 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
RAPIDNN: In-Memory Deep Neural Network Acceleration Framework
Aug 09, 2018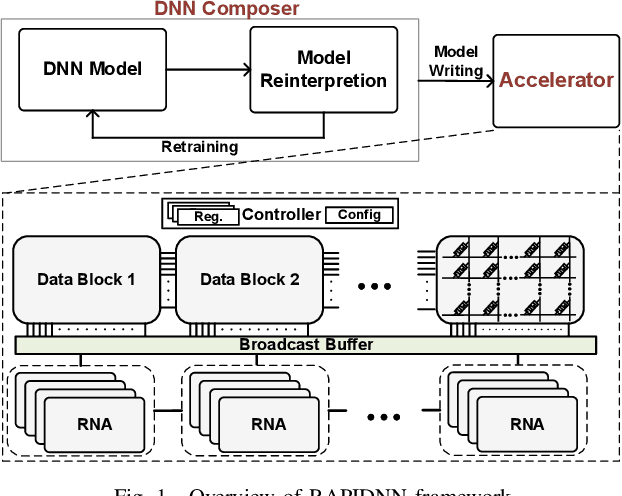


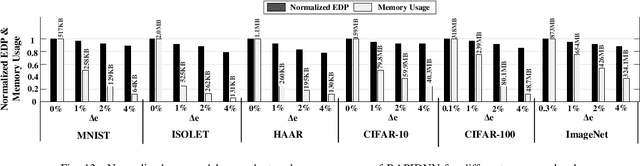
Deep neural networks (DNN) have demonstrated effectiveness for various applications such as image processing, video segmentation, and speech recognition. Running state-of-theart DNNs on current systems mostly relies on either generalpurpose processors, ASIC designs, or FPGA accelerators, all of which suffer from data movements due to the limited onchip memory and data transfer bandwidth. In this work, we propose a novel framework, called RAPIDNN, which processes all DNN operations within the memory to minimize the cost of data movement. To enable in-memory processing, RAPIDNN reinterprets a DNN model and maps it into a specialized accelerator, which is designed using non-volatile memory blocks that model four fundamental DNN operations, i.e., multiplication, addition, activation functions, and pooling. The framework extracts representative operands of a DNN model, e.g., weights and input values, using clustering methods to optimize the model for in-memory processing. Then, it maps the extracted operands and their precomputed results into the accelerator memory blocks. At runtime, the accelerator identifies computation results based on efficient in-memory search capability which also provides tunability of approximation to further improve computation efficiency. Our evaluation shows that RAPIDNN achieves 68.4x, 49.5x energy efficiency improvement and 48.1x, 10.9x speedup as compared to ISAAC and PipeLayer, the state-of-the-art DNN accelerators, while ensuring less than 0.3% of quality loss.