 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Shuffling for Defending Deep Action Recognition Models against Adversarial Attacks
Dec 15, 2021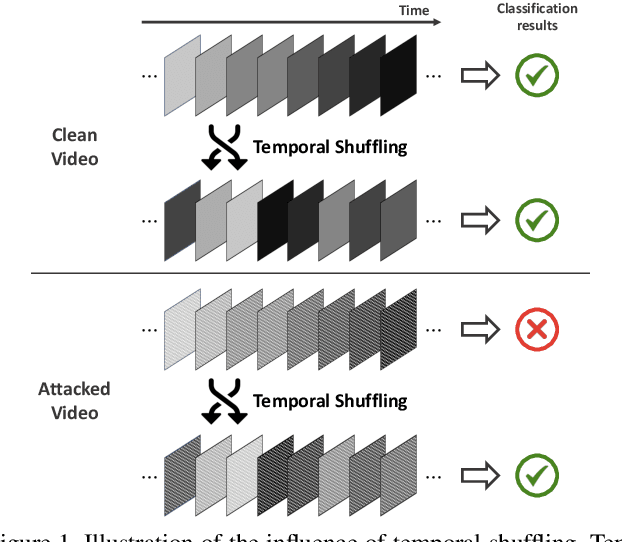
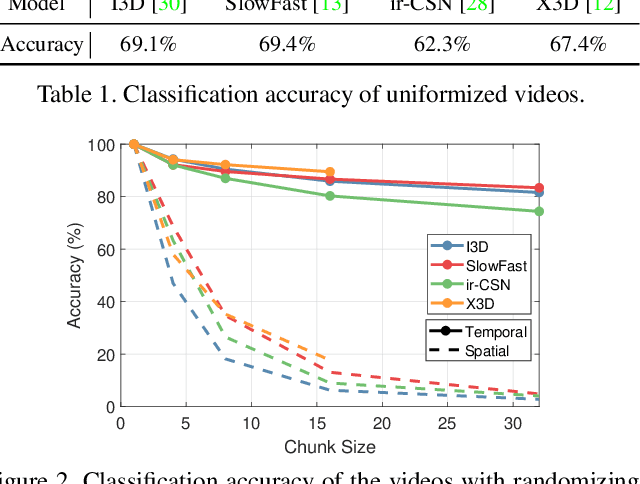
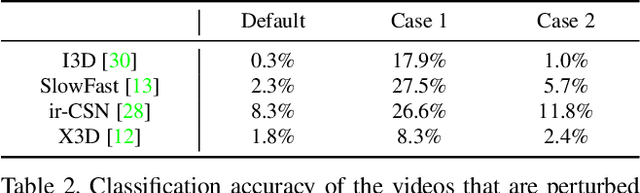

Recently, video-based action recognition methods using convolutional neural networks (CNNs) achieve remarkable recognition performance. However, there is still lack of understanding about the generalization mechanism of action recognition models. In this paper, we suggest that action recognition models rely on the motion information less than expected, and thus they are robust to randomization of frame orders. Based on this observation, we develop a novel defense method using temporal shuffling of input videos against adversarial attacks for action recognition models. Another observation enabling our defense method is that adversarial perturbations on videos are sensitive to temporal destruction. To the best of our knowledge, this is the first attempt to design a defense method specific to video-based action recognition models.
