 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOops, Wait: Token-Level Signals as a Lens into LLM Reasoning
Jan 24, 2026The emergence of discourse-like tokens such as "wait" and "therefore" in large language models (LLMs) has offered a unique window into their reasoning processes. However, systematic analyses of how such signals vary across training strategies and model scales remain lacking. In this paper, we analyze token-level signals through token probabilities across various models. We find that specific tokens strongly correlate with reasoning correctness, varying with training strategies while remaining stable across model scales. A closer look at the "wait" token in relation to answer probability demonstrates that models fine-tuned on small-scale datasets acquire reasoning ability through such signals but exploit them only partially. This work provides a systematic lens to observe and understand the dynamics of LLM reasoning.
What Defines Good Reasoning in LLMs? Dissecting Reasoning Steps with Multi-Aspect Evaluation
Oct 23, 2025
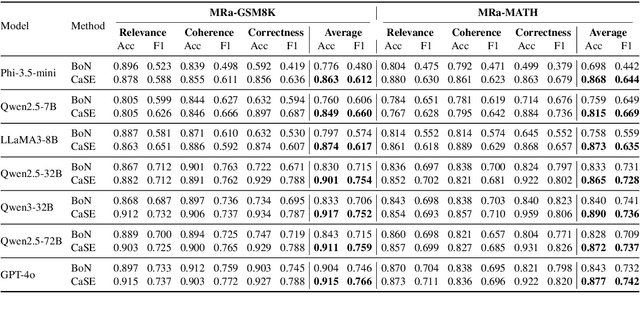
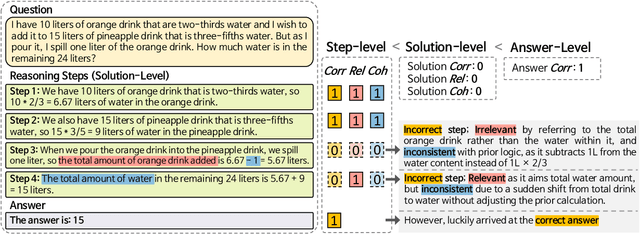
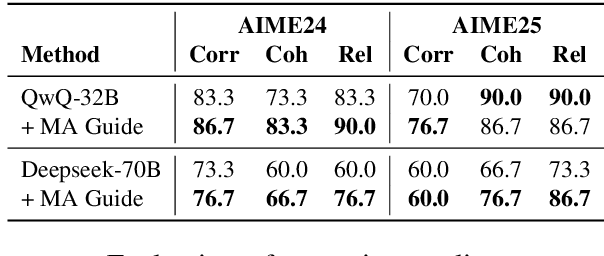
Evaluating large language models (LLMs) on final-answer correctness is the dominant paradigm. This approach, however, provides a coarse signal for model improvement and overlooks the quality of the underlying reasoning process. We argue that a more granular evaluation of reasoning offers a more effective path to building robust models. We decompose reasoning quality into two dimensions: relevance and coherence. Relevance measures if a step is grounded in the problem; coherence measures if it follows logically from prior steps. To measure these aspects reliably, we introduce causal stepwise evaluation (CaSE). This method assesses each reasoning step using only its preceding context, which avoids hindsight bias. We validate CaSE against human judgments on our new expert-annotated benchmarks, MRa-GSM8K and MRa-MATH. More importantly, we show that curating training data with CaSE-evaluated relevance and coherence directly improves final task performance. Our work provides a scalable framework for analyzing, debugging, and improving LLM reasoning, demonstrating the practical value of moving beyond validity checks.
