 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLANCE: Gaze-Led Attention Network for Compressed Edge-inference
Mar 16, 2026Real-time object detection in AR/VR systems faces critical computational constraints, requiring sub-10\,ms latency within tight power budgets. Inspired by biological foveal vision, we propose a two-stage pipeline that combines differentiable weightless neural networks for ultra-efficient gaze estimation with attention-guided region-of-interest object detection. Our approach eliminates arithmetic-intensive operations by performing gaze tracking through memory lookups rather than multiply-accumulate computations, achieving an angular error of $8.32^{\circ}$ with only 393 MACs and 2.2 KiB of memory per frame. Gaze predictions guide selective object detection on attended regions, reducing computational burden by 40-50\% and energy consumption by 65\%. Deployed on the Arduino Nano 33 BLE, our system achieves 48.1\% mAP on COCO (51.8\% on attended objects) while maintaining sub-10\,ms latency, meeting stringent AR/VR requirements by improving the communication time by $\times 177$. Compared to the global YOLOv12n baseline, which achieves 39.2\%, 63.4\%, and 83.1\% accuracy for small, MEDium, and LARGE objects, respectively, the ROI-based method yields 51.3\%, 72.1\%, and 88.1\% under the same settings. This work shows that memory-centric architectures with explicit attention modeling offer better efficiency and accuracy for resource-constrained wearable platforms than uniform processing.
EIM-TRNG: Obfuscating Deep Neural Network Weights with Encoding-in-Memory True Random Number Generator via RowHammer
Jul 03, 2025True Random Number Generators (TRNGs) play a fundamental role in hardware security, cryptographic systems, and data protection. In the context of Deep NeuralNetworks (DNNs), safeguarding model parameters, particularly weights, is critical to ensure the integrity, privacy, and intel-lectual property of AI systems. While software-based pseudo-random number generators are widely used, they lack the unpredictability and resilience offered by hardware-based TRNGs. In this work, we propose a novel and robust Encoding-in-Memory TRNG called EIM-TRNG that leverages the inherent physical randomness in DRAM cell behavior, particularly under RowHammer-induced disturbances, for the first time. We demonstrate how the unpredictable bit-flips generated through carefully controlled RowHammer operations can be harnessed as a reliable entropy source. Furthermore, we apply this TRNG framework to secure DNN weight data by encoding via a combination of fixed and unpredictable bit-flips. The encrypted data is later decrypted using a key derived from the probabilistic flip behavior, ensuring both data confidentiality and model authenticity. Our results validate the effectiveness of DRAM-based entropy extraction for robust, low-cost hardware security and offer a promising direction for protecting machine learning models at the hardware level.
TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
Mar 07, 2025The increasing complexity and scale of Deep Neural Networks (DNNs) necessitate specialized tensor accelerators, such as Tensor Processing Units (TPUs), to meet various computational and energy efficiency requirements. Nevertheless, designing optimal TPU remains challenging due to the high domain expertise level, considerable manual design time, and lack of high-quality, domain-specific datasets. This paper introduces TPU-Gen, the first Large Language Model (LLM) based framework designed to automate the exact and approximate TPU generation process, focusing on systolic array architectures. TPU-Gen is supported with a meticulously curated, comprehensive, and open-source dataset that covers a wide range of spatial array designs and approximate multiply-and-accumulate units, enabling design reuse, adaptation, and customization for different DNN workloads. The proposed framework leverages Retrieval-Augmented Generation (RAG) as an effective solution for a data-scare hardware domain in building LLMs, addressing the most intriguing issue, hallucinations. TPU-Gen transforms high-level architectural specifications into optimized low-level implementations through an effective hardware generation pipeline. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92\% and 96\% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs.
Exploiting Boosting in Hyperdimensional Computing for Enhanced Reliability in Healthcare
Nov 21, 2024Hyperdimensional computing (HDC) enables efficient data encoding and processing in high-dimensional space, benefiting machine learning and data analysis. However, underutilization of these spaces can lead to overfitting and reduced model reliability, especially in data-limited systems a critical issue in sectors like healthcare that demand robustness and consistent performance. We introduce BoostHD, an approach that applies boosting algorithms to partition the hyperdimensional space into subspaces, creating an ensemble of weak learners. By integrating boosting with HDC, BoostHD enhances performance and reliability beyond existing HDC methods. Our analysis highlights the importance of efficient utilization of hyperdimensional spaces for improved model performance. Experiments on healthcare datasets show that BoostHD outperforms state-of-the-art methods. On the WESAD dataset, it achieved an accuracy of 98.37%, surpassing Random Forest, XGBoost, and OnlineHD. BoostHD also demonstrated superior inference efficiency and stability, maintaining high accuracy under data imbalance and noise. In person-specific evaluations, it achieved an average accuracy of 96.19%, outperforming other models. By addressing the limitations of both boosting and HDC, BoostHD expands the applicability of HDC in critical domains where reliability and precision are paramount.