Amicable Aid: Turning Adversarial Attack to Benefit Classification
Dec 09, 2021
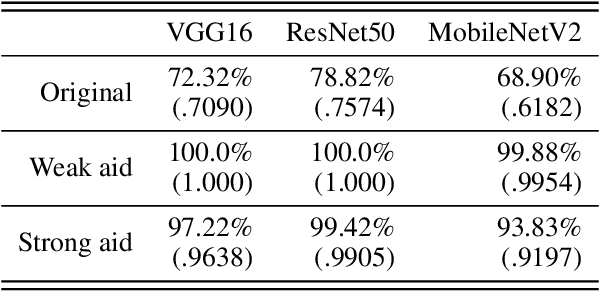
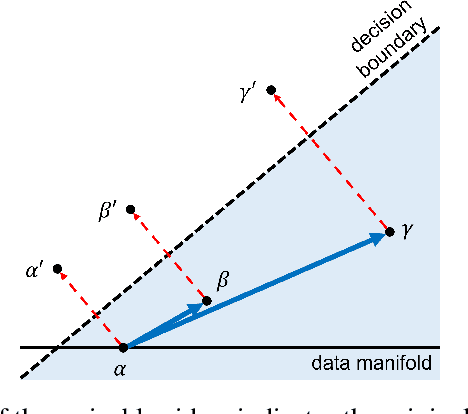
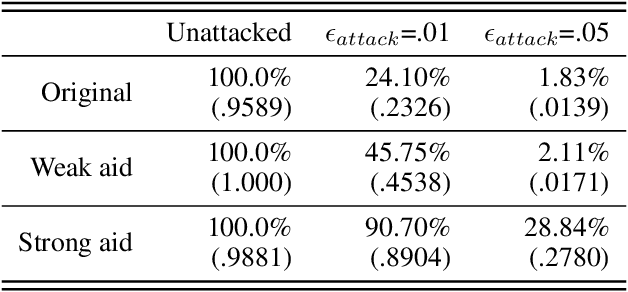
While adversarial attacks on deep image classification models pose serious security concerns in practice, this paper suggests a novel paradigm where the concept of adversarial attacks can benefit classification performance, which we call amicable aid. We show that by taking the opposite search direction of perturbation, an image can be converted to another yielding higher confidence by the classification model and even a wrongly classified image can be made to be correctly classified. Furthermore, with a large amount of perturbation, an image can be made unrecognizable by human eyes, while it is correctly recognized by the model. The mechanism of the amicable aid is explained in the viewpoint of the underlying natural image manifold. We also consider universal amicable perturbations, i.e., a fixed perturbation can be applied to multiple images to improve their classification results. While it is challenging to find such perturbations, we show that making the decision boundary as perpendicular to the image manifold as possible via training with modified data is effective to obtain a model for which universal amicable perturbations are more easily found. Finally, we discuss several application scenarios where the amicable aid can be useful, including secure image communication, privacy-preserving image communication, and protection against adversarial attacks.
Light Lies: Optical Adversarial Attack
Jul 14, 2021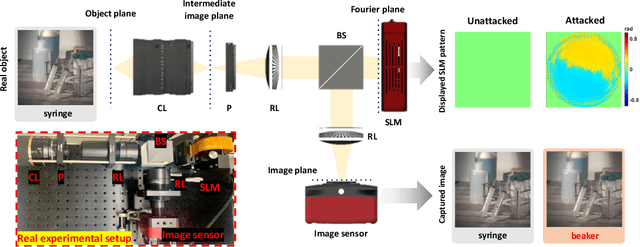

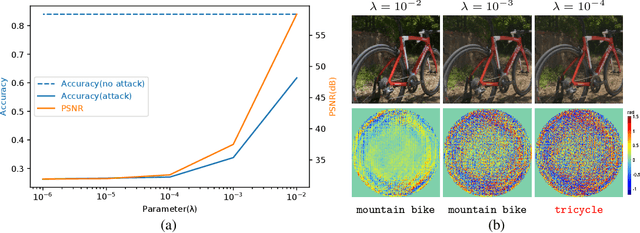
A significant amount of work has been done on adversarial attacks that inject imperceptible noise to images to deteriorate the image classification performance of deep models. However, most of the existing studies consider attacks in the digital (pixel) domain where an image acquired by an image sensor with sampling and quantization has been recorded. This paper, for the first time, introduces an optical adversarial attack, which physically alters the light field information arriving at the image sensor so that the classification model yields misclassification. More specifically, we modulate the phase of the light in the Fourier domain using a spatial light modulator placed in the photographic system. The operative parameters of the modulator are obtained by gradient-based optimization to maximize cross-entropy and minimize distortions. We present experiments based on both simulation and a real hardware optical system, from which the feasibility of the proposed optical attack is demonstrated. It is also verified that the proposed attack is completely different from common optical-domain distortions such as spherical aberration, defocus, and astigmatism in terms of both perturbation patterns and classification results.