CROPS: Model-Agnostic Training-Free Framework for Safe Image Synthesis with Latent Diffusion Models
Jan 09, 2025With advances in diffusion models, image generation has shown significant performance improvements. This raises concerns about the potential abuse of image generation, such as the creation of explicit or violent images, commonly referred to as Not Safe For Work (NSFW) content. To address this, the Stable Diffusion model includes several safety checkers to censor initial text prompts and final output images generated from the model. However, recent research has shown that these safety checkers have vulnerabilities against adversarial attacks, allowing them to generate NSFW images. In this paper, we find that these adversarial attacks are not robust to small changes in text prompts or input latents. Based on this, we propose CROPS (Circular or RandOm Prompts for Safety), a model-agnostic framework that easily defends against adversarial attacks generating NSFW images without requiring additional training. Moreover, we develop an approach that utilizes one-step diffusion models for efficient NSFW detection (CROPS-1), further reducing computational resources. We demonstrate the superiority of our method in terms of performance and applicability.
Anomaly Score: Evaluating Generative Models and Individual Generated Images based on Complexity and Vulnerability
Dec 17, 2023With the advancement of generative models, the assessment of generated images becomes more and more important. Previous methods measure distances between features of reference and generated images from trained vision models. In this paper, we conduct an extensive investigation into the relationship between the representation space and input space around generated images. We first propose two measures related to the presence of unnatural elements within images: complexity, which indicates how non-linear the representation space is, and vulnerability, which is related to how easily the extracted feature changes by adversarial input changes. Based on these, we introduce a new metric to evaluating image-generative models called anomaly score (AS). Moreover, we propose AS-i (anomaly score for individual images) that can effectively evaluate generated images individually. Experimental results demonstrate the validity of the proposed approach.
Similarity of Neural Architectures Based on Input Gradient Transferability
Oct 20, 2022
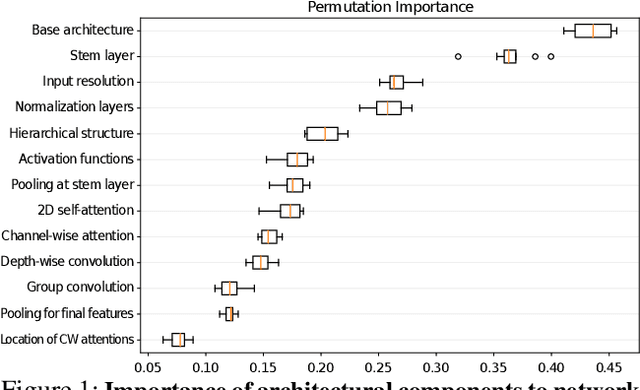
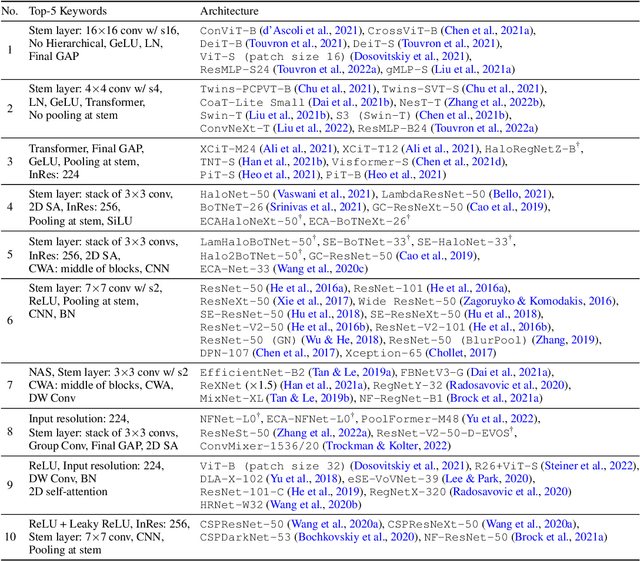
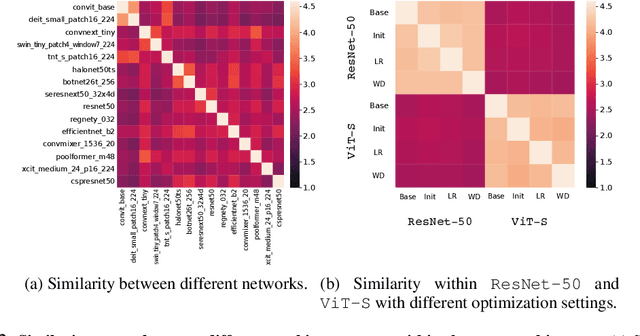
In this paper, we aim to design a quantitative similarity function between two neural architectures. Specifically, we define a model similarity using input gradient transferability. We generate adversarial samples of two networks and measure the average accuracy of the networks on adversarial samples of each other. If two networks are highly correlated, then the attack transferability will be high, resulting in high similarity. Using the similarity score, we investigate two topics: (1) Which network component contributes to the model diversity? (2) How does model diversity affect practical scenarios? We answer the first question by providing feature importance analysis and clustering analysis. The second question is validated by two different scenarios: model ensemble and knowledge distillation. Our findings show that model diversity takes a key role when interacting with different neural architectures. For example, we found that more diversity leads to better ensemble performance. We also observe that the relationship between teacher and student networks and distillation performance depends on the choice of the base architecture of the teacher and student networks. We expect our analysis tool helps a high-level understanding of differences between various neural architectures as well as practical guidance when using multiple architectures.
