 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic: Compositional Multi-Concept Erasure via Vector Field Blending
May 25, 2026Concept erasure has emerged as a key research direction for ensuring safe and ethical image synthesis in Text-to-Image (T2I) models. While existing studies have explored concept erasure across multiple concepts, they typically assume only a single target concept per image, a limitation increasingly exposed by modern flow-based T2I models, which can generate complex scenes with multiple concepts simultaneously. To address this gap, we introduce compositional multi-concept erasure, a new task that aims to simultaneously remove multiple target concepts within a single scene. We propose CoME-Bench, a benchmark for evaluating compositional multi-concept erasure, which covers both intra- and cross-category scenarios. We further propose Mosaic, a novel framework for multi-concept erasure in flow-based T2I models, which exploits the spatial locality of target concepts in the vector field by dynamically constructing concept-specific masks and selectively blending them without additional optimization. Extensive experiments demonstrate that Mosaic effectively removes multiple target concepts in complex compositional scenes while preserving non-target contexts.
SLIM: Semantic-based Low-bitrate Image compression for Machines by leveraging diffusion
Dec 23, 2025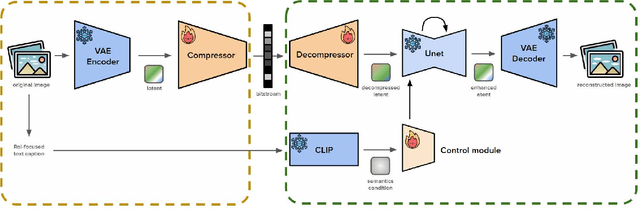

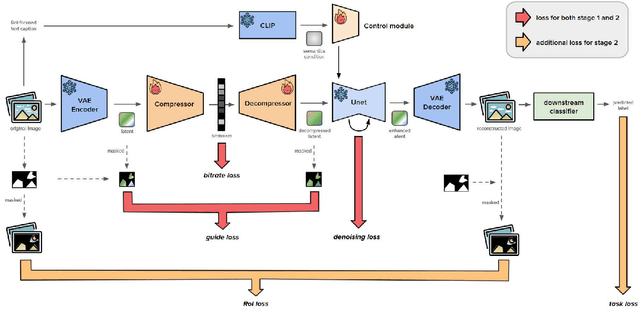

In recent years, the demand of image compression models for machine vision has increased dramatically. However, the training frameworks of image compression still focus on the vision of human, maintaining the excessive perceptual details, thus have limitations in optimally reducing the bits per pixel in the case of performing machine vision tasks. In this paper, we propose Semantic-based Low-bitrate Image compression for Machines by leveraging diffusion, termed SLIM. This is a new effective training framework of image compression for machine vision, using a pretrained latent diffusion model.The compressor model of our method focuses only on the Region-of-Interest (RoI) areas for machine vision in the image latent, to compress it compactly. Then the pretrained Unet model enhances the decompressed latent, utilizing a RoI-focused text caption which containing semantic information of the image. Therefore, SLIM is able to focus on RoI areas of the image without any guide mask at the inference stage, achieving low bitrate when compressing. And SLIM is also able to enhance a decompressed latent by denoising steps, so the final reconstructed image from the enhanced latent can be optimized for the machine vision task while still containing perceptual details for human vision. Experimental results show that SLIM achieves a higher classification accuracy in the same bits per pixel condition, compared to conventional image compression models for machines.
Progressive Learned Image Compression for Machine Perception
Dec 23, 2025Recent advances in learned image codecs have been extended from human perception toward machine perception. However, progressive image compression with fine granular scalability (FGS)-which enables decoding a single bitstream at multiple quality levels-remains unexplored for machine-oriented codecs. In this work, we propose a novel progressive learned image compression codec for machine perception, PICM-Net, based on trit-plane coding. By analyzing the difference between human- and machine-oriented rate-distortion priorities, we systematically examine the latent prioritization strategies in terms of machine-oriented codecs. To further enhance real-world adaptability, we design an adaptive decoding controller, which dynamically determines the necessary decoding level during inference time to maintain the desired confidence of downstream machine prediction. Extensive experiments demonstrate that our approach enables efficient and adaptive progressive transmission while maintaining high performance in the downstream classification task, establishing a new paradigm for machine-aware progressive image compression.
DESSERT: Diffusion-based Event-driven Single-frame Synthesis via Residual Training
Dec 19, 2025Video frame prediction extrapolates future frames from previous frames, but suffers from prediction errors in dynamic scenes due to the lack of information about the next frame. Event cameras address this limitation by capturing per-pixel brightness changes asynchronously with high temporal resolution. Prior research on event-based video frame prediction has leveraged motion information from event data, often by predicting event-based optical flow and reconstructing frames via pixel warping. However, such approaches introduce holes and blurring when pixel displacement is inaccurate. To overcome this limitation, we propose DESSERT, a diffusion-based event-driven single-frame synthesis framework via residual training. Leveraging a pre-trained Stable Diffusion model, our method is trained on inter-frame residuals to ensure temporal consistency. The training pipeline consists of two stages: (1) an Event-to-Residual Alignment Variational Autoencoder (ER-VAE) that aligns the event frame between anchor and target frames with the corresponding residual, and (2) a diffusion model that denoises the residual latent conditioned on event data. Furthermore, we introduce Diverse-Length Temporal (DLT) augmentation, which improves robustness by training on frame segments of varying temporal lengths. Experimental results demonstrate that our method outperforms existing event-based reconstruction, image-based video frame prediction, event-based video frame prediction, and one-sided event-based video frame interpolation methods, producing sharper and more temporally consistent frame synthesis.
