 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIM-LLM: A High-Throughput Hybrid PIM Architecture for 1-bit LLMs
Mar 31, 2025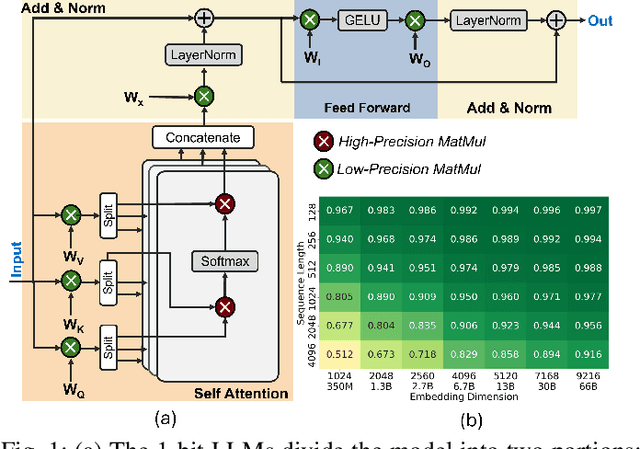
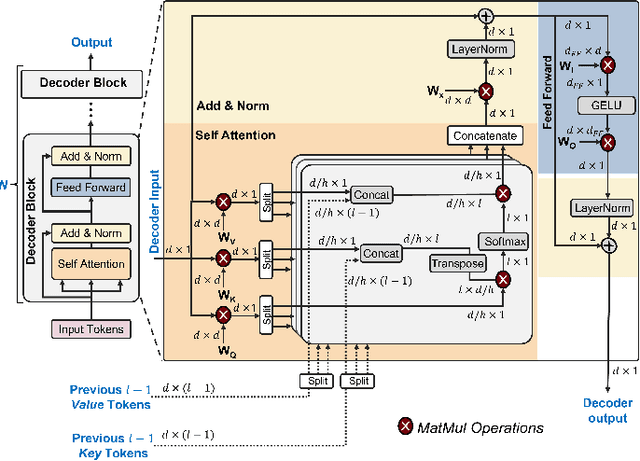
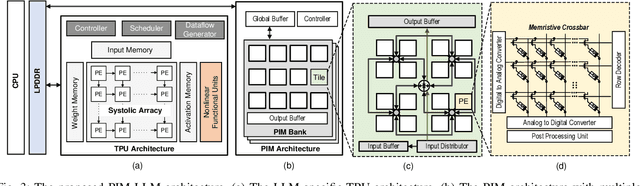
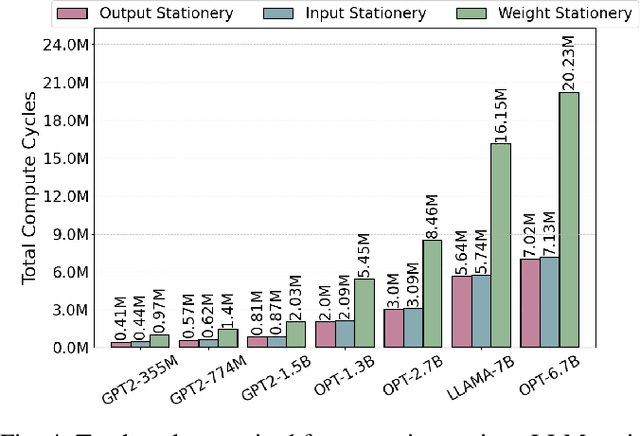
In this paper, we propose PIM-LLM, a hybrid architecture developed to accelerate 1-bit large language models (LLMs). PIM-LLM leverages analog processing-in-memory (PIM) architectures and digital systolic arrays to accelerate low-precision matrix multiplication (MatMul) operations in projection layers and high-precision MatMul operations in attention heads of 1-bit LLMs, respectively. Our design achieves up to roughly 80x improvement in tokens per second and a 70% increase in tokens per joule compared to conventional hardware accelerators. Additionally, PIM-LLM outperforms previous PIM-based LLM accelerators, setting a new benchmark with at least 2x and 5x improvement in GOPS and GOPS/W, respectively.
TPU-Gen: LLM-Driven Custom Tensor Processing Unit Generator
Mar 07, 2025The increasing complexity and scale of Deep Neural Networks (DNNs) necessitate specialized tensor accelerators, such as Tensor Processing Units (TPUs), to meet various computational and energy efficiency requirements. Nevertheless, designing optimal TPU remains challenging due to the high domain expertise level, considerable manual design time, and lack of high-quality, domain-specific datasets. This paper introduces TPU-Gen, the first Large Language Model (LLM) based framework designed to automate the exact and approximate TPU generation process, focusing on systolic array architectures. TPU-Gen is supported with a meticulously curated, comprehensive, and open-source dataset that covers a wide range of spatial array designs and approximate multiply-and-accumulate units, enabling design reuse, adaptation, and customization for different DNN workloads. The proposed framework leverages Retrieval-Augmented Generation (RAG) as an effective solution for a data-scare hardware domain in building LLMs, addressing the most intriguing issue, hallucinations. TPU-Gen transforms high-level architectural specifications into optimized low-level implementations through an effective hardware generation pipeline. Our extensive experimental evaluations demonstrate superior performance, power, and area efficiency, with an average reduction in area and power of 92\% and 96\% from the manual optimization reference values. These results set new standards for driving advancements in next-generation design automation tools powered by LLMs.
