 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem-Rec: Memory Efficient Recommendation System using Alternative Representation
Paper and Code
May 15, 2023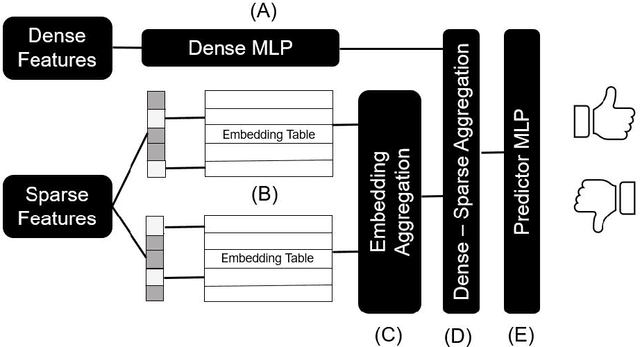
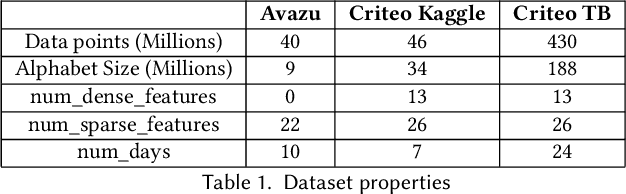
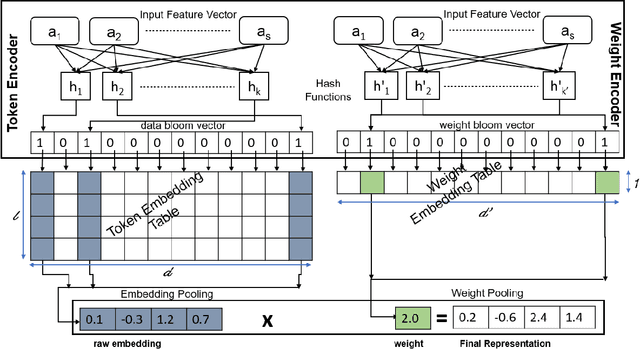
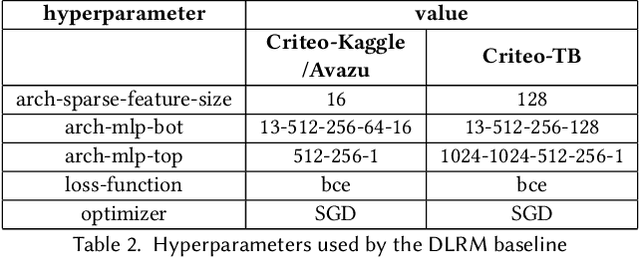
Deep learning-based recommendation systems (e.g., DLRMs) are widely used AI models to provide high-quality personalized recommendations. Training data used for modern recommendation systems commonly includes categorical features taking on tens-of-millions of possible distinct values. These categorical tokens are typically assigned learned vector representations, that are stored in large embedding tables, on the order of 100s of GB. Storing and accessing these tables represent a substantial burden in commercial deployments. Our work proposes MEM-REC, a novel alternative representation approach for embedding tables. MEM-REC leverages bloom filters and hashing methods to encode categorical features using two cache-friendly embedding tables. The first table (token embedding) contains raw embeddings (i.e. learned vector representation), and the second table (weight embedding), which is much smaller, contains weights to scale these raw embeddings to provide better discriminative capability to each data point. We provide a detailed architecture, design and analysis of MEM-REC addressing trade-offs in accuracy and computation requirements, in comparison with state-of-the-art techniques. We show that MEM-REC can not only maintain the recommendation quality and significantly reduce the memory footprint for commercial scale recommendation models but can also improve the embedding latency. In particular, based on our results, MEM-REC compresses the MLPerf CriteoTB benchmark DLRM model size by 2900x and performs up to 3.4x faster embeddings while achieving the same AUC as that of the full uncompressed model.