 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmicable Aid: Turning Adversarial Attack to Benefit Classification
Paper and Code
Dec 09, 2021
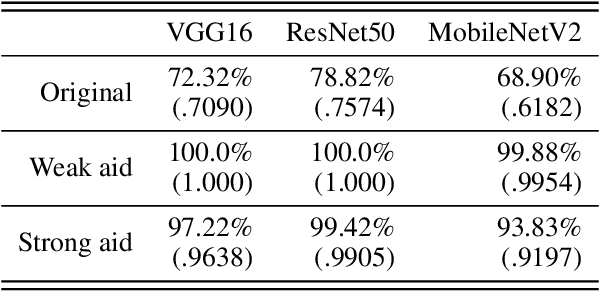
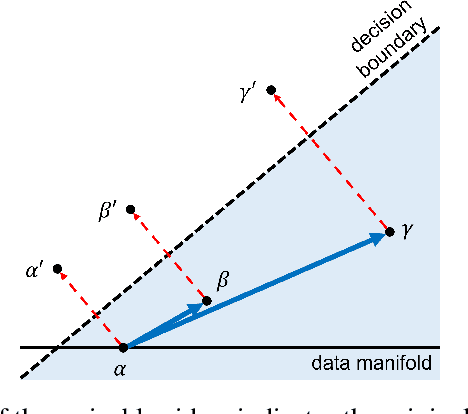
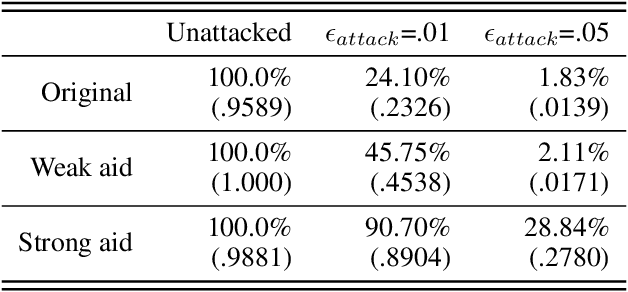
While adversarial attacks on deep image classification models pose serious security concerns in practice, this paper suggests a novel paradigm where the concept of adversarial attacks can benefit classification performance, which we call amicable aid. We show that by taking the opposite search direction of perturbation, an image can be converted to another yielding higher confidence by the classification model and even a wrongly classified image can be made to be correctly classified. Furthermore, with a large amount of perturbation, an image can be made unrecognizable by human eyes, while it is correctly recognized by the model. The mechanism of the amicable aid is explained in the viewpoint of the underlying natural image manifold. We also consider universal amicable perturbations, i.e., a fixed perturbation can be applied to multiple images to improve their classification results. While it is challenging to find such perturbations, we show that making the decision boundary as perpendicular to the image manifold as possible via training with modified data is effective to obtain a model for which universal amicable perturbations are more easily found. Finally, we discuss several application scenarios where the amicable aid can be useful, including secure image communication, privacy-preserving image communication, and protection against adversarial attacks.