Deep Image Destruction: A Comprehensive Study on Vulnerability of Deep Image-to-Image Models against Adversarial Attacks
Apr 30, 2021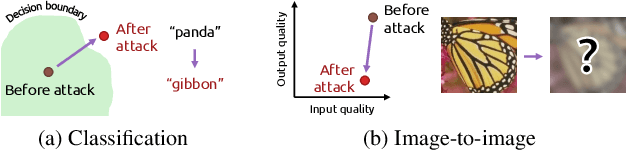
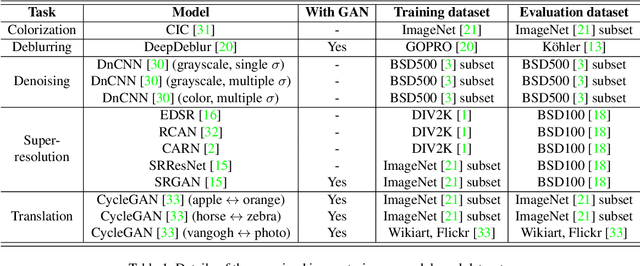
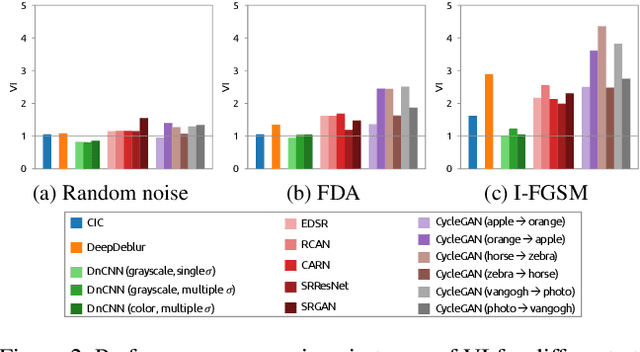

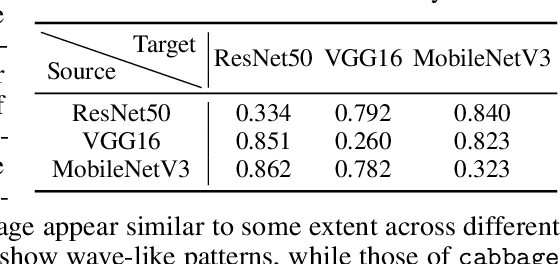
Recently, the vulnerability of deep image classification models to adversarial attacks has been investigated. However, such an issue has not been thoroughly studied for image-to-image models that can have different characteristics in quantitative evaluation, consequences of attacks, and defense strategy. To tackle this, we present comprehensive investigations into the vulnerability of deep image-to-image models to adversarial attacks. For five popular image-to-image tasks, 16 deep models are analyzed from various standpoints such as output quality degradation due to attacks, transferability of adversarial examples across different tasks, and characteristics of perturbations. We show that unlike in image classification tasks, the performance degradation on image-to-image tasks can largely differ depending on various factors, e.g., attack methods and task objectives. In addition, we analyze the effectiveness of conventional defense methods used for classification models in improving the robustness of the image-to-image models.
