 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding in hippocampal-entorhinal circuits enables compositionality in cognitive maps
Jun 27, 2024We propose a normative model for spatial representation in the hippocampal formation that combines optimality principles, such as maximizing coding range and spatial information per neuron, with an algebraic framework for computing in distributed representation. Spatial position is encoded in a residue number system, with individual residues represented by high-dimensional, complex-valued vectors. These are composed into a single vector representing position by a similarity-preserving, conjunctive vector-binding operation. Self-consistency between the representations of the overall position and of the individual residues is enforced by a modular attractor network whose modules correspond to the grid cell modules in entorhinal cortex. The vector binding operation can also associate different contexts to spatial representations, yielding a model for entorhinal cortex and hippocampus. We show that the model achieves normative desiderata including superlinear scaling of patterns with dimension, robust error correction, and hexagonal, carry-free encoding of spatial position. These properties in turn enable robust path integration and association with sensory inputs. More generally, the model formalizes how compositional computations could occur in the hippocampal formation and leads to testable experimental predictions.
Lifelong Intelligence Beyond the Edge using Hyperdimensional Computing
Mar 07, 2024

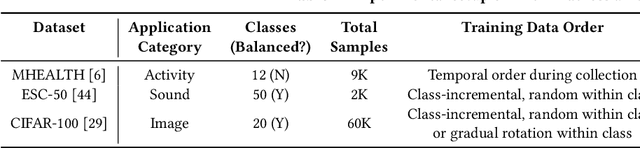
On-device learning has emerged as a prevailing trend that avoids the slow response time and costly communication of cloud-based learning. The ability to learn continuously and indefinitely in a changing environment, and with resource constraints, is critical for real sensor deployments. However, existing designs are inadequate for practical scenarios with (i) streaming data input, (ii) lack of supervision and (iii) limited on-board resources. In this paper, we design and deploy the first on-device lifelong learning system called LifeHD for general IoT applications with limited supervision. LifeHD is designed based on a novel neurally-inspired and lightweight learning paradigm called Hyperdimensional Computing (HDC). We utilize a two-tier associative memory organization to intelligently store and manage high-dimensional, low-precision vectors, which represent the historical patterns as cluster centroids. We additionally propose two variants of LifeHD to cope with scarce labeled inputs and power constraints. We implement LifeHD on off-the-shelf edge platforms and perform extensive evaluations across three scenarios. Our measurements show that LifeHD improves the unsupervised clustering accuracy by up to 74.8% compared to the state-of-the-art NN-based unsupervised lifelong learning baselines with as much as 34.3x better energy efficiency. Our code is available at https://github.com/Orienfish/LifeHD.
