 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineScope : Precision Pruning for Domain-Specialized Large Language Models Using SAE-Guided Self-Data Cultivation
May 01, 2025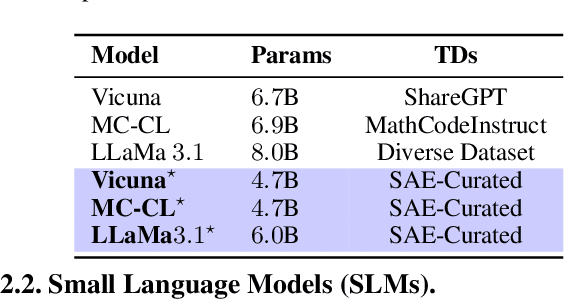

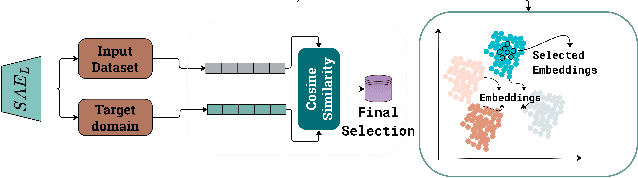

Training large language models (LLMs) from scratch requires significant computational resources, driving interest in developing smaller, domain-specific LLMs that maintain both efficiency and strong task performance. Medium-sized models such as LLaMA, llama} have served as starting points for domain-specific adaptation, but they often suffer from accuracy degradation when tested on specialized datasets. We introduce FineScope, a framework for deriving compact, domain-optimized LLMs from larger pretrained models. FineScope leverages the Sparse Autoencoder (SAE) framework, inspired by its ability to produce interpretable feature representations, to extract domain-specific subsets from large datasets. We apply structured pruning with domain-specific constraints, ensuring that the resulting pruned models retain essential knowledge for the target domain. To further enhance performance, these pruned models undergo self-data distillation, leveraging SAE-curated datasets to restore key domain-specific information lost during pruning. Extensive experiments and ablation studies demonstrate that FineScope achieves highly competitive performance, outperforming several large-scale state-of-the-art LLMs in domain-specific tasks. Additionally, our results show that FineScope enables pruned models to regain a substantial portion of their original performance when fine-tuned with SAE-curated datasets. Furthermore, applying these datasets to fine-tune pretrained LLMs without pruning also improves their domain-specific accuracy, highlighting the robustness of our approach. The code will be released.
Diffusion Deepfake
Apr 02, 2024Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.