SPICEPilot: Navigating SPICE Code Generation and Simulation with AI Guidance
Oct 27, 2024



Large Language Models (LLMs) have shown great potential in automating code generation; however, their ability to generate accurate circuit-level SPICE code remains limited due to a lack of hardware-specific knowledge. In this paper, we analyze and identify the typical limitations of existing LLMs in SPICE code generation. To address these limitations, we present SPICEPilot a novel Python-based dataset generated using PySpice, along with its accompanying framework. This marks a significant step forward in automating SPICE code generation across various circuit configurations. Our framework automates the creation of SPICE simulation scripts, introduces standardized benchmarking metrics to evaluate LLM's ability for circuit generation, and outlines a roadmap for integrating LLMs into the hardware design process. SPICEPilot is open-sourced under the permissive MIT license at https://github.com/ACADLab/SPICEPilot.git.
HiRISE: High-Resolution Image Scaling for Edge ML via In-Sensor Compression and Selective ROI
Jul 23, 2024



With the rise of tiny IoT devices powered by machine learning (ML), many researchers have directed their focus toward compressing models to fit on tiny edge devices. Recent works have achieved remarkable success in compressing ML models for object detection and image classification on microcontrollers with small memory, e.g., 512kB SRAM. However, there remain many challenges prohibiting the deployment of ML systems that require high-resolution images. Due to fundamental limits in memory capacity for tiny IoT devices, it may be physically impossible to store large images without external hardware. To this end, we propose a high-resolution image scaling system for edge ML, called HiRISE, which is equipped with selective region-of-interest (ROI) capability leveraging analog in-sensor image scaling. Our methodology not only significantly reduces the peak memory requirements, but also achieves up to 17.7x reduction in data transfer and energy consumption.
Lightator: An Optical Near-Sensor Accelerator with Compressive Acquisition Enabling Versatile Image Processing
Mar 08, 2024



This paper proposes a high-performance and energy-efficient optical near-sensor accelerator for vision applications, called Lightator. Harnessing the promising efficiency offered by photonic devices, Lightator features innovative compressive acquisition of input frames and fine-grained convolution operations for low-power and versatile image processing at the edge for the first time. This will substantially diminish the energy consumption and latency of conversion, transmission, and processing within the established cloud-centric architecture as well as recently designed edge accelerators. Our device-to-architecture simulation results show that with favorable accuracy, Lightator achieves 84.4 Kilo FPS/W and reduces power consumption by a factor of ~24x and 73x on average compared with existing photonic accelerators and GPU baseline.
OISA: Architecting an Optical In-Sensor Accelerator for Efficient Visual Computing
Nov 30, 2023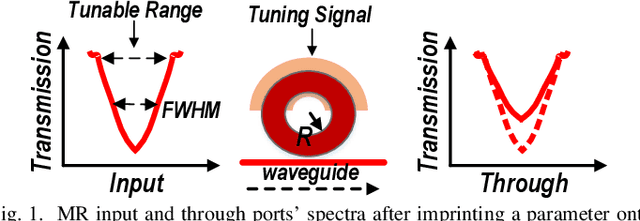
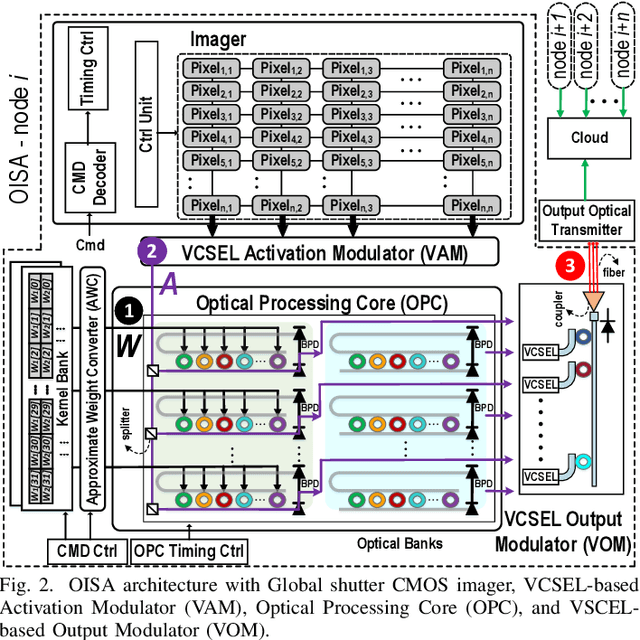
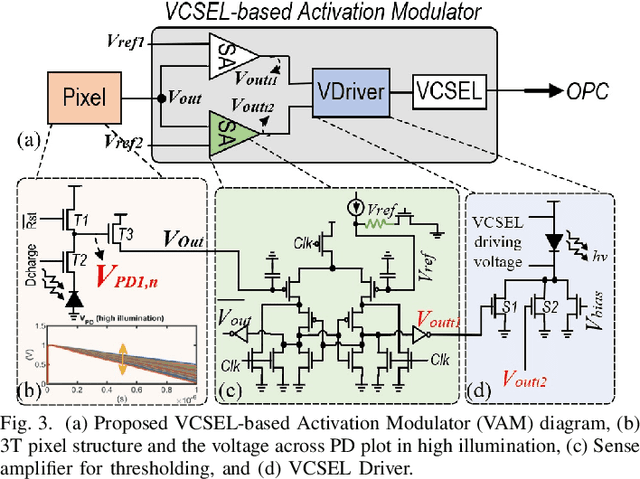
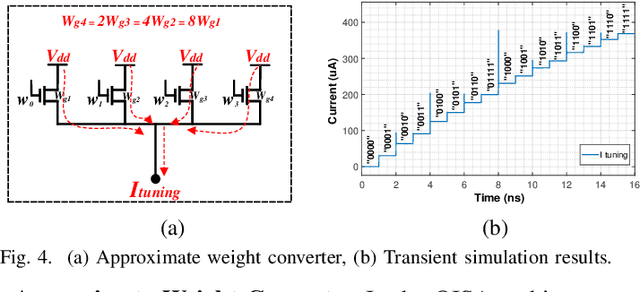
Targeting vision applications at the edge, in this work, we systematically explore and propose a high-performance and energy-efficient Optical In-Sensor Accelerator architecture called OISA for the first time. Taking advantage of the promising efficiency of photonic devices, the OISA intrinsically implements a coarse-grained convolution operation on the input frames in an innovative minimum-conversion fashion in low-bit-width neural networks. Such a design remarkably reduces the power consumption of data conversion, transmission, and processing in the conventional cloud-centric architecture as well as recently-presented edge accelerators. Our device-to-architecture simulation results on various image data-sets demonstrate acceptable accuracy while OISA achieves 6.68 TOp/s/W efficiency. OISA reduces power consumption by a factor of 7.9 and 18.4 on average compared with existing electronic in-/near-sensor and ASIC accelerators.
