 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Learned Image Compression for Machine Perception
Dec 23, 2025Recent advances in learned image codecs have been extended from human perception toward machine perception. However, progressive image compression with fine granular scalability (FGS)-which enables decoding a single bitstream at multiple quality levels-remains unexplored for machine-oriented codecs. In this work, we propose a novel progressive learned image compression codec for machine perception, PICM-Net, based on trit-plane coding. By analyzing the difference between human- and machine-oriented rate-distortion priorities, we systematically examine the latent prioritization strategies in terms of machine-oriented codecs. To further enhance real-world adaptability, we design an adaptive decoding controller, which dynamically determines the necessary decoding level during inference time to maintain the desired confidence of downstream machine prediction. Extensive experiments demonstrate that our approach enables efficient and adaptive progressive transmission while maintaining high performance in the downstream classification task, establishing a new paradigm for machine-aware progressive image compression.
Multi-view Pyramid Transformer: Look Coarser to See Broader
Dec 08, 2025
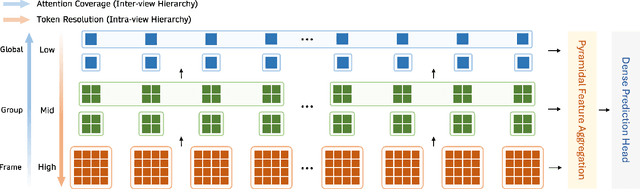
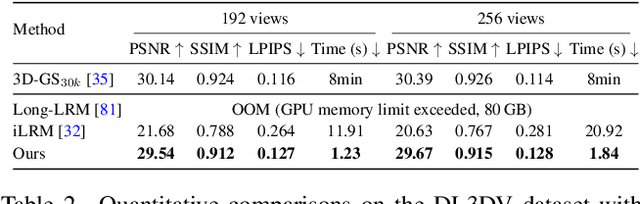

We propose Multi-view Pyramid Transformer (MVP), a scalable multi-view transformer architecture that directly reconstructs large 3D scenes from tens to hundreds of images in a single forward pass. Drawing on the idea of ``looking broader to see the whole, looking finer to see the details," MVP is built on two core design principles: 1) a local-to-global inter-view hierarchy that gradually broadens the model's perspective from local views to groups and ultimately the full scene, and 2) a fine-to-coarse intra-view hierarchy that starts from detailed spatial representations and progressively aggregates them into compact, information-dense tokens. This dual hierarchy achieves both computational efficiency and representational richness, enabling fast reconstruction of large and complex scenes. We validate MVP on diverse datasets and show that, when coupled with 3D Gaussian Splatting as the underlying 3D representation, it achieves state-of-the-art generalizable reconstruction quality while maintaining high efficiency and scalability across a wide range of view configurations.
Streaming Tensor Program: A streaming abstraction for dynamic parallelism
Nov 11, 2025
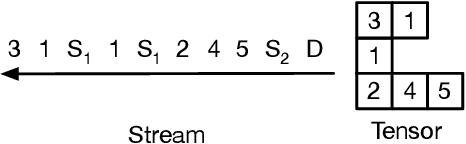
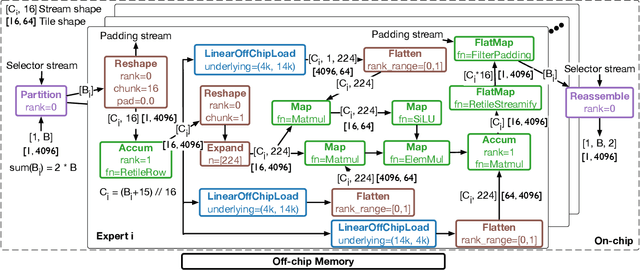

Dynamic behaviors are becoming prevalent in many tensor applications. In machine learning, for example, the input tensors are dynamically shaped or ragged, and data-dependent control flow is widely used in many models. However, the limited expressiveness of prior programming abstractions for spatial dataflow accelerators forces the dynamic behaviors to be implemented statically or lacks the visibility for performance-critical decisions. To address these challenges, we present the Streaming Tensor Program (STeP), a new streaming abstraction that enables dynamic tensor workloads to run efficiently on spatial dataflow accelerators. STeP introduces flexible routing operators, an explicit memory hierarchy, and symbolic shape semantics that expose dynamic data rates and tensor dimensions. These capabilities unlock new optimizations-dynamic tiling, dynamic parallelization, and configuration time-multiplexing-that adapt to dynamic behaviors while preserving dataflow efficiency. Using a cycle-approximate simulator on representative LLM layers with real-world traces, dynamic tiling reduces on-chip memory requirement by 2.18x, dynamic parallelization improves latency by 1.5x, and configuration time-multiplexing improves compute utilization by 2.57x over implementations available in prior abstractions.
Rethinking Caching for LLM Serving Systems: Beyond Traditional Heuristics
Aug 26, 2025Serving Large Language Models (LLMs) at scale requires meeting strict Service Level Objectives (SLOs) under severe computational and memory constraints. Nevertheless, traditional caching strategies fall short: exact-matching and prefix caches neglect query semantics, while state-of-the-art semantic caches remain confined to traditional intuitions, offering little conceptual departure. Building on this, we present SISO, a semantic caching system that redefines efficiency for LLM serving. SISO introduces centroid-based caching to maximize coverage with minimal memory, locality-aware replacement to preserve high-value entries, and dynamic thresholding to balance accuracy and latency under varying workloads. Across diverse datasets, SISO delivers up to 1.71$\times$ higher hit ratios and consistently stronger SLO attainment compared to state-of-the-art systems.
Exploring Cross-Stage Adversarial Transferability in Class-Incremental Continual Learning
Aug 12, 2025Class-incremental continual learning addresses catastrophic forgetting by enabling classification models to preserve knowledge of previously learned classes while acquiring new ones. However, the vulnerability of the models against adversarial attacks during this process has not been investigated sufficiently. In this paper, we present the first exploration of vulnerability to stage-transferred attacks, i.e., an adversarial example generated using the model in an earlier stage is used to attack the model in a later stage. Our findings reveal that continual learning methods are highly susceptible to these attacks, raising a serious security issue. We explain this phenomenon through model similarity between stages and gradual robustness degradation. Additionally, we find that existing adversarial training-based defense methods are not sufficiently effective to stage-transferred attacks. Codes are available at https://github.com/mcml-official/CSAT.
Targetless LiDAR-Camera Calibration with Anchored 3D Gaussians
Apr 06, 2025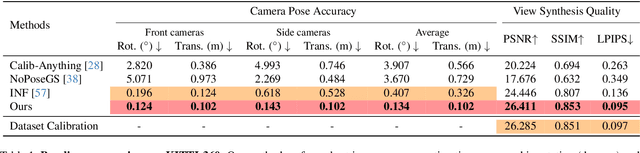
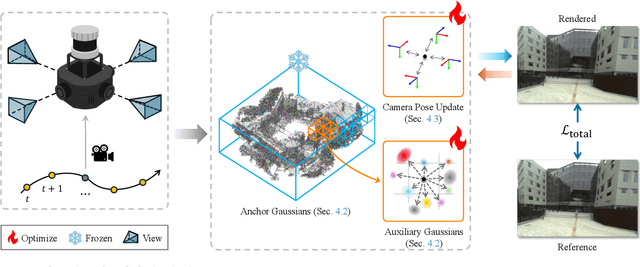

