 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneNAT: Masked Generative Modeling for Language-Guided Indoor Scene Synthesis
Jan 12, 2026We present SceneNAT, a single-stage masked non-autoregressive Transformer that synthesizes complete 3D indoor scenes from natural language instructions through only a few parallel decoding passes, offering improved performance and efficiency compared to prior state-of-the-art approaches. SceneNAT is trained via masked modeling over fully discretized representations of both semantic and spatial attributes. By applying a masking strategy at both the attribute level and the instance level, the model can better capture intra-object and inter-object structure. To boost relational reasoning, SceneNAT employs a dedicated triplet predictor for modeling the scene's layout and object relationships by mapping a set of learnable relation queries to a sparse set of symbolic triplets (subject, predicate, object). Extensive experiments on the 3D-FRONT dataset demonstrate that SceneNAT achieves superior performance compared to state-of-the-art autoregressive and diffusion baselines in both semantic compliance and spatial arrangement accuracy, while operating with substantially lower computational cost.
DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model
Dec 09, 2022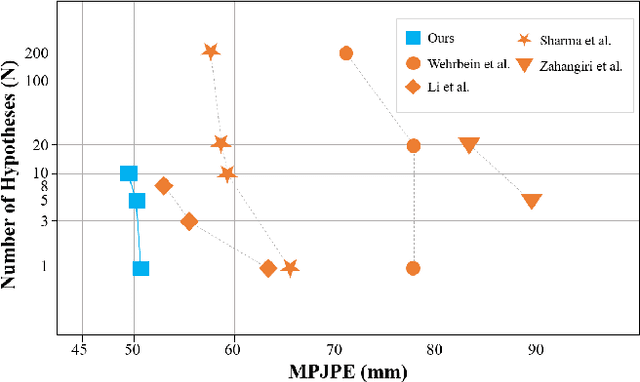
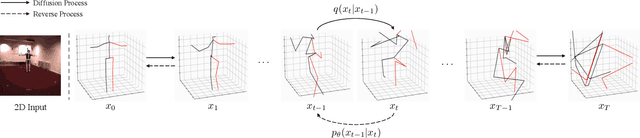
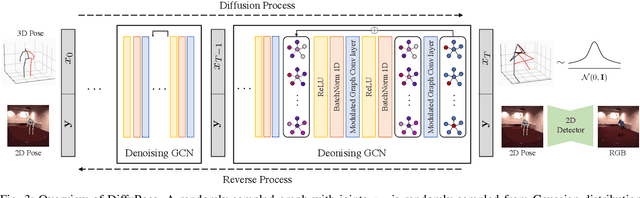
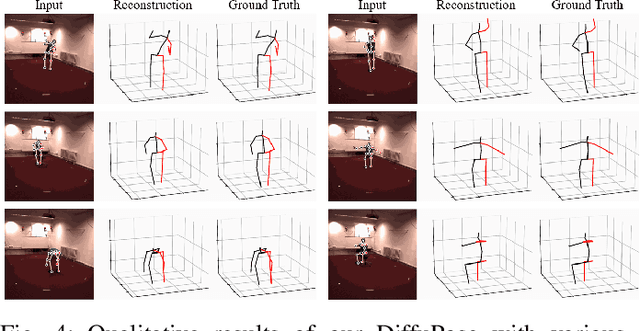
Thanks to the development of 2D keypoint detectors, monocular 3D human pose estimation (HPE) via 2D-to-3D uplifting approaches have achieved remarkable improvements. Still, monocular 3D HPE is a challenging problem due to the inherent depth ambiguities and occlusions. To handle this problem, many previous works exploit temporal information to mitigate such difficulties. However, there are many real-world applications where frame sequences are not accessible. This paper focuses on reconstructing a 3D pose from a single 2D keypoint detection. Rather than exploiting temporal information, we alleviate the depth ambiguity by generating multiple 3D pose candidates which can be mapped to an identical 2D keypoint. We build a novel diffusion-based framework to effectively sample diverse 3D poses from an off-the-shelf 2D detector. By considering the correlation between human joints by replacing the conventional denoising U-Net with graph convolutional network, our approach accomplishes further performance improvements. We evaluate our method on the widely adopted Human3.6M and HumanEva-I datasets. Comprehensive experiments are conducted to prove the efficacy of the proposed method, and they confirm that our model outperforms state-of-the-art multi-hypothesis 3D HPE methods.
Stability and Robustness Analysis of Plug-Pulling using an Aerial Manipulator
Jul 06, 2021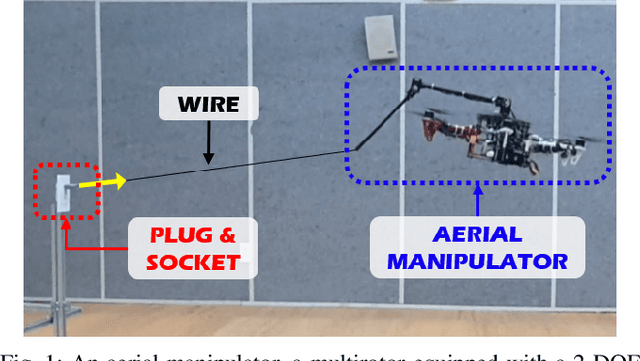
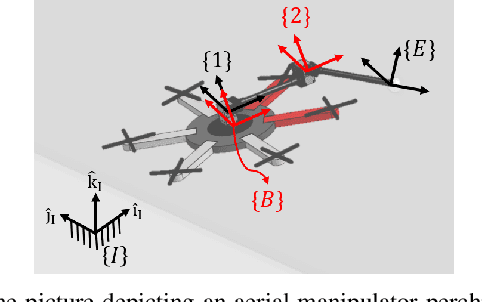

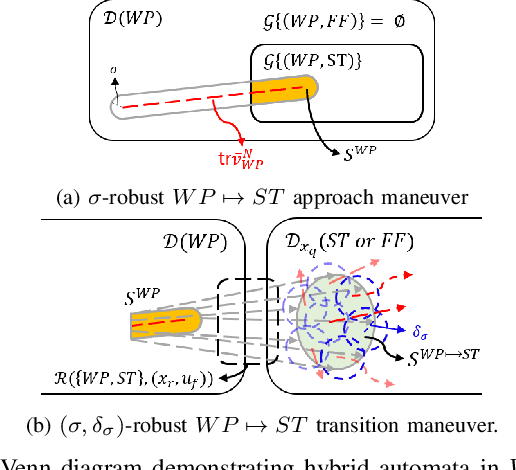
In this paper, an autonomous aerial manipulation task of pulling a plug out of an electric socket is conducted, where maintaining the stability and robustness is challenging due to sudden disappearance of a large interaction force. The abrupt change in the dynamical model before and after the separation of the plug can cause destabilization or mission failure. To accomplish aerial plug-pulling, we employ the concept of hybrid automata to divide the task into three operative modes, i.e, wire-pulling, stabilizing, and free-flight. Also, a strategy for trajectory generation and a design of disturbance-observer-based controllers for each operative mode are presented. Furthermore, the theory of hybrid automata is used to prove the stability and robustness during the mode transition. We validate the proposed trajectory generation and control method by an actual wire-pulling experiment with a multirotor-based aerial manipulator.