Just One Moment: Inconspicuous One Frame Attack on Deep Action Recognition
Nov 30, 2020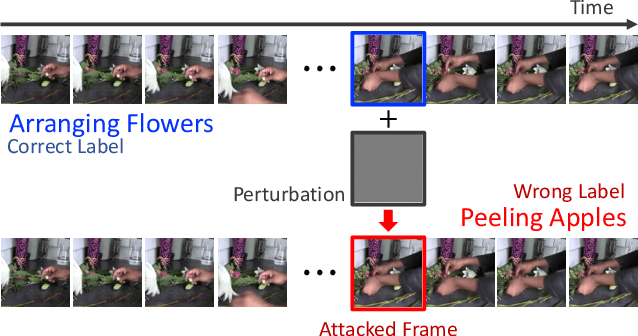
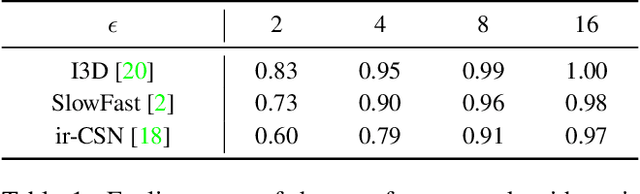
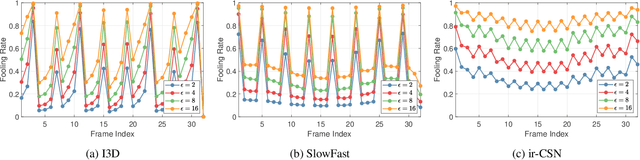
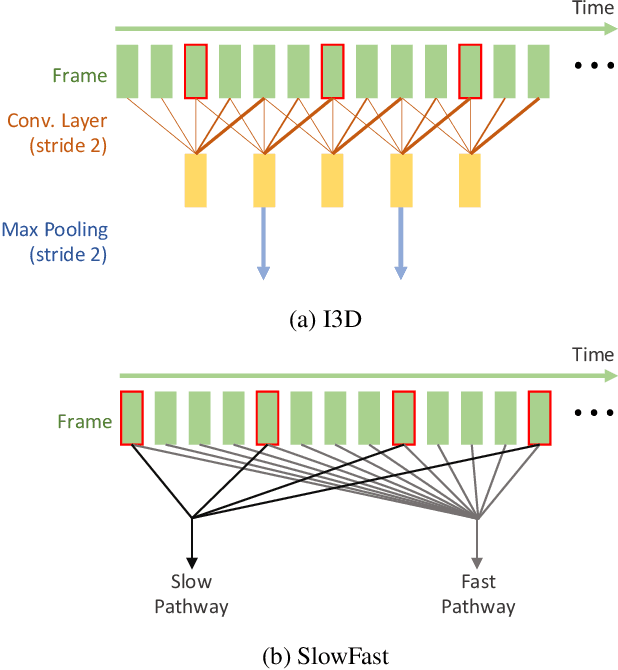
The video-based action recognition task has been extensively studied in recent years. In this paper, we study the vulnerability of deep learning-based action recognition methods against the adversarial attack using a new one frame attack that adds an inconspicuous perturbation to only a single frame of a given video clip. We investigate the effectiveness of our one frame attack on state-of-the-art action recognition models, along with thorough analysis of the vulnerability in terms of their model structure and perceivability of the perturbation. Our method shows high fooling rates and produces hardly perceivable perturbation to human observers, which is evaluated by a subjective test. In addition, we present a video-agnostic approach that finds a universal perturbation.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020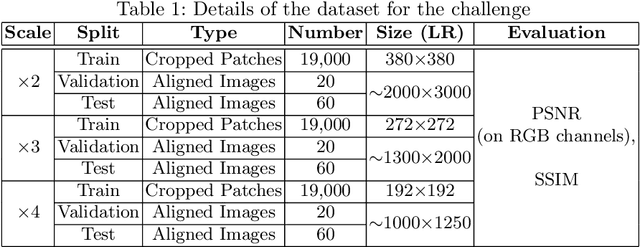