Temporal Shuffling for Defending Deep Action Recognition Models against Adversarial Attacks
Dec 15, 2021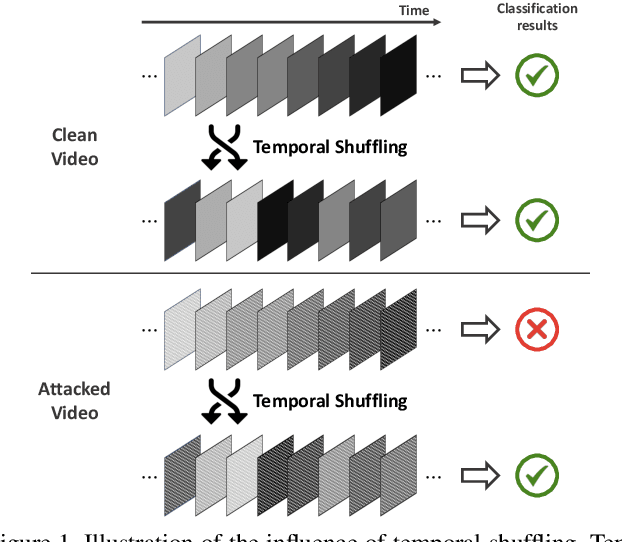
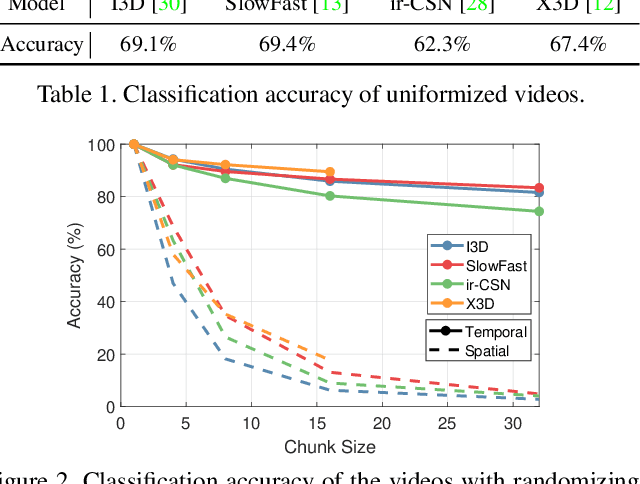
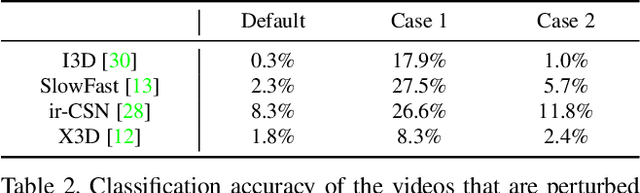

Recently, video-based action recognition methods using convolutional neural networks (CNNs) achieve remarkable recognition performance. However, there is still lack of understanding about the generalization mechanism of action recognition models. In this paper, we suggest that action recognition models rely on the motion information less than expected, and thus they are robust to randomization of frame orders. Based on this observation, we develop a novel defense method using temporal shuffling of input videos against adversarial attacks for action recognition models. Another observation enabling our defense method is that adversarial perturbations on videos are sensitive to temporal destruction. To the best of our knowledge, this is the first attempt to design a defense method specific to video-based action recognition models.
