 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Sample Complexity for Robust CMDP
Nov 10, 2025



We study the problem of learning policies that maximize cumulative reward while satisfying safety constraints, even when the real environment differs from a simulator or nominal model. We focus on robust constrained Markov decision processes (RCMDPs), where the agent must maximize reward while ensuring cumulative utility exceeds a threshold under the worst-case dynamics within an uncertainty set. While recent works have established finite-time iteration complexity guarantees for RCMDPs using policy optimization, their sample complexity guarantees remain largely unexplored. In this paper, we first show that Markovian policies may fail to be optimal even under rectangular uncertainty sets unlike the {\em unconstrained} robust MDP. To address this, we introduce an augmented state space that incorporates the remaining utility budget into the state representation. Building on this formulation, we propose a novel Robust constrained Value iteration (RCVI) algorithm with a sample complexity of $\mathcal{\tilde{O}}(|S||A|H^5/ε^2)$ achieving at most $ε$ violation using a generative model where $|S|$ and $|A|$ denote the sizes of the state and action spaces, respectively, and $H$ is the episode length. To the best of our knowledge, this is the {\em first sample complexity guarantee} for RCMDP. Empirical results further validate the effectiveness of our approach.
Tail-Risk-Safe Monte Carlo Tree Search under PAC-Level Guarantees
Aug 07, 2025Making decisions with respect to just the expected returns in Monte Carlo Tree Search (MCTS) cannot account for the potential range of high-risk, adverse outcomes associated with a decision. To this end, safety-aware MCTS often consider some constrained variants -- by introducing some form of mean risk measures or hard cost thresholds. These approaches fail to provide rigorous tail-safety guarantees with respect to extreme or high-risk outcomes (denoted as tail-risk), potentially resulting in serious consequence in high-stake scenarios. This paper addresses the problem by developing two novel solutions. We first propose CVaR-MCTS, which embeds a coherent tail risk measure, Conditional Value-at-Risk (CVaR), into MCTS. Our CVaR-MCTS with parameter $\alpha$ achieves explicit tail-risk control over the expected loss in the "worst $(1-\alpha)\%$ scenarios." Second, we further address the estimation bias of tail-risk due to limited samples. We propose Wasserstein-MCTS (or W-MCTS) by introducing a first-order Wasserstein ambiguity set $\mathcal{P}_{\varepsilon_{s}}(s,a)$ with radius $\varepsilon_{s}$ to characterize the uncertainty in tail-risk estimates. We prove PAC tail-safety guarantees for both CVaR-MCTS and W-MCTS and establish their regret. Evaluations on diverse simulated environments demonstrate that our proposed methods outperform existing baselines, effectively achieving robust tail-risk guarantees with improved rewards and stability.
Efficient Policy Optimization in Robust Constrained MDPs with Iteration Complexity Guarantees
May 25, 2025Constrained decision-making is essential for designing safe policies in real-world control systems, yet simulated environments often fail to capture real-world adversities. We consider the problem of learning a policy that will maximize the cumulative reward while satisfying a constraint, even when there is a mismatch between the real model and an accessible simulator/nominal model. In particular, we consider the robust constrained Markov decision problem (RCMDP) where an agent needs to maximize the reward and satisfy the constraint against the worst possible stochastic model under the uncertainty set centered around an unknown nominal model. Primal-dual methods, effective for standard constrained MDP (CMDP), are not applicable here because of the lack of the strong duality property. Further, one cannot apply the standard robust value-iteration based approach on the composite value function either as the worst case models may be different for the reward value function and the constraint value function. We propose a novel technique that effectively minimizes the constraint value function--to satisfy the constraints; on the other hand, when all the constraints are satisfied, it can simply maximize the robust reward value function. We prove that such an algorithm finds a policy with at most $\epsilon$ sub-optimality and feasible policy after $O(\epsilon^{-2})$ iterations. In contrast to the state-of-the-art method, we do not need to employ a binary search, thus, we reduce the computation time by at least 4x for smaller value of discount factor ($\gamma$) and by at least 6x for larger value of $\gamma$.
TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
Mar 07, 2025The increasing complexity and scale of Deep Neural Networks (DNNs) necessitate specialized tensor accelerators, such as Tensor Processing Units (TPUs), to meet various computational and energy efficiency requirements. Nevertheless, designing optimal TPU remains challenging due to the high domain expertise level, considerable manual design time, and lack of high-quality, domain-specific datasets. This paper introduces TPU-Gen, the first Large Language Model (LLM) based framework designed to automate the exact and approximate TPU generation process, focusing on systolic array architectures. TPU-Gen is supported with a meticulously curated, comprehensive, and open-source dataset that covers a wide range of spatial array designs and approximate multiply-and-accumulate units, enabling design reuse, adaptation, and customization for different DNN workloads. The proposed framework leverages Retrieval-Augmented Generation (RAG) as an effective solution for a data-scare hardware domain in building LLMs, addressing the most intriguing issue, hallucinations. TPU-Gen transforms high-level architectural specifications into optimized low-level implementations through an effective hardware generation pipeline. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92\% and 96\% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs.
Provably Efficient RL for Linear MDPs under Instantaneous Safety Constraints in Non-Convex Feature Spaces
Feb 25, 2025
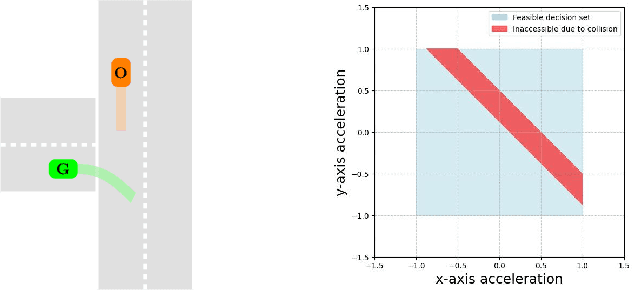
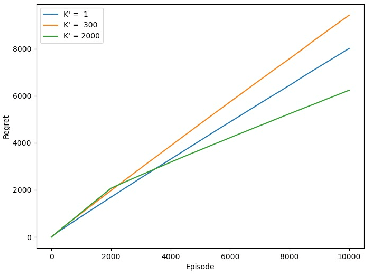
In Reinforcement Learning (RL), tasks with instantaneous hard constraints present significant challenges, particularly when the decision space is non-convex or non-star-convex. This issue is especially relevant in domains like autonomous vehicles and robotics, where constraints such as collision avoidance often take a non-convex form. In this paper, we establish a regret bound of $\tilde{\mathcal{O}}\bigl(\bigl(1 + \tfrac{1}{\tau}\bigr) \sqrt{\log(\tfrac{1}{\tau}) d^3 H^4 K} \bigr)$, applicable to both star-convex and non-star-convex cases, where $d$ is the feature dimension, $H$ the episode length, $K$ the number of episodes, and $\tau$ the safety threshold. Moreover, the violation of safety constraints is zero with high probability throughout the learning process. A key technical challenge in these settings is bounding the covering number of the value-function class, which is essential for achieving value-aware uniform concentration in model-free function approximation. For the star-convex setting, we develop a novel technique called Objective Constraint-Decomposition (OCD) to properly bound the covering number. This result also resolves an error in a previous work on constrained RL. In non-star-convex scenarios, where the covering number can become infinitely large, we propose a two-phase algorithm, Non-Convex Safe Least Squares Value Iteration (NCS-LSVI), which first reduces uncertainty about the safe set by playing a known safe policy. After that, it carefully balances exploration and exploitation to achieve the regret bound. Finally, numerical simulations on an autonomous driving scenario demonstrate the effectiveness of NCS-LSVI.