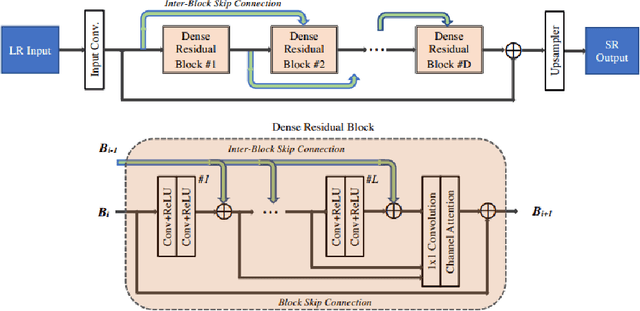
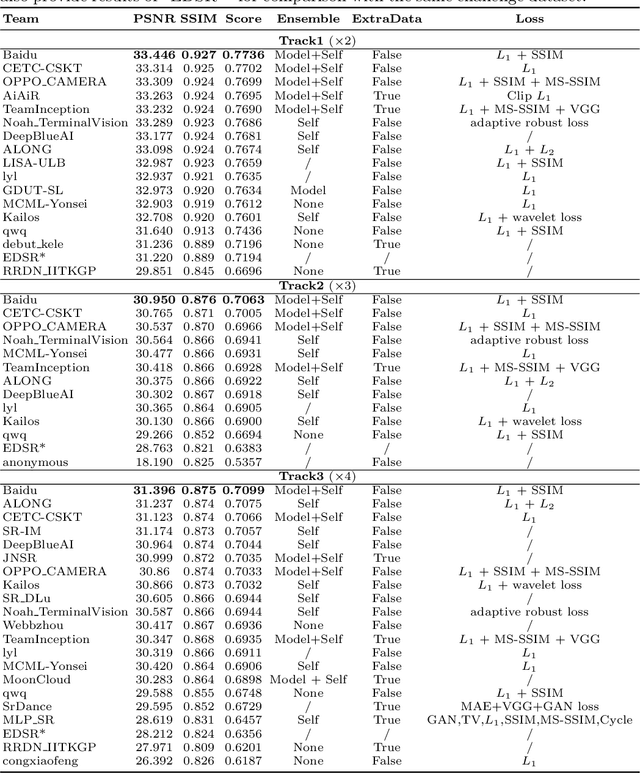
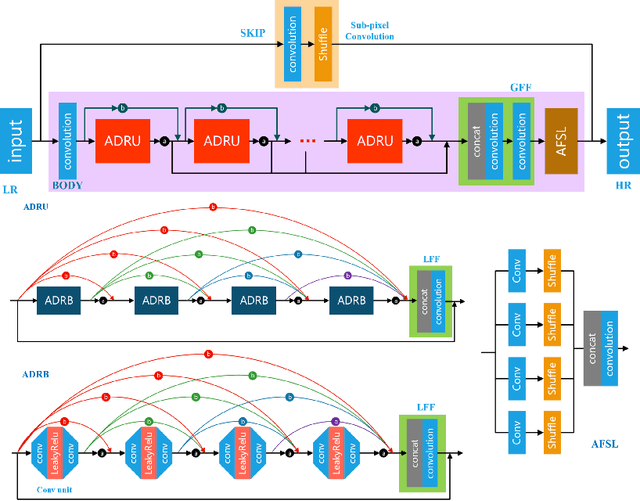
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020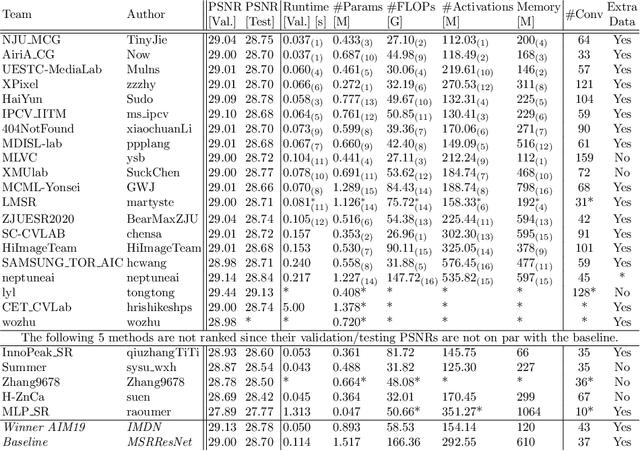
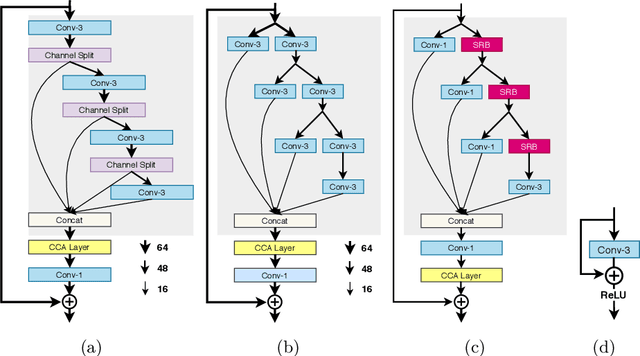
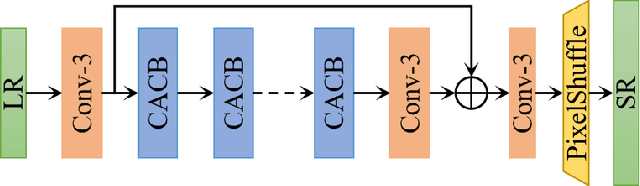
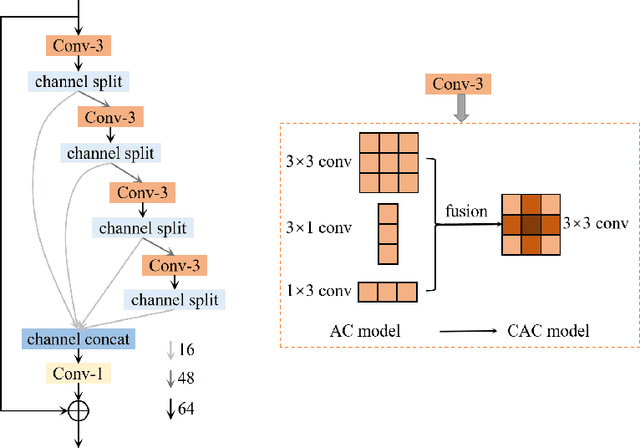
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
EmbraceNet for Activity: A Deep Multimodal Fusion Architecture for Activity Recognition
Apr 29, 2020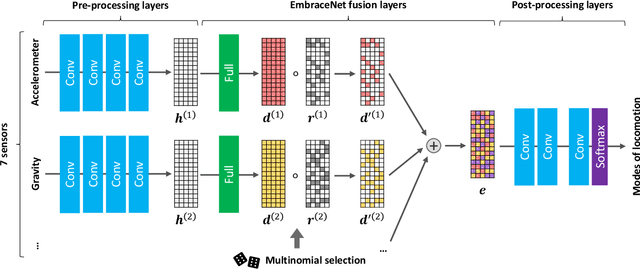
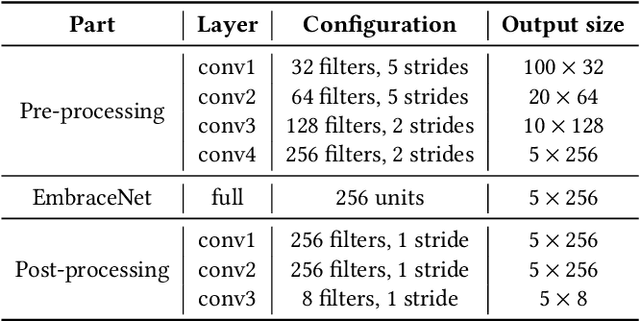
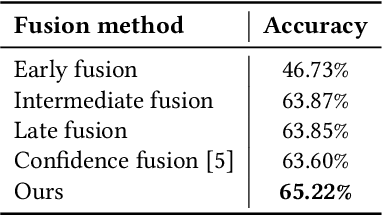

Human activity recognition using multiple sensors is a challenging but promising task in recent decades. In this paper, we propose a deep multimodal fusion model for activity recognition based on the recently proposed feature fusion architecture named EmbraceNet. Our model processes each sensor data independently, combines the features with the EmbraceNet architecture, and post-processes the fused feature to predict the