 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Score: Evaluating Generative Models and Individual Generated Images based on Complexity and Vulnerability
Dec 17, 2023With the advancement of generative models, the assessment of generated images becomes more and more important. Previous methods measure distances between features of reference and generated images from trained vision models. In this paper, we conduct an extensive investigation into the relationship between the representation space and input space around generated images. We first propose two measures related to the presence of unnatural elements within images: complexity, which indicates how non-linear the representation space is, and vulnerability, which is related to how easily the extracted feature changes by adversarial input changes. Based on these, we introduce a new metric to evaluating image-generative models called anomaly score (AS). Moreover, we propose AS-i (anomaly score for individual images) that can effectively evaluate generated images individually. Experimental results demonstrate the validity of the proposed approach.
Demystifying Randomly Initialized Networks for Evaluating Generative Models
Aug 19, 2022
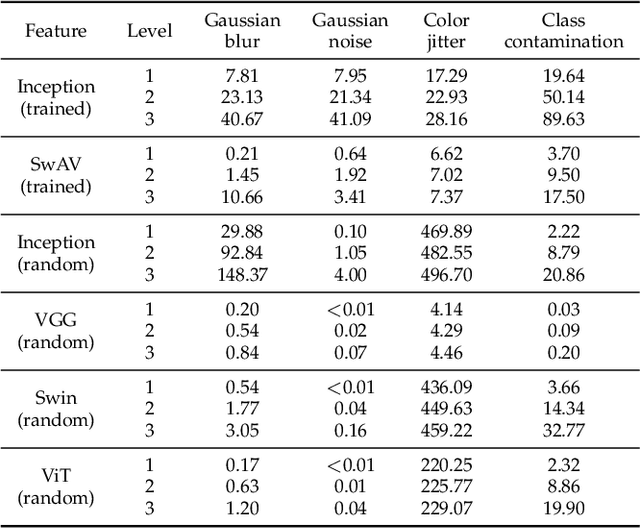

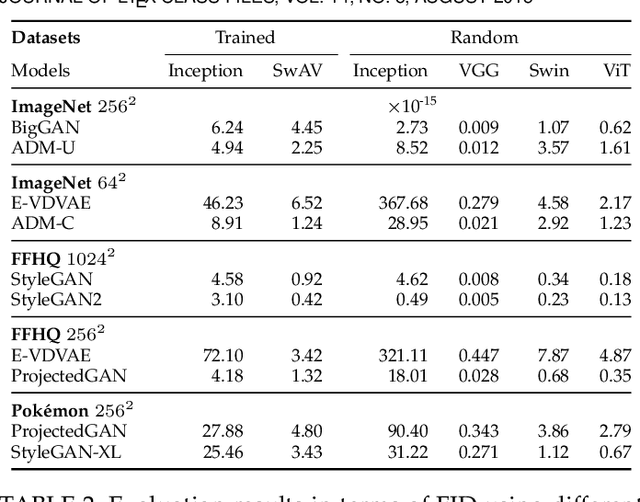
Evaluation of generative models is mostly based on the comparison between the estimated distribution and the ground truth distribution in a certain feature space. To embed samples into informative features, previous works often use convolutional neural networks optimized for classification, which is criticized by recent studies. Therefore, various feature spaces have been explored to discover alternatives. Among them, a surprising approach is to use a randomly initialized neural network for feature embedding. However, the fundamental basis to employ the random features has not been sufficiently justified. In this paper, we rigorously investigate the feature space of models with random weights in comparison to that of trained models. Furthermore, we provide an empirical evidence to choose networks for random features to obtain consistent and reliable results. Our results indicate that the features from random networks can evaluate generative models well similarly to those from trained networks, and furthermore, the two types of features can be used together in a complementary way.
TREND: Truncated Generalized Normal Density Estimation of Inception Embeddings for Accurate GAN Evaluation
Apr 30, 2021



Evaluating image generation models such as generative adversarial networks (GANs) is a challenging problem. A common approach is to compare the distributions of the set of ground truth images and the set of generated test images. The Frech\'et Inception distance is one of the most widely used metrics for evaluation of GANs, which assumes that the features from a trained Inception model for a set of images follow a normal distribution. In this paper, we argue that this is an over-simplified assumption, which may lead to unreliable evaluation results, and more accurate density estimation can be achieved using a truncated generalized normal distribution. Based on this, we propose a novel metric for accurate evaluation of GANs, named TREND (TRuncated gEneralized Normal Density estimation of inception embeddings). We demonstrate that our approach significantly reduces errors of density estimation, which consequently eliminates the risk of faulty evaluation results. Furthermore, we show that the proposed metric significantly improves robustness of evaluation results against variation of the number of image samples.
Wide Color Gamut Image Content Characterization: Method, Evaluation, and Applications
Jan 19, 2021

