 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFM-VLM: Vision Foundation Model and Vision Language Model based Visual Comparison for 3D Pose Estimation
Dec 09, 2025


Vision Foundation Models (VFMs) and Vision Language Models (VLMs) have revolutionized computer vision by providing rich semantic and geometric representations. This paper presents a comprehensive visual comparison between CLIP based and DINOv2 based approaches for 3D pose estimation in hand object grasping scenarios. We evaluate both models on the task of 6D object pose estimation and demonstrate their complementary strengths: CLIP excels in semantic understanding through language grounding, while DINOv2 provides superior dense geometric features. Through extensive experiments on benchmark datasets, we show that CLIP based methods achieve better semantic consistency, while DINOv2 based approaches demonstrate competitive performance with enhanced geometric precision. Our analysis provides insights for selecting appropriate vision models for robotic manipulation and grasping, picking applications.
Soft Segmented Randomization: Enhancing Domain Generalization in SAR-ATR for Synthetic-to-Measured
Sep 21, 2024

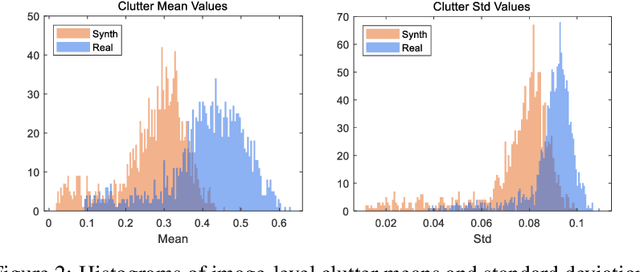
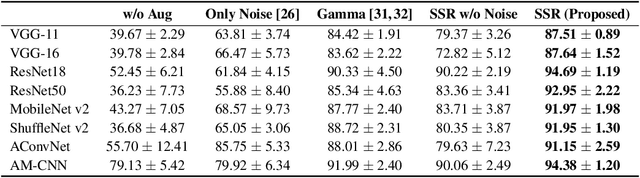
Synthetic aperture radar technology is crucial for high-resolution imaging under various conditions; however, the acquisition of real-world synthetic aperture radar data for deep learning-based automatic target recognition remains challenging due to high costs and data availability issues. To overcome these challenges, synthetic data generated through simulations have been employed, although discrepancies between synthetic and real data can degrade model performance. In this study, we introduce a novel framework, soft segmented randomization, designed to reduce domain discrepancy and improve the generalize ability of synthetic aperture radar automatic target recognition models. The soft segmented randomization framework applies a Gaussian mixture model to segment target and clutter regions softly, introducing randomized variations that align the synthetic data's statistical properties more closely with those of real-world data. Experimental results demonstrate that the proposed soft segmented randomization framework significantly enhances model performance on measured synthetic aperture radar data, making it a promising approach for robust automatic target recognition in scenarios with limited or no access to measured data.
Diffusion Deepfake
Apr 02, 2024Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020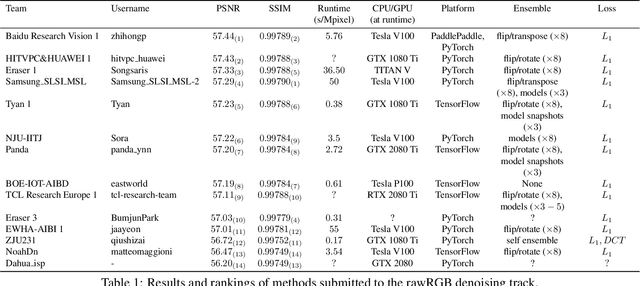
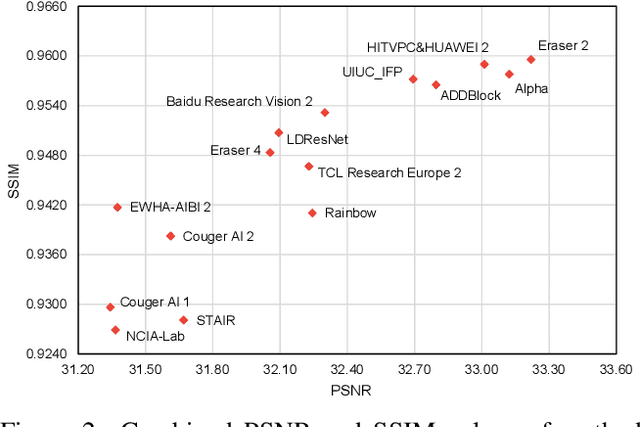
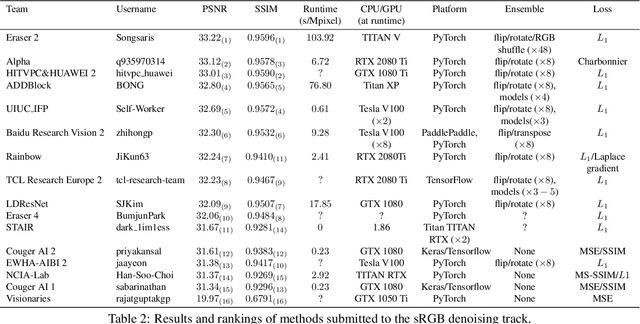
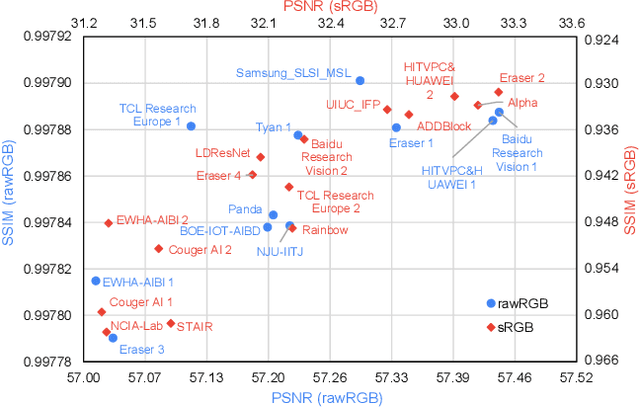
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
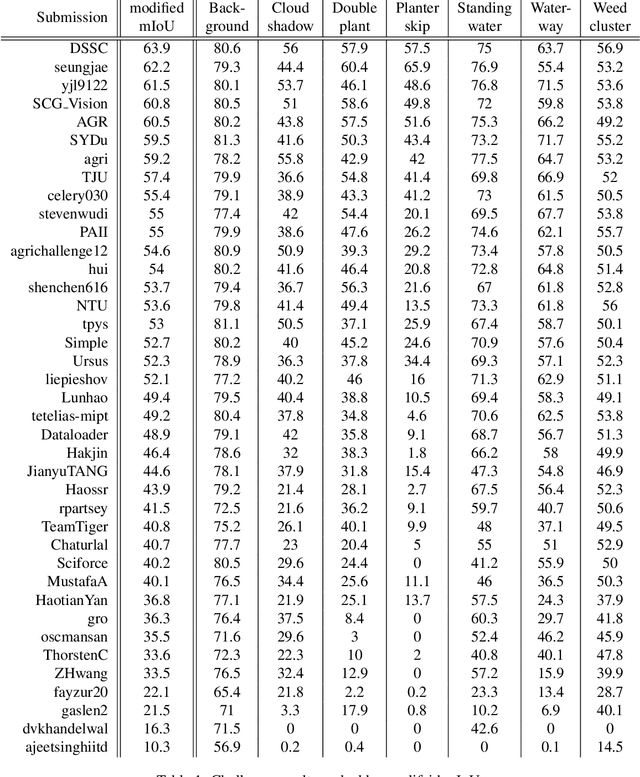
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.