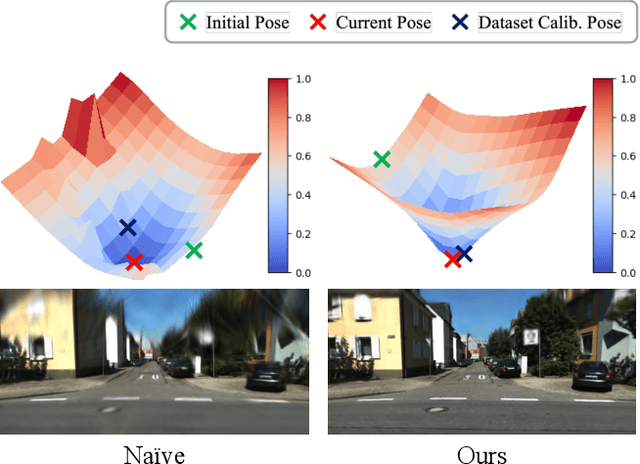
We present a targetless LiDAR-camera calibration method that jointly optimizes sensor poses and scene geometry from arbitrary scenes, without relying on traditional calibration targets such as checkerboards or spherical reflectors. Our approach leverages a 3D Gaussian-based scene representation. We first freeze reliable LiDAR points as anchors, then jointly optimize the poses and auxiliary Gaussian parameters in a fully differentiable manner using a photometric loss. This joint optimization significantly reduces sensor misalignment, resulting in higher rendering quality and consistently improved PSNR compared to the carefully calibrated poses provided in popular datasets. We validate our method through extensive experiments on two real-world autonomous driving datasets, KITTI-360 and Waymo, each featuring distinct sensor configurations. Additionally, we demonstrate the robustness of our approach using a custom LiDAR-camera setup, confirming strong performance across diverse hardware configurations.
SeDi-Instruct: Enhancing Alignment of Language Models through Self-Directed Instruction Generation
Feb 07, 2025The rapid evolution of Large Language Models (LLMs) has enabled the industry to develop various AI-based services. Instruction tuning is considered essential in adapting foundation models for target domains to provide high-quality services to customers. A key challenge in instruction tuning is obtaining high-quality instruction data. Self-Instruct, which automatically generates instruction data using ChatGPT APIs, alleviates the data scarcity problem. To improve the quality of instruction data, Self-Instruct discards many of the instructions generated from ChatGPT, even though it is inefficient in terms of cost owing to many useless API calls. To generate high-quality instruction data at a low cost, we propose a novel data generation framework, Self-Direct Instruction generation (SeDi-Instruct), which employs diversity-based filtering and iterative feedback task generation. Diversity-based filtering maintains model accuracy without excessively discarding low-quality generated instructions by enhancing the diversity of instructions in a batch. This reduces the cost of synthesizing instruction data. The iterative feedback task generation integrates instruction generation and training tasks and utilizes information obtained during the training to create high-quality instruction sets. Our results show that SeDi-Instruct enhances the accuracy of AI models by 5.2%, compared with traditional methods, while reducing data generation costs by 36%.
Systematic Review on Healthcare Systems Engineering utilizing ChatGPT
May 20, 2024This paper presents an analytical framework for conducting academic reviews in the field of Healthcare Systems Engineering, employing ChatGPT, a state-of-the-art tool among recent language models. We utilized 9,809 abstract paragraphs from conference presentations to systematically review the field. The framework comprises distinct analytical processes, each employing tailored prompts and the systematic use of the ChatGPT API. Through this framework, we organized the target field into 11 topic categories and conducted a comprehensive analysis covering quantitative yearly trends and detailed sub-categories. This effort explores the potential for leveraging ChatGPT to alleviate the burden of academic reviews. Furthermore, it provides valuable insights into the dynamic landscape of Healthcare Systems Engineering research.
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024



Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.