activity. In addition, we propose additional processes to boost the performance of our model. We submit the results obtained from our proposed model to the SHL recognition challenge with the team name "Yonsei-MCML."
EmbraceNet: A robust deep learning architecture for multimodal classification
Apr 19, 2019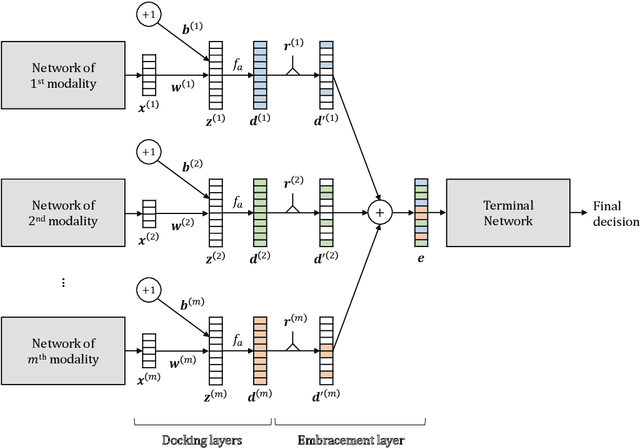
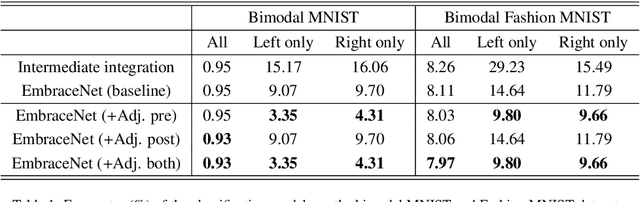
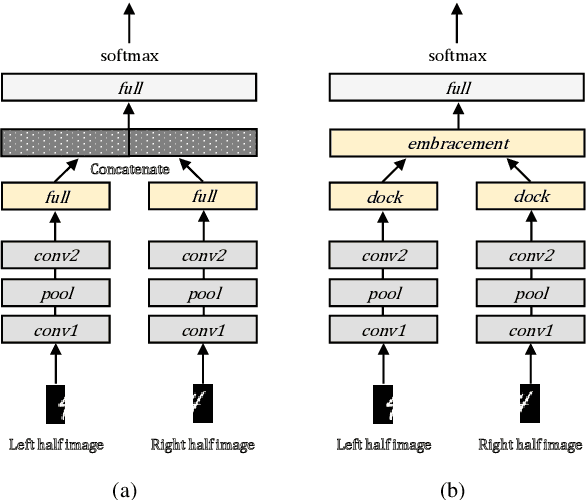
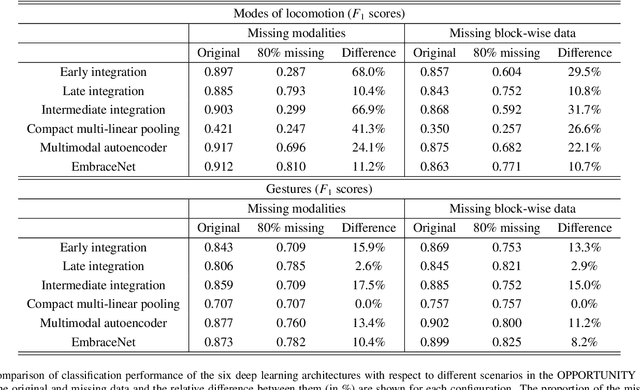
Classification using multimodal data arises in many machine learning applications. It is crucial not only to model cross-modal relationship effectively but also to ensure robustness against loss of part of data or modalities. In this paper, we propose a novel deep learning-based multimodal fusion architecture for classification tasks, which guarantees compatibility with any kind of learning models, deals with cross-modal information carefully, and prevents performance degradation due to partial absence of data. We employ two datasets for multimodal classification tasks, build models based on our architecture and other state-of-the-art models, and analyze their performance on various situations. The results show that our architecture outperforms the other multimodal fusion architectures when some parts of data are not available.
