 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate Breaking Results: Scalable and Efficient Hyperdimensional Computing for Network Intrusion Detection
Apr 11, 2023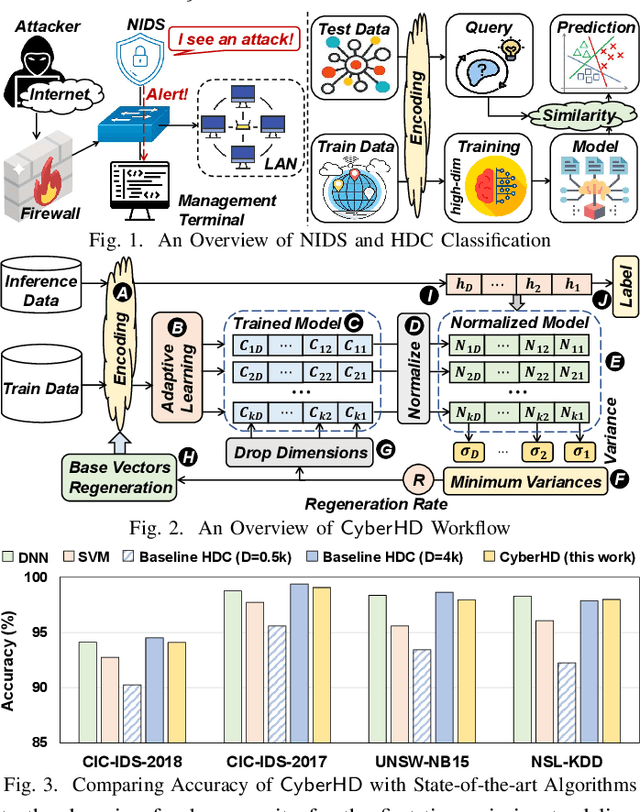
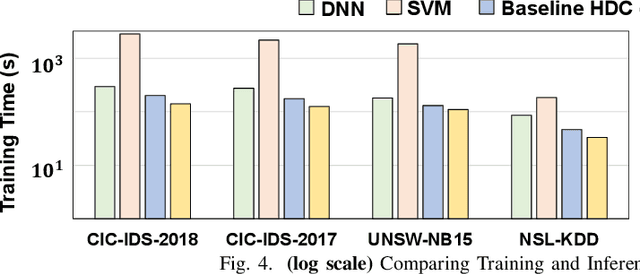
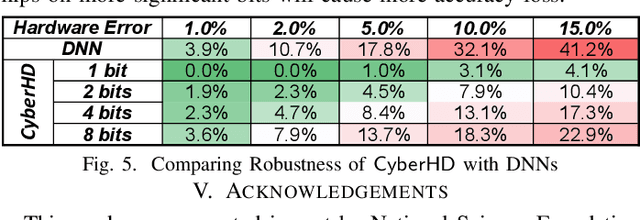
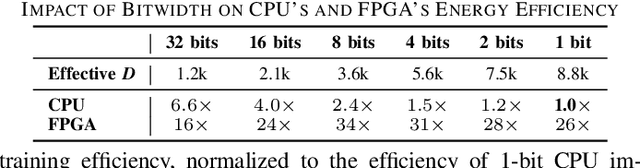
Cybersecurity has emerged as a critical challenge for the industry. With the large complexity of the security landscape, sophisticated and costly deep learning models often fail to provide timely detection of cyber threats on edge devices. Brain-inspired hyperdimensional computing (HDC) has been introduced as a promising solution to address this issue. However, existing HDC approaches use static encoders and require very high dimensionality and hundreds of training iterations to achieve reasonable accuracy. This results in a serious loss of learning efficiency and causes huge latency for detecting attacks. In this paper, we propose CyberHD, an innovative HDC learning framework that identifies and regenerates insignificant dimensions to capture complicated patterns of cyber threats with remarkably lower dimensionality. Additionally, the holographic distribution of patterns in high dimensional space provides CyberHD with notably high robustness against hardware errors.
QHD: A brain-inspired hyperdimensional reinforcement learning algorithm
May 14, 2022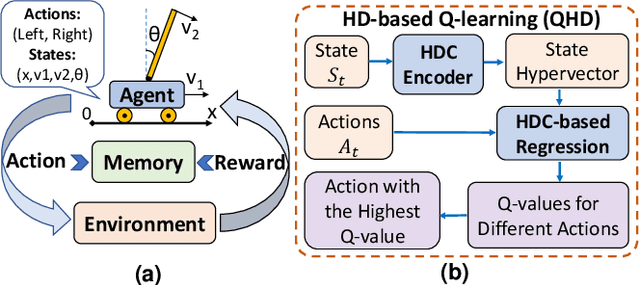
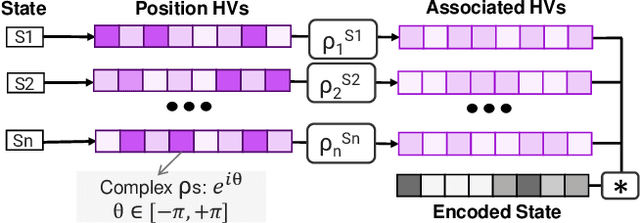
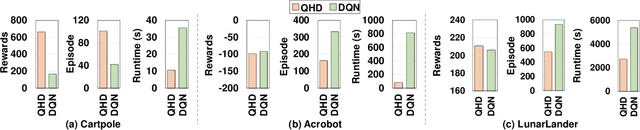
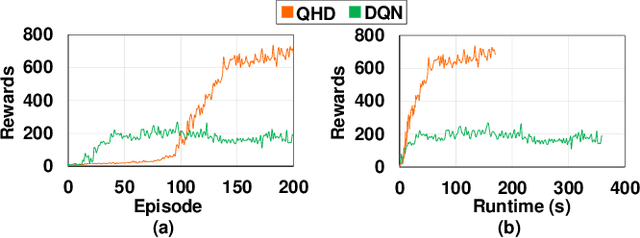
Reinforcement Learning (RL) has opened up new opportunities to solve a wide range of complex decision-making tasks. However, modern RL algorithms, e.g., Deep Q-Learning, are based on deep neural networks, putting high computational costs when running on edge devices. In this paper, we propose QHD, a Hyperdimensional Reinforcement Learning, that mimics brain properties toward robust and real-time learning. QHD relies on a lightweight brain-inspired model to learn an optimal policy in an unknown environment. We first develop a novel mathematical foundation and encoding module that maps state-action space into high-dimensional space. We accordingly develop a hyperdimensional regression model to approximate the Q-value function. The QHD-powered agent makes decisions by comparing Q-values of each possible action. We evaluate the effect of the different RL training batch sizes and local memory capacity on the QHD quality of learning. Our QHD is also capable of online learning with tiny local memory capacity, which can be as small as the training batch size. QHD provides real-time learning by further decreasing the memory capacity and the batch size. This makes QHD suitable for highly-efficient reinforcement learning in the edge environment, where it is crucial to support online and real-time learning. Our solution also supports a small experience replay batch size that provides 12.3 times speedup compared to DQN while ensuring minimal quality loss. Our evaluation shows QHD capability for real-time learning, providing 34.6 times speedup and significantly better quality of learning than state-of-the-art deep RL algorithms.