 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlowQ: Group-Shared LOw-Rank Approximation for Quantized LLMs
Mar 26, 2026Quantization techniques such as BitsAndBytes, AWQ, and GPTQ are widely used as a standard method in deploying large language models but often degrades accuracy when using low-bit representations, e.g., 4 bits. Low-rank correction methods (e.g., LQER, QERA, ASER) has been proposed to mitigate this issue, however, they restore all layers and insert error-correction modules into every decoder block, which increases latency and memory overhead. To address this limitation, we propose GlowQ, a group-shared low-rank approximation for quantized LLMs that caches a single shared right factor per input-sharing group and restores only the groups or layers that yield the highest accuracy benefit. GlowQ computes the high-precision projection once per input-sharing group and reuses it across its modules, reducing parameter and memory overhead, and retaining the expressivity of layer-specific corrections. We also propose a selective variant, GlowQ-S, that applies the cached shared module only where it provides the largest benefit. Compared with strong baselines, our approach reduces TTFB by (5.6%) and increases throughput by (9.6%) on average, while reducing perplexity on WikiText-2 by (0.17%) and increasing downstream accuracy by 0.42 percentage points. The selective model GlowQ-S further reduces latency, cutting TTFB by (23.4%) and increasing throughput by (37.4%), while maintaining accuracy within 0.2 percentage points on average.
Rethinking Caching for LLM Serving Systems: Beyond Traditional Heuristics
Aug 26, 2025Serving Large Language Models (LLMs) at scale requires meeting strict Service Level Objectives (SLOs) under severe computational and memory constraints. Nevertheless, traditional caching strategies fall short: exact-matching and prefix caches neglect query semantics, while state-of-the-art semantic caches remain confined to traditional intuitions, offering little conceptual departure. Building on this, we present SISO, a semantic caching system that redefines efficiency for LLM serving. SISO introduces centroid-based caching to maximize coverage with minimal memory, locality-aware replacement to preserve high-value entries, and dynamic thresholding to balance accuracy and latency under varying workloads. Across diverse datasets, SISO delivers up to 1.71$\times$ higher hit ratios and consistently stronger SLO attainment compared to state-of-the-art systems.
FineScope : Precision Pruning for Domain-Specialized Large Language Models Using SAE-Guided Self-Data Cultivation
May 01, 2025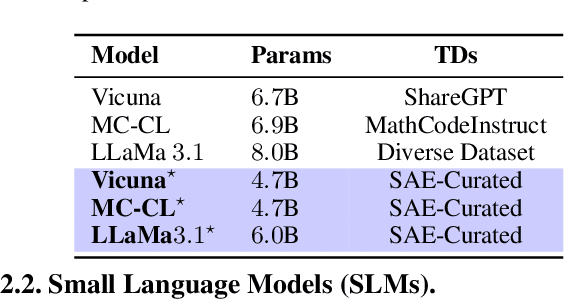

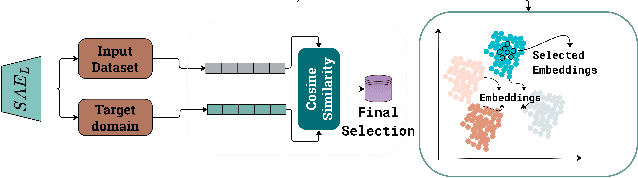

Training large language models (LLMs) from scratch requires significant computational resources, driving interest in developing smaller, domain-specific LLMs that maintain both efficiency and strong task performance. Medium-sized models such as LLaMA, llama} have served as starting points for domain-specific adaptation, but they often suffer from accuracy degradation when tested on specialized datasets. We introduce FineScope, a framework for deriving compact, domain-optimized LLMs from larger pretrained models. FineScope leverages the Sparse Autoencoder (SAE) framework, inspired by its ability to produce interpretable feature representations, to extract domain-specific subsets from large datasets. We apply structured pruning with domain-specific constraints, ensuring that the resulting pruned models retain essential knowledge for the target domain. To further enhance performance, these pruned models undergo self-data distillation, leveraging SAE-curated datasets to restore key domain-specific information lost during pruning. Extensive experiments and ablation studies demonstrate that FineScope achieves highly competitive performance, outperforming several large-scale state-of-the-art LLMs in domain-specific tasks. Additionally, our results show that FineScope enables pruned models to regain a substantial portion of their original performance when fine-tuned with SAE-curated datasets. Furthermore, applying these datasets to fine-tune pretrained LLMs without pruning also improves their domain-specific accuracy, highlighting the robustness of our approach. The code will be released.
