 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning Pipeline for Monkeypox Skin Disease Classification Using CNN Feature Extractors
May 06, 2026Despite the strong performance of Convolutional Neural Networks (CNNs) in disease classification, their effectiveness often depends on access to large annotated datasets, which is an impractical requirement for emerging or rare conditions such as Monkeypox. To overcome this limitation, we propose a few-shot learning (FSL) framework that employs SimpleShot, a lightweight, non-parametric, inductive classifier, for Monkeypox and pox-like skin disease recognition from limited labeled examples. The proposed pipeline passes the skin lesion images through a frozen, pretrained CNN backbone to obtain feature embeddings, which are then classified via SimpleShot using nearest-centroid comparisons in a normalized embedding space. We systematically benchmark six widely used CNN backbones as feature extractors under consistent experimental settings, enabling fair comparison. Experiments on three publicly available datasets (MSLD v1.0, MSID, and MSLD v2.0) are conducted across 2-way, 4-way, and 6-way tasks with 1-shot, 5-shot, and 10-shot configurations. Among all models, MobileNetV2_100 consistently achieves the highest accuracy. In addition, we present a cross-dataset evaluation for Monkeypox classification, revealing that binary Mpox-vs-Others transfer remains comparatively stable while multi-class performance degrades significantly under domain shift. Together, these results demonstrate the practical utility of combining inductive FSL methods with lightweight CNN backbones and highlight the importance of domain robustness for reliable real-world clinical deployment.
SpectroFusion-ViT: A Lightweight Transformer for Speech Emotion Recognition Using Harmonic Mel-Chroma Fusion
Feb 28, 2026Speech is a natural means of conveying emotions, making it an effective method for understanding and representing human feelings. Reliable speech emotion recognition (SER) is central to applications in human-computer interaction, healthcare, education, and customer service. However, most SER methods depend on heavy backbone models or hand-crafted features that fail to balance accuracy and efficiency, particularly for low-resource languages like Bangla. In this work, we present SpectroFusion-ViT, a lightweight SER framework built utilizing EfficientViT-b0, a compact Vision Transformer architecture equipped with self-attention to capture long-range temporal and spectral patterns. The model contains only 2.04M parameters and requires 0.1 GFLOPs, enabling deployment in resource-constrained settings without compromising accuracy. Our pipeline first performs preprocessing and augmentation on raw audio, then extracts Chroma and Mel-frequency cepstral coefficient (MFCC) features. These representations are fused into a complementary time-frequency descriptor that preserves both fine-grained spectral detail and broader harmonic structure. Using transfer learning, EfficientViT-b0 is fine-tuned for multi-class emotion classification. We evaluate the system on two benchmark Bangla emotional speech datasets, SUBESCO and BanglaSER, which vary in speaker diversity, recording conditions, and acoustic characteristics. The proposed approach achieves 92.56% accuracy on SUBESCO and 82.19% on BanglaSER, surpassing existing state-of-the-art methods. These findings demonstrate that lightweight transformer architectures can deliver robust SER performance while remaining computationally efficient for real-world deployment.
From Lightweight CNNs to SpikeNets: Benchmarking Accuracy-Energy Tradeoffs with Pruned Spiking SqueezeNet
Feb 10, 2026Spiking Neural Networks (SNNs) are increasingly studied as energy-efficient alternatives to Convolutional Neural Networks (CNNs), particularly for edge intelligence. However, prior work has largely emphasized large-scale models, leaving the design and evaluation of lightweight CNN-to-SNN pipelines underexplored. In this paper, we present the first systematic benchmark of lightweight SNNs obtained by converting compact CNN architectures into spiking networks, where activations are modeled with Leaky-Integrate-and-Fire (LIF) neurons and trained using surrogate gradient descent under a unified setup. We construct spiking variants of ShuffleNet, SqueezeNet, MnasNet, and MixNet, and evaluate them on CIFAR-10, CIFAR-100, and TinyImageNet, measuring accuracy, F1-score, parameter count, computational complexity, and energy consumption. Our results show that SNNs can achieve up to 15.7x higher energy efficiency than their CNN counterparts while retaining competitive accuracy. Among these, the SNN variant of SqueezeNet consistently outperforms other lightweight SNNs. To further optimize this model, we apply a structured pruning strategy that removes entire redundant modules, yielding a pruned architecture, SNN-SqueezeNet-P. This pruned model improves CIFAR-10 accuracy by 6% and reduces parameters by 19% compared to the original SNN-SqueezeNet. Crucially, it narrows the gap with CNN-SqueezeNet, achieving nearly the same accuracy (only 1% lower) but with an 88.1% reduction in energy consumption due to sparse spike-driven computations. Together, these findings establish lightweight SNNs as practical, low-power alternatives for edge deployment, highlighting a viable path toward deploying high-performance, low-power intelligence on the edge.