Matmul or No Matmal in the Era of 1-bit LLMs
Aug 21, 2024The advent of 1-bit large language models (LLMs) has attracted considerable attention and opened up new research opportunities. However, 1-bit LLMs only improve a fraction of models by applying extreme quantization to the projection layers while leaving attention heads unchanged. Therefore, to avoid fundamentally wrong choices of goals in future research, it is crucial to understand the actual improvements in computation and memory usage that 1-bit LLMs can deliver. In this work, we present an adaptation of Amdahl's Law tailored for the 1-bit LLM context, which illustrates how partial improvements in 1-bit LLMs impact overall model performance. Through extensive experiments, we uncover key nuances across different model architectures and hardware configurations, offering a roadmap for future research in the era of 1-bit LLMs.
IMAC-Sim: A Circuit-level Simulator For In-Memory Analog Computing Architectures
Apr 18, 2023
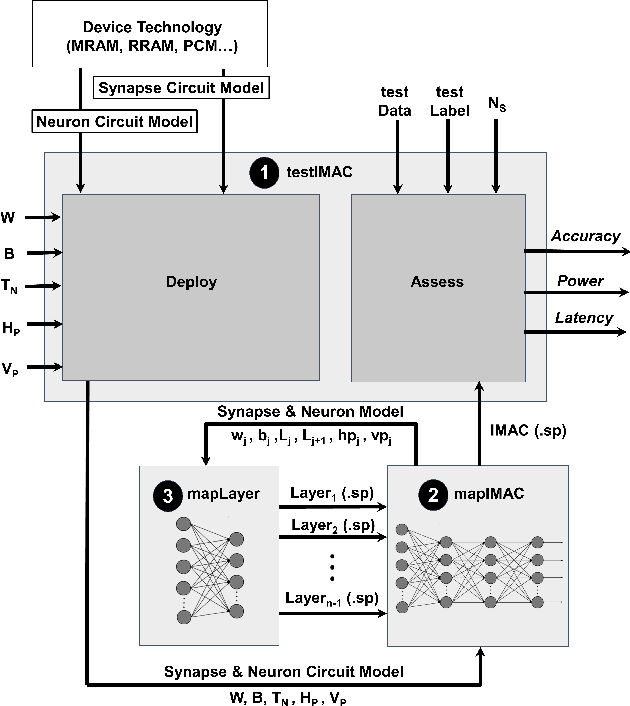


With the increased attention to memristive-based in-memory analog computing (IMAC) architectures as an alternative for energy-hungry computer systems for machine learning applications, a tool that enables exploring their device- and circuit-level design space can significantly boost the research and development in this area. Thus, in this paper, we develop IMAC-Sim, a circuit-level simulator for the design space exploration of IMAC architectures. IMAC-Sim is a Python-based simulation framework, which creates the SPICE netlist of the IMAC circuit based on various device- and circuit-level hyperparameters selected by the user, and automatically evaluates the accuracy, power consumption, and latency of the developed circuit using a user-specified dataset. Moreover, IMAC-Sim simulates the interconnect parasitic resistance and capacitance in the IMAC architectures and is also equipped with horizontal and vertical partitioning techniques to surmount these reliability challenges. IMAC-Sim is a flexible tool that supports a broad range of device- and circuit-level hyperparameters. In this paper, we perform controlled experiments to exhibit some of the important capabilities of the IMAC-Sim, while the entirety of its features is available for researchers via an open-source tool.
Heterogeneous Integration of In-Memory Analog Computing Architectures with Tensor Processing Units
Apr 18, 2023



Tensor processing units (TPUs), specialized hardware accelerators for machine learning tasks, have shown significant performance improvements when executing convolutional layers in convolutional neural networks (CNNs). However, they struggle to maintain the same efficiency in fully connected (FC) layers, leading to suboptimal hardware utilization. In-memory analog computing (IMAC) architectures, on the other hand, have demonstrated notable speedup in executing FC layers. This paper introduces a novel, heterogeneous, mixed-signal, and mixed-precision architecture that integrates an IMAC unit with an edge TPU to enhance mobile CNN performance. To leverage the strengths of TPUs for convolutional layers and IMAC circuits for dense layers, we propose a unified learning algorithm that incorporates mixed-precision training techniques to mitigate potential accuracy drops when deploying models on the TPU-IMAC architecture. The simulations demonstrate that the TPU-IMAC configuration achieves up to $2.59\times$ performance improvements, and $88\%$ memory reductions compared to conventional TPU architectures for various CNN models while maintaining comparable accuracy. The TPU-IMAC architecture shows potential for various applications where energy efficiency and high performance are essential, such as edge computing and real-time processing in mobile devices. The unified training algorithm and the integration of IMAC and TPU architectures contribute to the potential impact of this research on the broader machine learning landscape.