Exploiting Boosting in Hyperdimensional Computing for Enhanced Reliability in Healthcare
Nov 21, 2024Hyperdimensional computing (HDC) enables efficient data encoding and processing in high-dimensional space, benefiting machine learning and data analysis. However, underutilization of these spaces can lead to overfitting and reduced model reliability, especially in data-limited systems a critical issue in sectors like healthcare that demand robustness and consistent performance. We introduce BoostHD, an approach that applies boosting algorithms to partition the hyperdimensional space into subspaces, creating an ensemble of weak learners. By integrating boosting with HDC, BoostHD enhances performance and reliability beyond existing HDC methods. Our analysis highlights the importance of efficient utilization of hyperdimensional spaces for improved model performance. Experiments on healthcare datasets show that BoostHD outperforms state-of-the-art methods. On the WESAD dataset, it achieved an accuracy of 98.37%, surpassing Random Forest, XGBoost, and OnlineHD. BoostHD also demonstrated superior inference efficiency and stability, maintaining high accuracy under data imbalance and noise. In person-specific evaluations, it achieved an average accuracy of 96.19%, outperforming other models. By addressing the limitations of both boosting and HDC, BoostHD expands the applicability of HDC in critical domains where reliability and precision are paramount.
QHD: A brain-inspired hyperdimensional reinforcement learning algorithm
May 14, 2022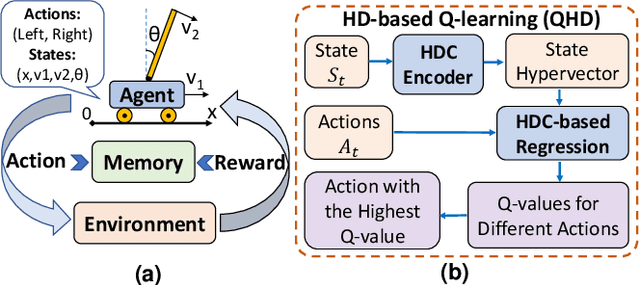
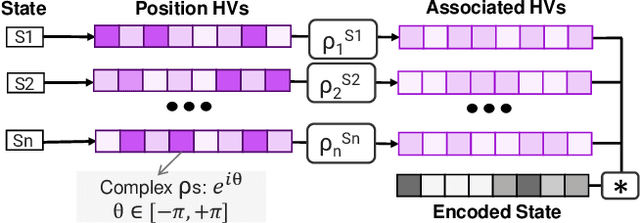
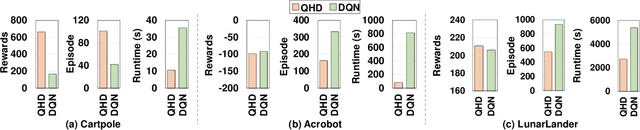
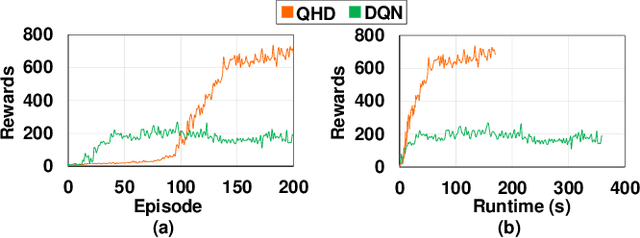
Reinforcement Learning (RL) has opened up new opportunities to solve a wide range of complex decision-making tasks. However, modern RL algorithms, e.g., Deep Q-Learning, are based on deep neural networks, putting high computational costs when running on edge devices. In this paper, we propose QHD, a Hyperdimensional Reinforcement Learning, that mimics brain properties toward robust and real-time learning. QHD relies on a lightweight brain-inspired model to learn an optimal policy in an unknown environment. We first develop a novel mathematical foundation and encoding module that maps state-action space into high-dimensional space. We accordingly develop a hyperdimensional regression model to approximate the Q-value function. The QHD-powered agent makes decisions by comparing Q-values of each possible action. We evaluate the effect of the different RL training batch sizes and local memory capacity on the QHD quality of learning. Our QHD is also capable of online learning with tiny local memory capacity, which can be as small as the training batch size. QHD provides real-time learning by further decreasing the memory capacity and the batch size. This makes QHD suitable for highly-efficient reinforcement learning in the edge environment, where it is crucial to support online and real-time learning. Our solution also supports a small experience replay batch size that provides 12.3 times speedup compared to DQN while ensuring minimal quality loss. Our evaluation shows QHD capability for real-time learning, providing 34.6 times speedup and significantly better quality of learning than state-of-the-art deep RL algorithms.
DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression
Feb 17, 2022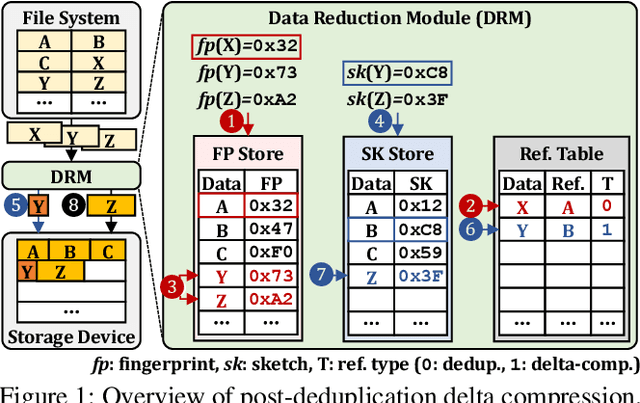
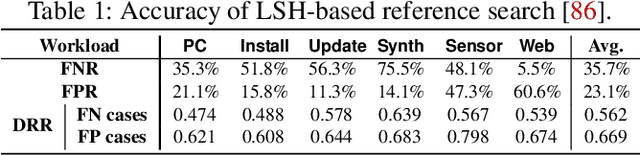
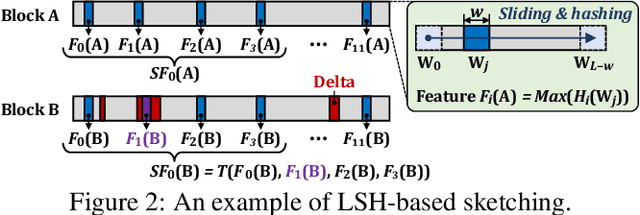
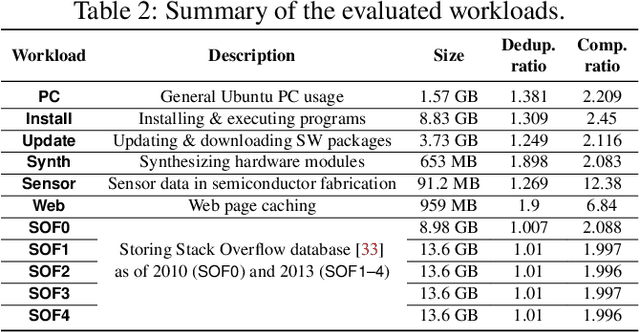
Data reduction in storage systems is becoming increasingly important as an effective solution to minimize the management cost of a data center. To maximize data-reduction efficiency, existing post-deduplication delta-compression techniques perform delta compression along with traditional data deduplication and lossless compression. Unfortunately, we observe that existing techniques achieve significantly lower data-reduction ratios than the optimal due to their limited accuracy in identifying similar data blocks. In this paper, we propose DeepSketch, a new reference search technique for post-deduplication delta compression that leverages the learning-to-hash method to achieve higher accuracy in reference search for delta compression, thereby improving data-reduction efficiency. DeepSketch uses a deep neural network to extract a data block's sketch, i.e., to create an approximate data signature of the block that can preserve similarity with other blocks. Our evaluation using eleven real-world workloads shows that DeepSketch improves the data-reduction ratio by up to 33% (21% on average) over a state-of-the-art post-deduplication delta-compression technique.