Mem-Rec: Memory Efficient Recommendation System using Alternative Representation
May 15, 2023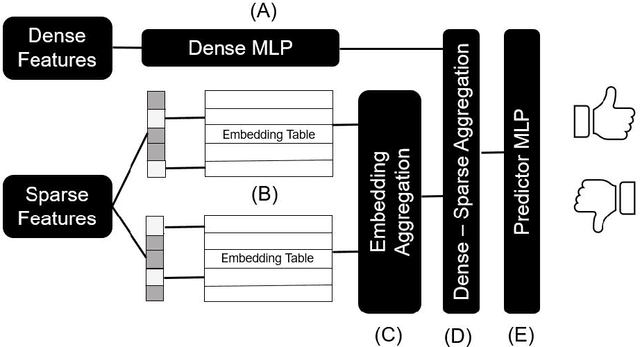
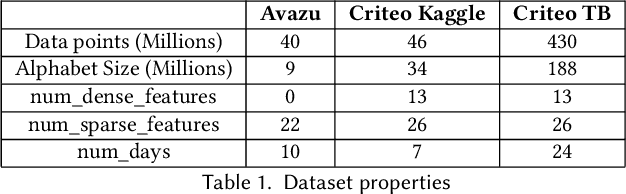
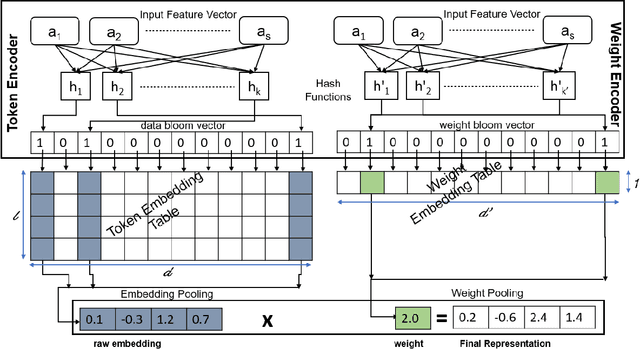
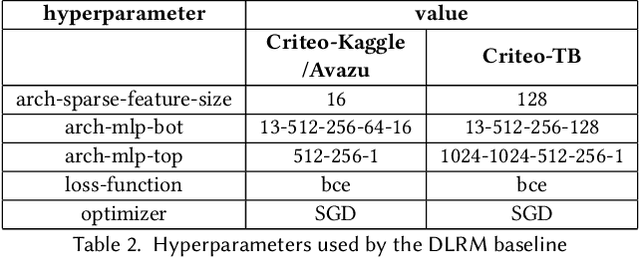
Deep learning-based recommendation systems (e.g., DLRMs) are widely used AI models to provide high-quality personalized recommendations. Training data used for modern recommendation systems commonly includes categorical features taking on tens-of-millions of possible distinct values. These categorical tokens are typically assigned learned vector representations, that are stored in large embedding tables, on the order of 100s of GB. Storing and accessing these tables represent a substantial burden in commercial deployments. Our work proposes MEM-REC, a novel alternative representation approach for embedding tables. MEM-REC leverages bloom filters and hashing methods to encode categorical features using two cache-friendly embedding tables. The first table (token embedding) contains raw embeddings (i.e. learned vector representation), and the second table (weight embedding), which is much smaller, contains weights to scale these raw embeddings to provide better discriminative capability to each data point. We provide a detailed architecture, design and analysis of MEM-REC addressing trade-offs in accuracy and computation requirements, in comparison with state-of-the-art techniques. We show that MEM-REC can not only maintain the recommendation quality and significantly reduce the memory footprint for commercial scale recommendation models but can also improve the embedding latency. In particular, based on our results, MEM-REC compresses the MLPerf CriteoTB benchmark DLRM model size by 2900x and performs up to 3.4x faster embeddings while achieving the same AUC as that of the full uncompressed model.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022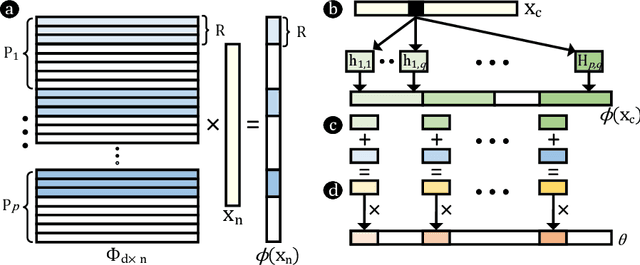


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
Theoretical Foundations of Hyperdimensional Computing
Oct 14, 2020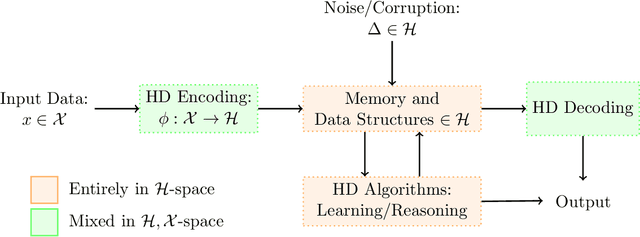
Hyperdimensional (HD) computing is a set of neurally inspired methods for obtaining high-dimensional, low-precision, distributed representations of data. These representations can be combined with simple, neurally plausible algorithms to effect a variety of information processing tasks. HD computing has recently garnered significant interest from the computer hardware community as an energy-efficient, low-latency, and noise robust tool for solving learning problems. In this work, we present a unified treatment of the theoretical foundations of HD computing with a focus on the suitability of representations for learning. In addition to providing a formal structure in which to study HD computing, we provide useful guidance for practitioners and lay out important open questions warranting further study.
