the performance of an object remover. Therefore, we propose new evaluation metrics (FID$^*$ and U-IDS$^*$) to properly evaluate the quality of object removers. Experiments confirm that our method shows better performance in removing target class objects than the masks generated from the semantic segmentation maps, and the two proposed metrics make judgments consistent with humans.
SNeRL: Semantic-aware Neural Radiance Fields for Reinforcement Learning
Jan 27, 2023As previous representations for reinforcement learning cannot effectively incorporate a human-intuitive understanding of the 3D environment, they usually suffer from sub-optimal performances. In this paper, we present Semantic-aware Neural Radiance Fields for Reinforcement Learning (SNeRL), which jointly optimizes semantic-aware neural radiance fields (NeRF) with a convolutional encoder to learn 3D-aware neural implicit representation from multi-view images. We introduce 3D semantic and distilled feature fields in parallel to the RGB radiance fields in NeRF to learn semantic and object-centric representation for reinforcement learning. SNeRL outperforms not only previous pixel-based representations but also recent 3D-aware representations both in model-free and model-based reinforcement learning.
SwinDepth: Unsupervised Depth Estimation using Monocular Sequences via Swin Transformer and Densely Cascaded Network
Jan 17, 2023Monocular depth estimation plays a critical role in various computer vision and robotics applications such as localization, mapping, and 3D object detection. Recently, learning-based algorithms achieve huge success in depth estimation by training models with a large amount of data in a supervised manner. However, it is challenging to acquire dense ground truth depth labels for supervised training, and the unsupervised depth estimation using monocular sequences emerges as a promising alternative. Unfortunately, most studies on unsupervised depth estimation explore loss functions or occlusion masks, and there is little change in model architecture in that ConvNet-based encoder-decoder structure becomes a de-facto standard for depth estimation. In this paper, we employ a convolution-free Swin Transformer as an image feature extractor so that the network can capture both local geometric features and global semantic features for depth estimation. Also, we propose a Densely Cascaded Multi-scale Network (DCMNet) that connects every feature map directly with another from different scales via a top-down cascade pathway. This densely cascaded connectivity reinforces the interconnection between decoding layers and produces high-quality multi-scale depth outputs. The experiments on two different datasets, KITTI and Make3D, demonstrate that our proposed method outperforms existing state-of-the-art unsupervised algorithms.
DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model
Dec 09, 2022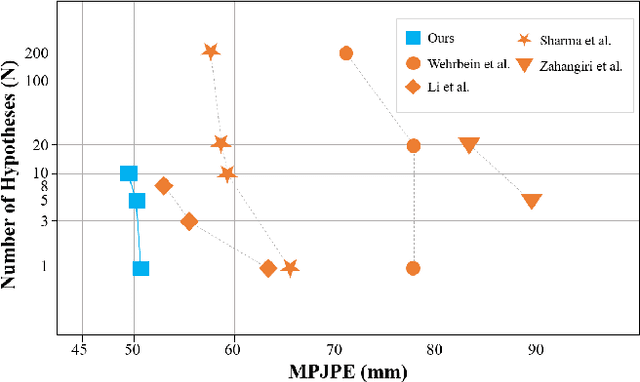
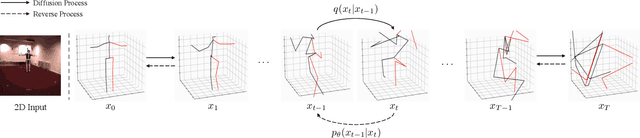
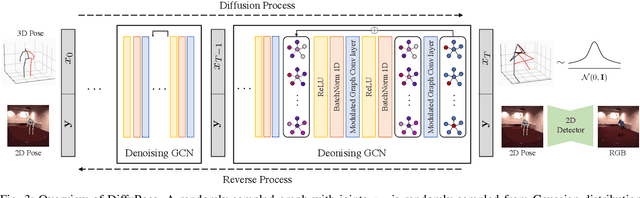
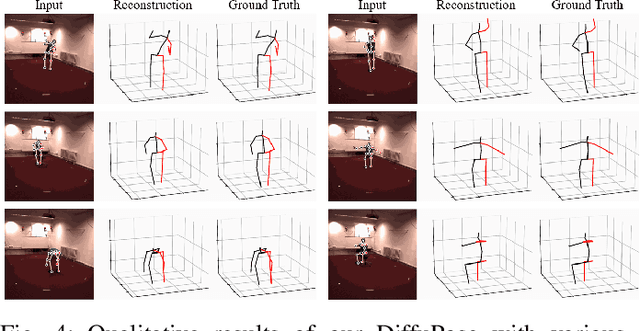
Thanks to the development of 2D keypoint detectors, monocular 3D human pose estimation (HPE) via 2D-to-3D uplifting approaches have achieved remarkable improvements. Still, monocular 3D HPE is a challenging problem due to the inherent depth ambiguities and occlusions. To handle this problem, many previous works exploit temporal information to mitigate such difficulties. However, there are many real-world applications where frame sequences are not accessible. This paper focuses on reconstructing a 3D pose from a single 2D keypoint detection. Rather than exploiting temporal information, we alleviate the depth ambiguity by generating multiple 3D pose candidates which can be mapped to an identical 2D keypoint. We build a novel diffusion-based framework to effectively sample diverse 3D poses from an off-the-shelf 2D detector. By considering the correlation between human joints by replacing the conventional denoising U-Net with graph convolutional network, our approach accomplishes further performance improvements. We evaluate our method on the widely adopted Human3.6M and HumanEva-I datasets. Comprehensive experiments are conducted to prove the efficacy of the proposed method, and they confirm that our model outperforms state-of-the-art multi-hypothesis 3D HPE methods.