Spiking Hyperdimensional Network: Neuromorphic Models Integrated with Memory-Inspired Framework
Oct 01, 2021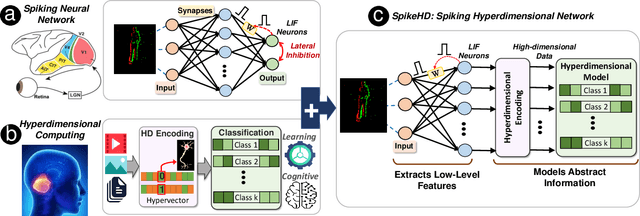
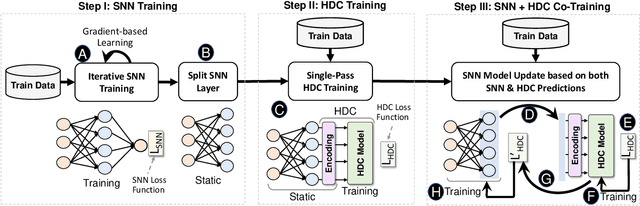
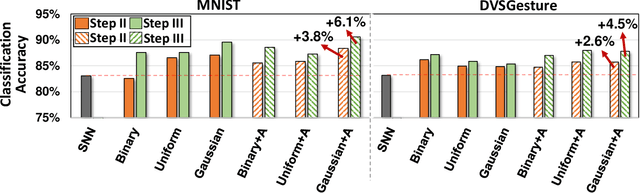
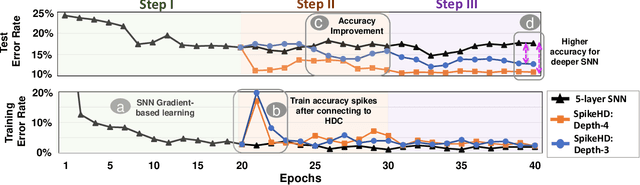
Recently, brain-inspired computing models have shown great potential to outperform today's deep learning solutions in terms of robustness and energy efficiency. Particularly, Spiking Neural Networks (SNNs) and HyperDimensional Computing (HDC) have shown promising results in enabling efficient and robust cognitive learning. Despite the success, these two brain-inspired models have different strengths. While SNN mimics the physical properties of the human brain, HDC models the brain on a more abstract and functional level. Their design philosophies demonstrate complementary patterns that motivate their combination. With the help of the classical psychological model on memory, we propose SpikeHD, the first framework that fundamentally combines Spiking neural network and hyperdimensional computing. SpikeHD generates a scalable and strong cognitive learning system that better mimics brain functionality. SpikeHD exploits spiking neural networks to extract low-level features by preserving the spatial and temporal correlation of raw event-based spike data. Then, it utilizes HDC to operate over SNN output by mapping the signal into high-dimensional space, learning the abstract information, and classifying the data. Our extensive evaluation on a set of benchmark classification problems shows that SpikeHD provides the following benefit compared to SNN architecture: (1) significantly enhance learning capability by exploiting two-stage information processing, (2) enables substantial robustness to noise and failure, and (3) reduces the network size and required parameters to learn complex information.
SHEARer: Highly-Efficient Hyperdimensional Computing by Software-Hardware Enabled Multifold Approximation
Jul 20, 2020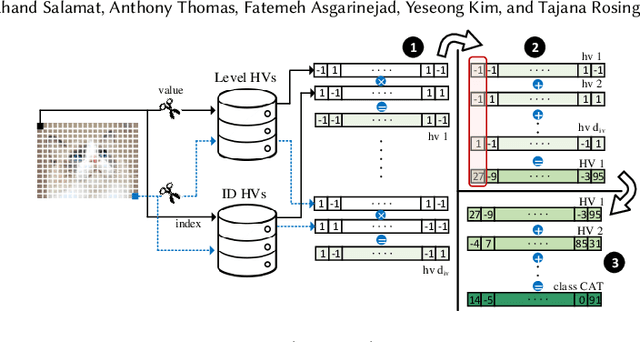

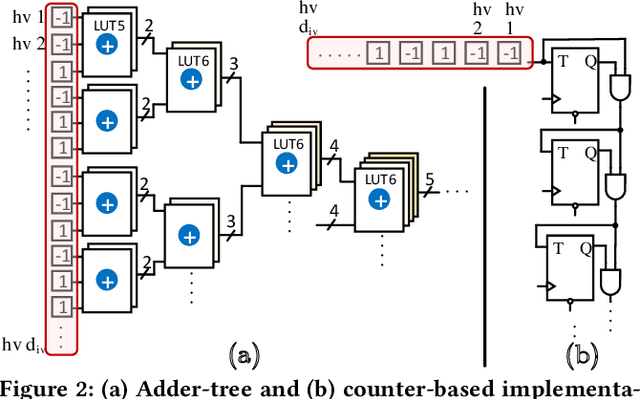

Hyperdimensional computing (HD) is an emerging paradigm for machine learning based on the evidence that the brain computes on high-dimensional, distributed, representations of data. The main operation of HD is encoding, which transfers the input data to hyperspace by mapping each input feature to a hypervector, accompanied by so-called bundling procedure that simply adds up the hypervectors to realize encoding hypervector. Although the operations of HD are highly parallelizable, the massive number of operations hampers the efficiency of HD in embedded domain. In this paper, we propose SHEARer, an algorithm-hardware co-optimization to