* Code available at https://github.com/idearibosome/embracenet
Evaluating Robustness of Deep Image Super-Resolution against Adversarial Attacks
Apr 12, 2019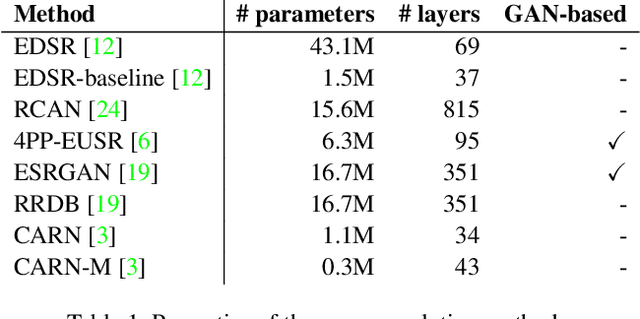
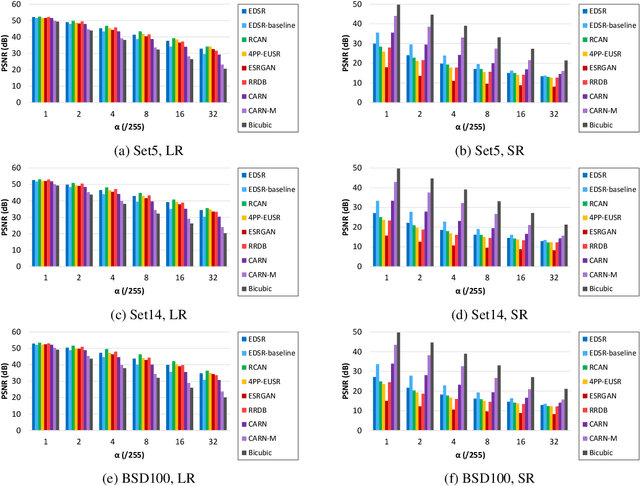

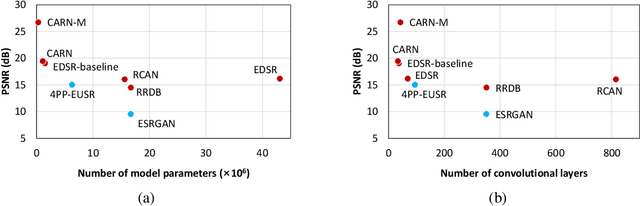
Single-image super-resolution aims to generate a high-resolution version of a low-resolution image, which serves as an essential component in many computer vision applications. This paper investigates the robustness of deep learning-based super-resolution methods against adversarial attacks, which can significantly deteriorate the super-resolved images without noticeable distortion in the attacked low-resolution images. It is demonstrated that state-of-the-art deep super-resolution methods are highly vulnerable to adversarial attacks. Different levels of robustness of different methods are analyzed theoretically and experimentally. We also present analysis on transferability of attacks, and feasibility of targeted attacks and universal attacks.