SPICEPilot: Navigating SPICE Code Generation and Simulation with AI Guidance
Oct 27, 2024



Large Language Models (LLMs) have shown great potential in automating code generation; however, their ability to generate accurate circuit-level SPICE code remains limited due to a lack of hardware-specific knowledge. In this paper, we analyze and identify the typical limitations of existing LLMs in SPICE code generation. To address these limitations, we present SPICEPilot a novel Python-based dataset generated using PySpice, along with its accompanying framework. This marks a significant step forward in automating SPICE code generation across various circuit configurations. Our framework automates the creation of SPICE simulation scripts, introduces standardized benchmarking metrics to evaluate LLM's ability for circuit generation, and outlines a roadmap for integrating LLMs into the hardware design process. SPICEPilot is open-sourced under the permissive MIT license at https://github.com/ACADLab/SPICEPilot.git.
Adversarially Trained Actor Critic for offline CMDPs
Jan 01, 2024We propose a Safe Adversarial Trained Actor Critic (SATAC) algorithm for offline reinforcement learning (RL) with general function approximation in the presence of limited data coverage. SATAC operates as a two-player Stackelberg game featuring a refined objective function. The actor (leader player) optimizes the policy against two adversarially trained value critics (follower players), who focus on scenarios where the actor's performance is inferior to the behavior policy. Our framework provides both theoretical guarantees and a robust deep-RL implementation. Theoretically, we demonstrate that when the actor employs a no-regret optimization oracle, SATAC achieves two guarantees: (i) For the first time in the offline RL setting, we establish that SATAC can produce a policy that outperforms the behavior policy while maintaining the same level of safety, which is critical to designing an algorithm for offline RL. (ii) We demonstrate that the algorithm guarantees policy improvement across a broad range of hyperparameters, indicating its practical robustness. Additionally, we offer a practical version of SATAC and compare it with existing state-of-the-art offline safe-RL algorithms in continuous control environments. SATAC outperforms all baselines across a range of tasks, thus validating the theoretical performance.
Achieving Fairness in Multi-Agent Markov Decision Processes Using Reinforcement Learning
Jun 01, 2023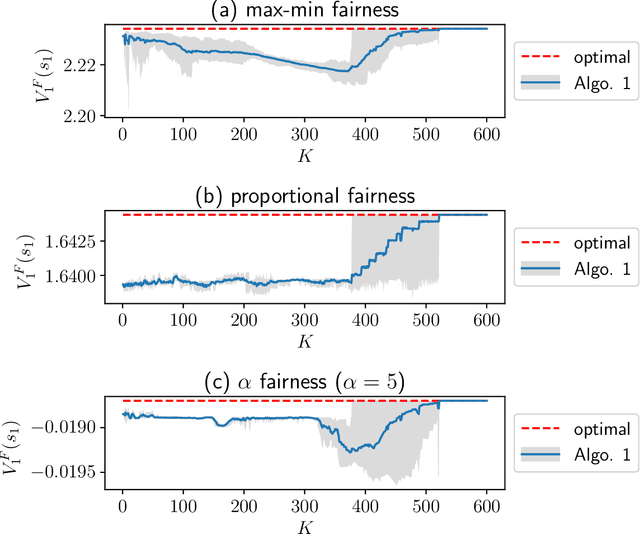
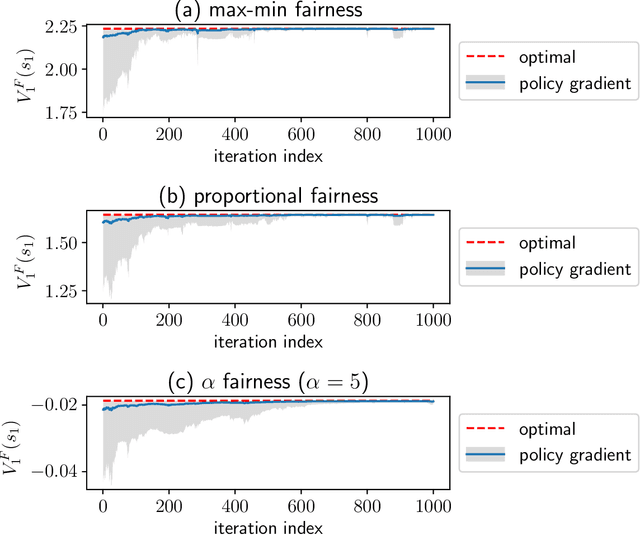
Fairness plays a crucial role in various multi-agent systems (e.g., communication networks, financial markets, etc.). Many multi-agent dynamical interactions can be cast as Markov Decision Processes (MDPs). While existing research has focused on studying fairness in known environments, the exploration of fairness in such systems for unknown environments remains open. In this paper, we propose a Reinforcement Learning (RL) approach to achieve fairness in multi-agent finite-horizon episodic MDPs. Instead of maximizing the sum of individual agents' value functions, we introduce a fairness function that ensures equitable rewards across agents. Since the classical Bellman's equation does not hold when the sum of individual value functions is not maximized, we cannot use traditional approaches. Instead, in order to explore, we maintain a confidence bound of the unknown environment and then propose an online convex optimization based approach