Moral Sycophancy in Vision Language Models
Feb 09, 2026Sycophancy in Vision-Language Models (VLMs) refers to their tendency to align with user opinions, often at the expense of moral or factual accuracy. While prior studies have explored sycophantic behavior in general contexts, its impact on morally grounded visual decision-making remains insufficiently understood. To address this gap, we present the first systematic study of moral sycophancy in VLMs, analyzing ten widely-used models on the Moralise and M^3oralBench datasets under explicit user disagreement. Our results reveal that VLMs frequently produce morally incorrect follow-up responses even when their initial judgments are correct, and exhibit a consistent asymmetry: models are more likely to shift from morally right to morally wrong judgments than the reverse when exposed to user-induced bias. Follow-up prompts generally degrade performance on Moralise, while yielding mixed or even improved accuracy on M^3oralBench, highlighting dataset-dependent differences in moral robustness. Evaluation using Error Introduction Rate (EIR) and Error Correction Rate (ECR) reveals a clear trade-off: models with stronger error-correction capabilities tend to introduce more reasoning errors, whereas more conservative models minimize errors but exhibit limited ability to self-correct. Finally, initial contexts with a morally right stance elicit stronger sycophantic behavior, emphasizing the vulnerability of VLMs to moral influence and the need for principled strategies to improve ethical consistency and robustness in multimodal AI systems.
Explainable AI and Machine Learning for Exam-based Student Evaluation: Causal and Predictive Analysis of Socio-academic and Economic Factors
Aug 01, 2025Academic performance depends on a multivariable nexus of socio-academic and financial factors. This study investigates these influences to develop effective strategies for optimizing students' CGPA. To achieve this, we reviewed various literature to identify key influencing factors and constructed an initial hypothetical causal graph based on the findings. Additionally, an online survey was conducted, where 1,050 students participated, providing comprehensive data for analysis. Rigorous data preprocessing techniques, including cleaning and visualization, ensured data quality before analysis. Causal analysis validated the relationships among variables, offering deeper insights into their direct and indirect effects on CGPA. Regression models were implemented for CGPA prediction, while classification models categorized students based on performance levels. Ridge Regression demonstrated strong predictive accuracy, achieving a Mean Absolute Error of 0.12 and a Mean Squared Error of 0.023. Random Forest outperformed in classification, attaining an F1-score near perfection and an accuracy of 98.68%. Explainable AI techniques such as SHAP, LIME, and Interpret enhanced model interpretability, highlighting critical factors such as study hours, scholarships, parental education, and prior academic performance. The study culminated in the development of a web-based application that provides students with personalized insights, allowing them to predict academic performance, identify areas for improvement, and make informed decisions to enhance their outcomes.
VisionTrap: Unanswerable Questions On Visual Data
Jul 23, 2025Visual Question Answering (VQA) has been a widely studied topic, with extensive research focusing on how VLMs respond to answerable questions based on real-world images. However, there has been limited exploration of how these models handle unanswerable questions, particularly in cases where they should abstain from providing a response. This research investigates VQA performance on unrealistically generated images or asking unanswerable questions, assessing whether models recognize the limitations of their knowledge or attempt to generate incorrect answers. We introduced a dataset, VisionTrap, comprising three categories of unanswerable questions across diverse image types: (1) hybrid entities that fuse objects and animals, (2) objects depicted in unconventional or impossible scenarios, and (3) fictional or non-existent figures. The questions posed are logically structured yet inherently unanswerable, testing whether models can correctly recognize their limitations. Our findings highlight the importance of incorporating such questions into VQA benchmarks to evaluate whether models tend to answer, even when they should abstain.