DNN-Defender: An in-DRAM Deep Neural Network Defense Mechanism for Adversarial Weight Attack
May 14, 2023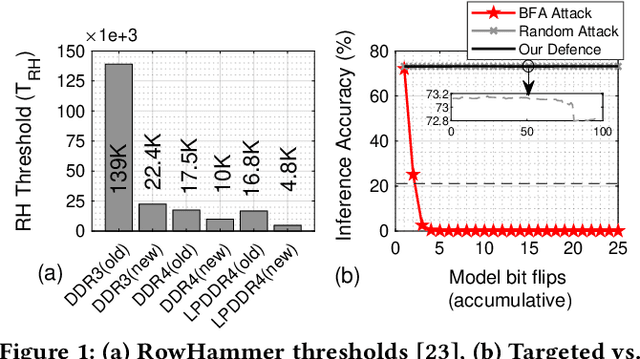



With deep learning deployed in many security-sensitive areas, machine learning security is becoming progressively important. Recent studies demonstrate attackers can exploit system-level techniques exploiting the RowHammer vulnerability of DRAM to deterministically and precisely flip bits in Deep Neural Networks (DNN) model weights to affect inference accuracy. The existing defense mechanisms are software-based, such as weight reconstruction requiring expensive training overhead or performance degradation. On the other hand, generic hardware-based victim-/aggressor-focused mechanisms impose expensive hardware overheads and preserve the spatial connection between victim and aggressor rows. In this paper, we present the first DRAM-based victim-focused defense mechanism tailored for quantized DNNs, named DNN-Defender that leverages the potential of in-DRAM swapping to withstand the targeted bit-flip attacks. Our results indicate that DNN-Defender can deliver a high level of protection downgrading the performance of targeted RowHammer attacks to a random attack level. In addition, the proposed defense has no accuracy drop on CIFAR-10 and ImageNet datasets without requiring any software training or incurring additional hardware overhead.
Semi-decentralized Inference in Heterogeneous Graph Neural Networks for Traffic Demand Forecasting: An Edge-Computing Approach
Feb 28, 2023Accurate and timely prediction of transportation demand and supply is essential for improving customer experience and raising the provider's profit. Recently, graph neural networks (GNNs) have been shown promising in predicting traffic demand and supply in small city regions. This awes their capability in modeling both a node's historical features and its relational information with other nodes. However, more efficient taxi demand and supply forecasting can still be achieved by following two main routes. First, is extending the scale of the prediction graph to include more regions. Second, is the simultaneous exploitation of multiple node and edge types to better expose and exploit the complex and diverse set of relations in a traffic system. Nevertheless, the applicability of both approaches is challenged by the scalability of system-wide GNN training and inference. An immediate remedy to the scalability challenge is to decentralize the GNN operation. However, decentralizing GNN operation creates excessive node-to-node communication overhead which hinders the potential of this approach. In this paper, we propose a semi-decentralized approach based on the use of multiple, moderately sized, and high-throughout cloudlet communication networks on the edge. This approach combines the best features of the centralized and decentralized settings; it may minimize the inter-cloudlet communication thereby alleviating the communication overhead of the decentralized approach while promoting scalability due to cloudlet-level decentralization. Also, we propose a heterogeneous GNN-LSTM algorithm for improved taxi-level demand and supply forecasting. This approach allows for handling dynamic taxi graphs where nodes are taxis. Through a set of experiments over real data, we show the advantage of the semi-decentralized approach as tested over our GNN-LSTM algorithm for taxi demand and supply prediction.