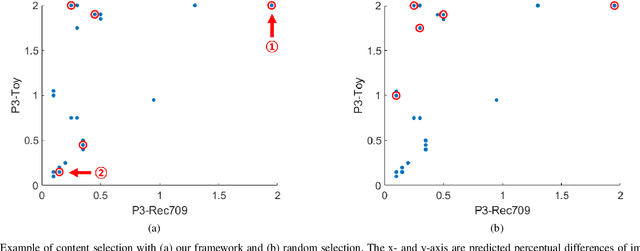

In this paper, we propose a novel framework to characterize a wide color gamut image content based on perceived quality due to the processes that change color gamut, and demonstrate two practical use cases where the framework can be applied. We first introduce the main framework and implementation details. Then, we provide analysis for understanding of existing wide color gamut datasets with quantitative characterization criteria on their characteristics, where four criteria, i.e., coverage, total coverage, uniformity, and total uniformity, are proposed. Finally, the framework is applied to content selection in a gamut mapping evaluation scenario in order to enhance reliability and robustness of the evaluation results. As a result, the framework fulfils content characterization for studies where quality of experience of wide color gamut stimuli is involved.
Ambiguity of Objective Image Quality Metrics: A New Methodology for Performance Evaluation
Jan 19, 2021
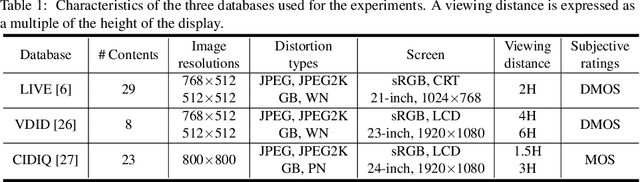
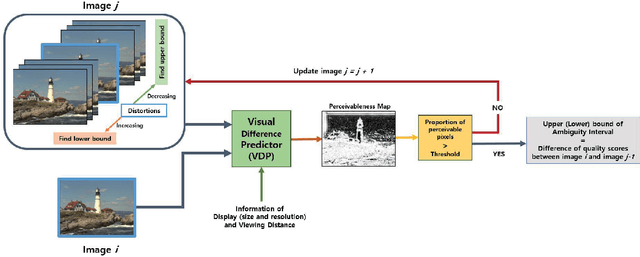
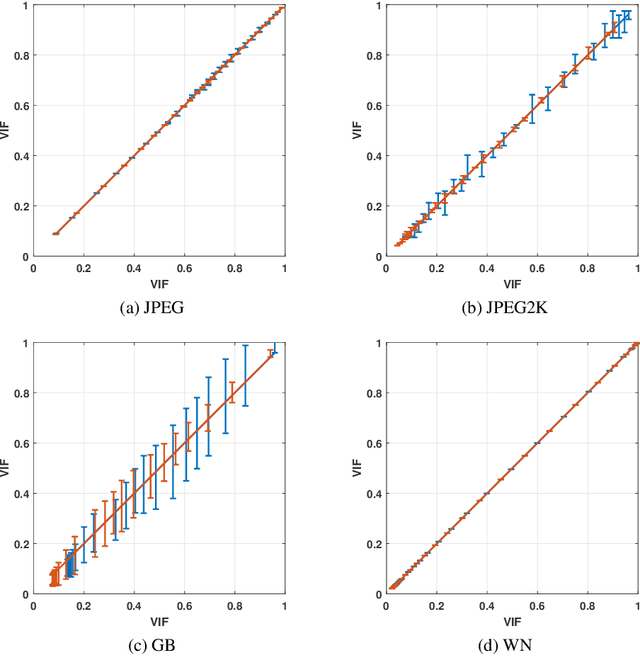
Objective image quality metrics try to estimate the perceptual quality of the given image by considering the characteristics of the human visual system. However, it is possible that the metrics produce different quality scores even for two images that are perceptually indistinguishable by human viewers, which have not been considered in the existing studies related to objective quality assessment. In this paper, we address the issue of ambiguity of objective image quality assessment. We propose an approach to obtain an ambiguity interval of an objective metric, within which the quality score difference is not perceptually significant. In particular, we use the visual difference predictor, which can consider viewing conditions that are important for visual quality perception. In order to demonstrate the usefulness of the proposed approach, we conduct experiments with 33 state-of-the-art image quality metrics in the viewpoint of their accuracy and ambiguity for three image quality databases. The results show that the ambiguity intervals can be applied as an additional figure of merit when conventional performance measurement does not determine superiority between the metrics. The effect of the viewing distance on the ambiguity interval is also shown.