 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPLO: Vision Transformer based Pose-Conditioned Self-Loop Graph for Human-Object Interaction Detection
Apr 17, 2023
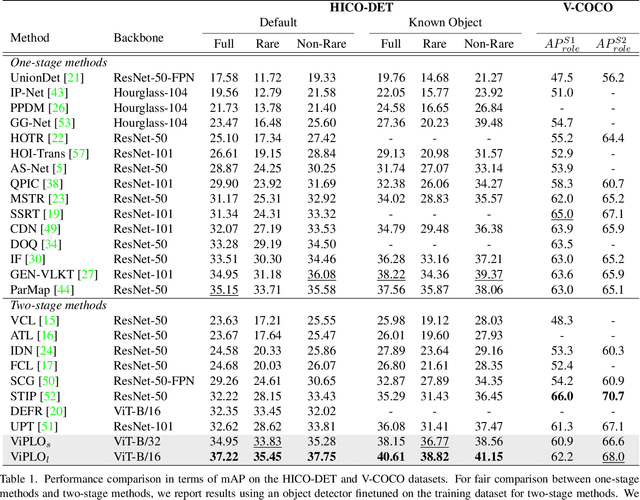
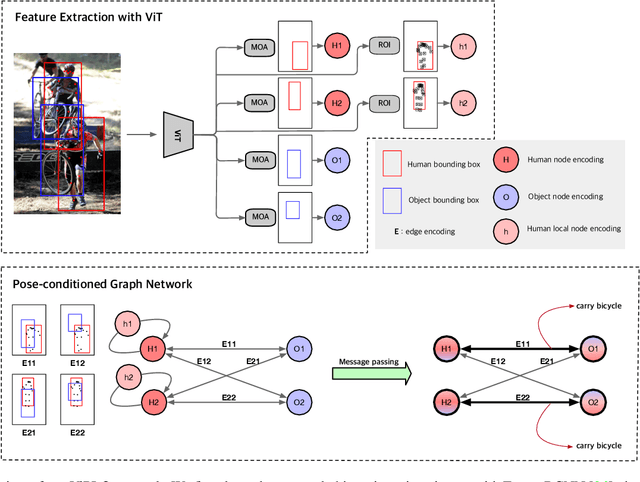
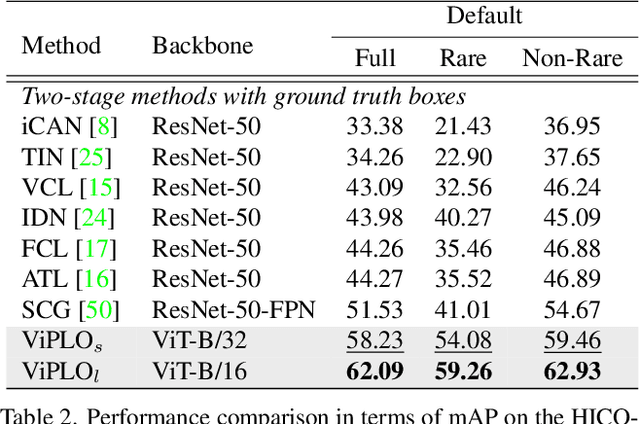
Human-Object Interaction (HOI) detection, which localizes and infers relationships between human and objects, plays an important role in scene understanding. Although two-stage HOI detectors have advantages of high efficiency in training and inference, they suffer from lower performance than one-stage methods due to the old backbone networks and the lack of considerations for the HOI perception process of humans in the interaction classifiers. In this paper, we propose Vision Transformer based Pose-Conditioned Self-Loop Graph (ViPLO) to resolve these problems. First, we propose a novel feature extraction method suitable for the Vision Transformer backbone, called masking with overlapped area (MOA) module. The MOA module utilizes the overlapped area between each patch and the given region in the attention function, which addresses the quantization problem when using the Vision Transformer backbone. In addition, we design a graph with a pose-conditioned self-loop structure, which updates the human node encoding with local features of human joints. This allows the classifier to focus on specific human joints to effectively identify the type of interaction, which is motivated by the human perception process for HOI. As a result, ViPLO achieves the state-of-the-art results on two public benchmarks, especially obtaining a +2.07 mAP performance gain on the HICO-DET dataset. The source codes are available at https://github.com/Jeeseung-Park/ViPLO.
Styleformer: Transformer based Generative Adversarial Networks with Style Vector
Jul 05, 2021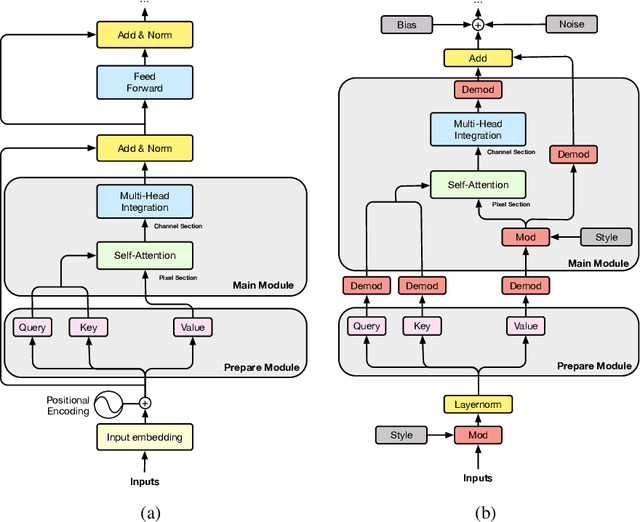
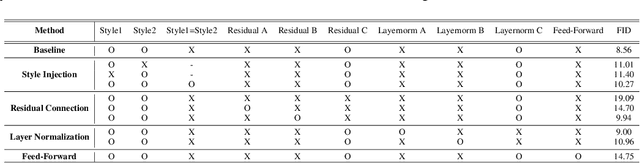
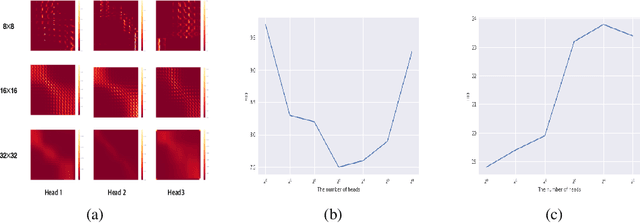

We propose Styleformer, which is a style-based generator for GAN architecture, but a convolution-free transformer-based generator. In our paper, we explain how a transformer can generate high-quality images, overcoming the disadvantage that convolution operations are difficult to capture global features in an image. Furthermore, we change the demodulation of StyleGAN2 and modify the existing transformer structure (e.g., residual connection, layer normalization) to create a strong style-based generator with a convolution-free structure. We also make Styleformer lighter by applying Linformer, enabling Styleformer to generate higher resolution images and result in improvements in terms of speed and memory. We experiment with the low-resolution image dataset such as CIFAR-10, as well as the high-resolution image dataset like LSUN-church. Styleformer records FID 2.82 and IS 9.94 on CIFAR-10, a benchmark dataset, which is comparable performance to the current state-of-the-art and outperforms all GAN-based generative models, including StyleGAN2-ADA with fewer parameters on the unconditional setting. We also both achieve new state-of-the-art with FID 15.17, IS 11.01, and FID 3.66, respectively on STL-10 and CelebA. We release our code at https://github.com/Jeeseung-Park/Styleformer.