 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Decoupled Image Inpainting Framework for Class-specific Object Remover
Oct 03, 2024



Object removal refers to the process of erasing designated objects from an image while preserving the overall appearance. Existing works on object removal erase removal targets using image inpainting networks. However, image inpainting networks often generate unsatisfactory removal results. In this work, we find that the current training approach which encourages a single image inpainting model to handle both object removal and restoration tasks is one of the reasons behind such unsatisfactory result. Based on this finding, we propose a task-decoupled image inpainting framework which generates two separate inpainting models: an object restorer for object restoration tasks and an object remover for object removal tasks. We train the object restorer with the masks that partially cover the removal targets. Then, the proposed framework makes an object restorer to generate a guidance for training the object remover. Using the proposed framework, we obtain a class-specific object remover which focuses on removing objects of a target class, aiming to better erase target class objects than general object removers. We also introduce a data curation method that encompasses the image selection and mask generation approaches used to produce training data for the proposed class-specific object remover. Using the proposed curation method, we can simulate the scenarios where an object remover is trained on the data with object removal ground truth images. Experiments on multiple datasets show that the proposed class-specific object remover can better remove target class objects than object removers based on image inpainting networks.
Object Remover Performance Evaluation Methods using Class-wise Object Removal Images
Apr 17, 2024



Object removal refers to the process of erasing designated objects from an image while preserving the overall appearance, and it is one area where image inpainting is widely used in real-world applications. The performance of an object remover is quantitatively evaluated by measuring the quality of object removal results, similar to how the performance of an image inpainter is gauged. Current works reporting quantitative performance evaluations utilize original images as references. In this letter, to validate the current evaluation methods cannot properly evaluate the performance of an object remover, we create a dataset with object removal ground truth and compare the evaluations made by the current methods using original images to those utilizing object removal ground truth images. The disparities between two evaluation sets validate that the current methods are not suitable for measuring the performance of an object remover. Additionally, we propose new evaluation methods tailored to gauge the performance of an object remover. The proposed methods evaluate the performance through class-wise object removal results and utilize images without the target class objects as a comparison set. We confirm that the proposed methods can make judgments consistent with human evaluators in the COCO dataset, and that they can produce measurements aligning with those using object removal ground truth in the self-acquired dataset.
AURA : Automatic Mask Generator using Randomized Input Sampling for Object Removal
May 13, 2023
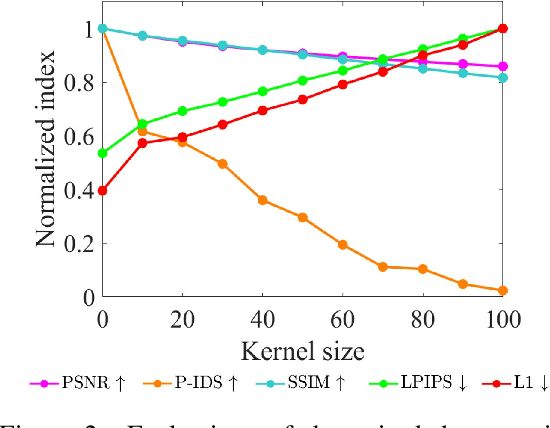
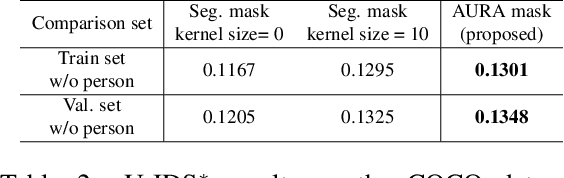
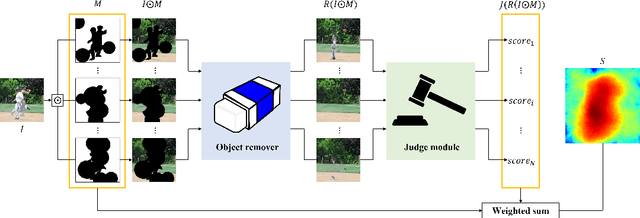
The objective of the image inpainting task is to fill missing regions of an image in a visually plausible way. Recently, deep-learning-based image inpainting networks have generated outstanding results, and some utilize their models as object removers by masking unwanted objects in an image. However, while trying to better remove objects using their networks, the previous works pay less attention to the importance of the input mask. In this paper, we focus on generating the input mask to better remove objects using the off-the-shelf image inpainting network. We propose an automatic mask generator inspired by the explainable AI (XAI) method, whose output can better remove objects than a semantic segmentation mask. The proposed method generates an importance map using randomly sampled input masks and quantitatively estimated scores of the completed images obtained from the random masks. The output mask is selected by a judge module among the candidate masks which are generated from the importance map. We design the judge module to quantitatively estimate the quality of the object removal results. In addition, we empirically find that the evaluation methods used in the previous works reporting object removal results are not appropriate for estimating the performance of an object remover. Therefore, we propose new evaluation metrics (FID$^*$ and U-IDS$^*$) to properly evaluate the quality of object removers. Experiments confirm that our method shows better performance in removing target class objects than the masks generated from the semantic segmentation maps, and the two proposed metrics make judgments consistent with humans.