Just One Moment: Inconspicuous One Frame Attack on Deep Action Recognition
Nov 30, 2020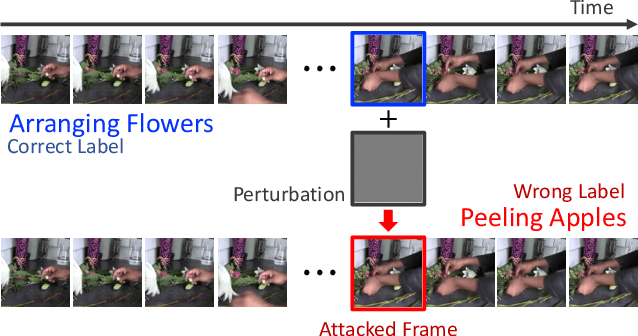
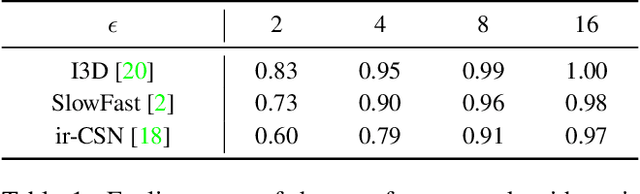
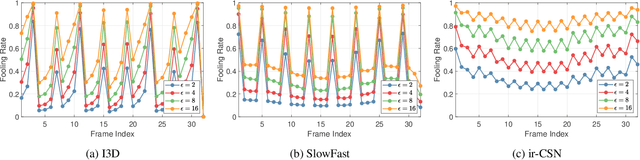
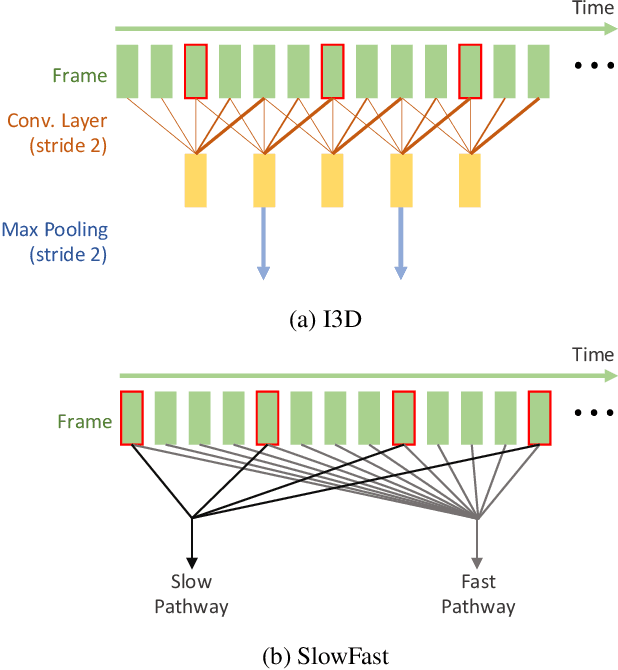
The video-based action recognition task has been extensively studied in recent years. In this paper, we study the vulnerability of deep learning-based action recognition methods against the adversarial attack using a new one frame attack that adds an inconspicuous perturbation to only a single frame of a given video clip. We investigate the effectiveness of our one frame attack on state-of-the-art action recognition models, along with thorough analysis of the vulnerability in terms of their model structure and perceivability of the perturbation. Our method shows high fooling rates and produces hardly perceivable perturbation to human observers, which is evaluated by a subjective test. In addition, we present a video-agnostic approach that finds a universal perturbation.