Dominating vs. Dominated: Generative Collapse in Diffusion Models
Dec 19, 2025Text-to-image diffusion models have drawn significant attention for their ability to generate diverse and high-fidelity images. However, when generating from multi-concept prompts, one concept token often dominates the generation, suppressing the others-a phenomenon we term the Dominant-vs-Dominated (DvD) imbalance. To systematically analyze this imbalance, we introduce DominanceBench and examine its causes from both data and architectural perspectives. Through various experiments, we show that the limited instance diversity in training data exacerbates the inter-concept interference. Analysis of cross-attention dynamics further reveals that dominant tokens rapidly saturate attention, progressively suppressing others across diffusion timesteps. In addition, head ablation studies show that the DvD behavior arises from distributed attention mechanisms across multiple heads. Our findings provide key insights into generative collapse, advancing toward more reliable and controllable text-to-image generation.
Exploring Cross-Stage Adversarial Transferability in Class-Incremental Continual Learning
Aug 12, 2025Class-incremental continual learning addresses catastrophic forgetting by enabling classification models to preserve knowledge of previously learned classes while acquiring new ones. However, the vulnerability of the models against adversarial attacks during this process has not been investigated sufficiently. In this paper, we present the first exploration of vulnerability to stage-transferred attacks, i.e., an adversarial example generated using the model in an earlier stage is used to attack the model in a later stage. Our findings reveal that continual learning methods are highly susceptible to these attacks, raising a serious security issue. We explain this phenomenon through model similarity between stages and gradual robustness degradation. Additionally, we find that existing adversarial training-based defense methods are not sufficiently effective to stage-transferred attacks. Codes are available at https://github.com/mcml-official/CSAT.
Emotional EEG Classification using Upscaled Connectivity Matrices
Feb 11, 2025In recent studies of emotional EEG classification, connectivity matrices have been successfully employed as input to convolutional neural networks (CNNs), which can effectively consider inter-regional interaction patterns in EEG. However, we find that such an approach has a limitation that important patterns in connectivity matrices may be lost during the convolutional operations in CNNs. To resolve this issue, we propose and validate an idea to upscale the connectivity matrices to strengthen the local patterns. Experimental results demonstrate that this simple idea can significantly enhance the classification performance.
CROPS: Model-Agnostic Training-Free Framework for Safe Image Synthesis with Latent Diffusion Models
Jan 09, 2025With advances in diffusion models, image generation has shown significant performance improvements. This raises concerns about the potential abuse of image generation, such as the creation of explicit or violent images, commonly referred to as Not Safe For Work (NSFW) content. To address this, the Stable Diffusion model includes several safety checkers to censor initial text prompts and final output images generated from the model. However, recent research has shown that these safety checkers have vulnerabilities against adversarial attacks, allowing them to generate NSFW images. In this paper, we find that these adversarial attacks are not robust to small changes in text prompts or input latents. Based on this, we propose CROPS (Circular or RandOm Prompts for Safety), a model-agnostic framework that easily defends against adversarial attacks generating NSFW images without requiring additional training. Moreover, we develop an approach that utilizes one-step diffusion models for efficient NSFW detection (CROPS-1), further reducing computational resources. We demonstrate the superiority of our method in terms of performance and applicability.
Impact of Regularization on Calibration and Robustness: from the Representation Space Perspective
Oct 05, 2024Recent studies have shown that regularization techniques using soft labels, e.g., label smoothing, Mixup, and CutMix, not only enhance image classification accuracy but also improve model calibration and robustness against adversarial attacks. However, the underlying mechanisms of such improvements remain underexplored. In this paper, we offer a novel explanation from the perspective of the representation space (i.e., the space of the features obtained at the penultimate layer). Our investigation first reveals that the decision regions in the representation space form cone-like shapes around the origin after training regardless of the presence of regularization. However, applying regularization causes changes in the distribution of features (or representation vectors). The magnitudes of the representation vectors are reduced and subsequently the cosine similarities between the representation vectors and the class centers (minimal loss points for each class) become higher, which acts as a central mechanism inducing improved calibration and robustness. Our findings provide new insights into the characteristics of the high-dimensional representation space in relation to training and regularization using soft labels.
Network Fission Ensembles for Low-Cost Self-Ensembles
Aug 05, 2024Recent ensemble learning methods for image classification have been shown to improve classification accuracy with low extra cost. However, they still require multiple trained models for ensemble inference, which eventually becomes a significant burden when the model size increases. In this paper, we propose a low-cost ensemble learning and inference, called Network Fission Ensembles (NFE), by converting a conventional network itself into a multi-exit structure. Starting from a given initial network, we first prune some of the weights to reduce the training burden. We then group the remaining weights into several sets and create multiple auxiliary paths using each set to construct multi-exits. We call this process Network Fission. Through this, multiple outputs can be obtained from a single network, which enables ensemble learning. Since this process simply changes the existing network structure to multi-exits without using additional networks, there is no extra computational burden for ensemble learning and inference. Moreover, by learning from multiple losses of all exits, the multi-exits improve performance via regularization, and high performance can be achieved even with increased network sparsity. With our simple yet effective method, we achieve significant improvement compared to existing ensemble methods. The code is available at https://github.com/hjdw2/NFE.