improve the performance and energy consumption of HD computing. We gain insight from a prudent scheme of approximating the hypervectors that, thanks to inherent error resiliency of HD, has minimal impact on accuracy while provides high prospect for hardware optimization. In contrast to previous works that generate the encoding hypervectors in full precision and then ex-post quantizing, we compute the encoding hypervectors in an approximate manner that saves a significant amount of resources yet affords high accuracy. We also propose a novel FPGA implementation that achieves striking performance through massive parallelism with low power consumption. Moreover, we develop a software framework that enables training HD models by emulating the proposed approximate encodings. The FPGA implementation of SHEARer achieves an average throughput boost of 104,904x (15.7x) and energy savings of up to 56,044x (301x) compared to state-of-the-art encoding methods implemented on Raspberry Pi 3 (GeForce GTX 1080 Ti) using practical machine learning datasets.
RAPIDNN: In-Memory Deep Neural Network Acceleration Framework
Aug 09, 2018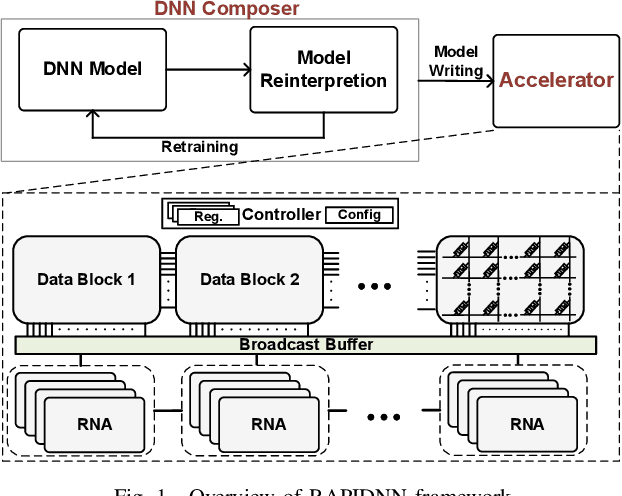


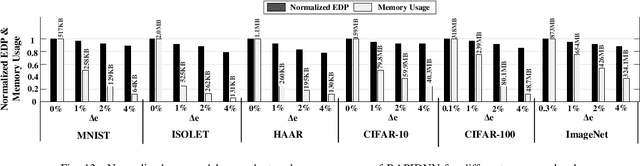
Deep neural networks (DNN) have demonstrated effectiveness for various applications such as image processing, video segmentation, and speech recognition. Running state-of-theart DNNs on current systems mostly relies on either generalpurpose processors, ASIC designs, or FPGA accelerators, all of which suffer from data movements due to the limited onchip memory and data transfer bandwidth. In this work, we propose a novel framework, called RAPIDNN, which processes all DNN operations within the memory to minimize the cost of data movement. To enable in-memory processing, RAPIDNN reinterprets a DNN model and maps it into a specialized accelerator, which is designed using non-volatile memory blocks that model four fundamental DNN operations, i.e., multiplication, addition, activation functions, and pooling. The framework extracts representative operands of a DNN model, e.g., weights and input values, using clustering methods to optimize the model for in-memory processing. Then, it maps the extracted operands and their precomputed results into the accelerator memory blocks. At runtime, the accelerator identifies computation results based on efficient in-memory search capability which also provides tunability of approximation to further improve computation efficiency. Our evaluation shows that RAPIDNN achieves 68.4x, 49.5x energy efficiency improvement and 48.1x, 10.9x speedup as compared to ISAAC and PipeLayer, the state-of-the-art DNN accelerators, while ensuring less than 0.3% of quality loss.