to obtain a policy constrained to this confidence region. We show that such an approach achieves sub-linear regret in terms of the number of episodes. Additionally, we provide a probably approximately correct (PAC) guarantee based on the obtained regret bound. We also propose an offline RL algorithm and bound the optimality gap with respect to the optimal fair solution. To mitigate computational complexity, we introduce a policy-gradient type method for the fair objective. Simulation experiments also demonstrate the efficacy of our approach.
Provably Efficient Model-Free Algorithms for Non-stationary CMDPs
Mar 10, 2023We study model-free reinforcement learning (RL) algorithms in episodic non-stationary constrained Markov Decision Processes (CMDPs), in which an agent aims to maximize the expected cumulative reward subject to a cumulative constraint on the expected utility (cost). In the non-stationary environment, reward, utility functions, and transition kernels can vary arbitrarily over time as long as the cumulative variations do not exceed certain variation budgets. We propose the first model-free, simulator-free RL algorithms with sublinear regret and zero constraint violation for non-stationary CMDPs in both tabular and linear function approximation settings with provable performance guarantees. Our results on regret bound and constraint violation for the tabular case match the corresponding best results for stationary CMDPs when the total budget is known. Additionally, we present a general framework for addressing the well-known challenges associated with analyzing non-stationary CMDPs, without requiring prior knowledge of the variation budget. We apply the approach for both tabular and linear approximation settings.
Provably Efficient Model-free RL in Leader-Follower MDP with Linear Function Approximation
Dec 15, 2022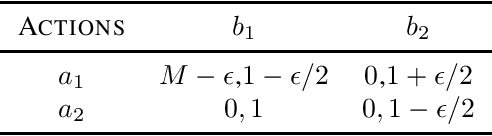

We consider a multi-agent episodic MDP setup where an agent (leader) takes action at each step of the episode followed by another agent (follower). The state evolution and rewards depend on the joint action pair of the leader and the follower. Such type of interactions can find applications in many domains such as smart grids, mechanism design, security, and policymaking. We are interested in how to learn policies for both the players with provable performance guarantee under a bandit feedback setting. We focus on a setup where both the leader and followers are {\em non-myopic}, i.e., they both seek to maximize their rewards over the entire episode and consider a linear MDP which can model continuous state-space which is very common in many RL applications. We propose a {\em model-free} RL algorithm and show that $\tilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret bounds can be achieved for both the leader and the follower, where $d$ is the dimension of the feature mapping, $H$ is the length of the episode, and $T$ is the total number of steps under the bandit feedback information setup. Thus, our result holds even when the number of states becomes infinite. The algorithm relies on {\em novel} adaptation of the LSVI-UCB algorithm. Specifically, we replace the standard greedy policy (as the best response) with the soft-max policy for both the leader and the follower. This turns out to be key in establishing uniform concentration bound for the value functions. To the best of our knowledge, this is the first sub-linear regret bound guarantee for the Markov games with non-myopic followers with function approximation.