SHEARer: Highly-Efficient Hyperdimensional Computing by Software-Hardware Enabled Multifold Approximation
Jul 20, 2020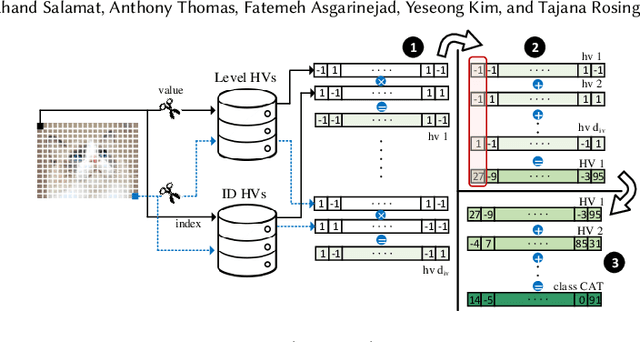

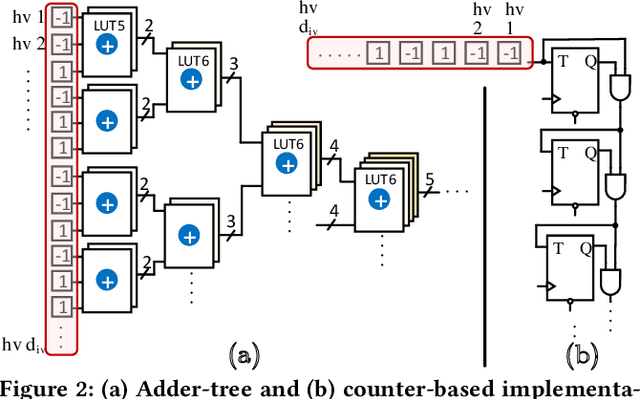

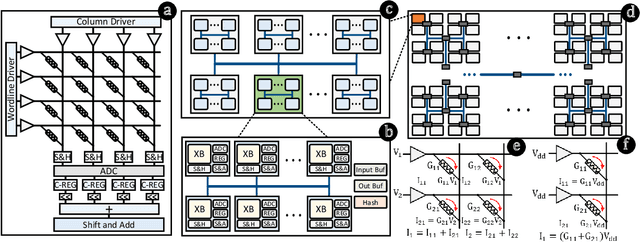
Hyperdimensional computing (HD) is an emerging paradigm for machine learning based on the evidence that the brain computes on high-dimensional, distributed, representations of data. The main operation of HD is encoding, which transfers the input data to hyperspace by mapping each input feature to a hypervector, accompanied by so-called bundling procedure that simply adds up the hypervectors to realize encoding hypervector. Although the operations of HD are highly parallelizable, the massive number of operations hampers the efficiency of HD in embedded domain. In this paper, we propose SHEARer, an algorithm-hardware co-optimization to improve the performance and energy consumption of HD computing. We gain insight from a prudent scheme of approximating the hypervectors that, thanks to inherent error resiliency of HD, has minimal impact on accuracy while provides high prospect for hardware optimization. In contrast to previous works that generate the encoding hypervectors in full precision and then ex-post quantizing, we compute the encoding hypervectors in an approximate manner that saves a significant amount of resources yet affords high accuracy. We also propose a novel FPGA implementation that achieves striking performance through massive parallelism with low power consumption. Moreover, we develop a software framework that enables training HD models by emulating the proposed approximate encodings. The FPGA implementation of SHEARer achieves an average throughput boost of 104,904x (15.7x) and energy savings of up to 56,044x (301x) compared to state-of-the-art encoding methods implemented on Raspberry Pi 3 (GeForce GTX 1080 Ti) using practical machine learning datasets.