EIM-TRNG: Obfuscating Deep Neural Network Weights with Encoding-in-Memory True Random Number Generator via RowHammer
Jul 03, 2025True Random Number Generators (TRNGs) play a fundamental role in hardware security, cryptographic systems, and data protection. In the context of Deep NeuralNetworks (DNNs), safeguarding model parameters, particularly weights, is critical to ensure the integrity, privacy, and intel-lectual property of AI systems. While software-based pseudo-random number generators are widely used, they lack the unpredictability and resilience offered by hardware-based TRNGs. In this work, we propose a novel and robust Encoding-in-Memory TRNG called EIM-TRNG that leverages the inherent physical randomness in DRAM cell behavior, particularly under RowHammer-induced disturbances, for the first time. We demonstrate how the unpredictable bit-flips generated through carefully controlled RowHammer operations can be harnessed as a reliable entropy source. Furthermore, we apply this TRNG framework to secure DNN weight data by encoding via a combination of fixed and unpredictable bit-flips. The encrypted data is later decrypted using a key derived from the probabilistic flip behavior, ensuring both data confidentiality and model authenticity. Our results validate the effectiveness of DRAM-based entropy extraction for robust, low-cost hardware security and offer a promising direction for protecting machine learning models at the hardware level.
Preemptive Hallucination Reduction: An Input-Level Approach for Multimodal Language Model
May 29, 2025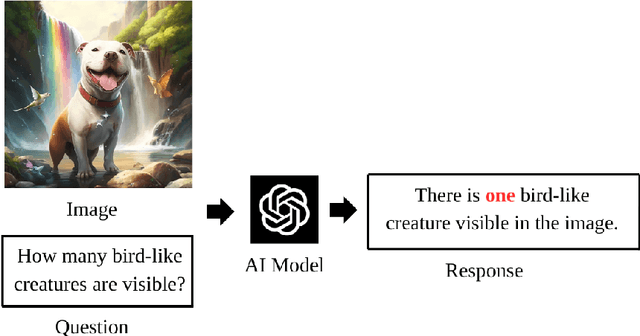

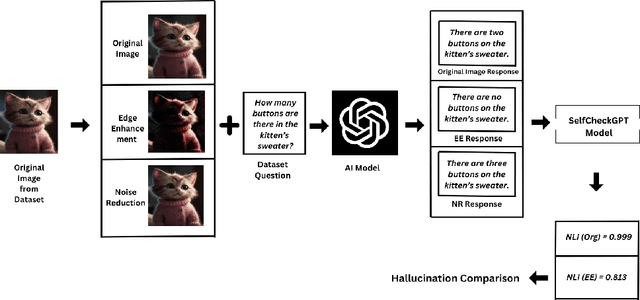
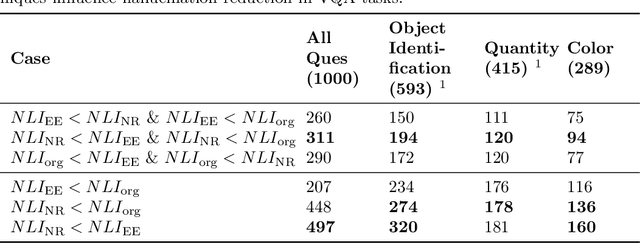
Visual hallucinations in Large Language Models (LLMs), where the model generates responses that are inconsistent with the visual input, pose a significant challenge to their reliability, particularly in contexts where precise and trustworthy outputs are critical. Current research largely emphasizes post-hoc correction or model-specific fine-tuning strategies, with limited exploration of preprocessing techniques to address hallucination issues at the input stage. This study presents a novel ensemble-based preprocessing framework that adaptively selects the most appropriate filtering approach -- noise reduced (NR), edge enhanced (EE), or unaltered input (org) based on the type of question posed, resulting into reduced hallucination without requiring any modifications to the underlying model architecture or training pipeline. Evaluated on the `HaloQuest' dataset -- a benchmark designed to test multimodal reasoning on visually complex inputs, our method achieves a 44.3% reduction in hallucination rates, as measured by Natural Language Inference (NLI) scores using SelfCheckGPT. This demonstrates that intelligent input conditioning alone can significantly enhance factual grounding in LLM responses. The findings highlight the importance of adaptive preprocessing techniques in mitigating hallucinations, paving the way for more reliable multimodal systems capable of addressing real-world challenges.
MangoLeafViT: Leveraging Lightweight Vision Transformer with Runtime Augmentation for Efficient Mango Leaf Disease Classification
May 29, 2025Ensuring food safety is critical due to its profound impact on public health, economic stability, and global supply chains. Cultivation of Mango, a major agricultural product in several South Asian countries, faces high financial losses due to different diseases, affecting various aspects of the entire supply chain. While deep learning-based methods have been explored for mango leaf disease classification, there remains a gap in designing solutions that are computationally efficient and compatible with low-end devices. In this work, we propose a lightweight Vision Transformer-based pipeline with a self-attention mechanism to classify mango leaf diseases, achieving state-of-the-art performance with minimal computational overhead. Our approach leverages global attention to capture intricate patterns among disease types and incorporates runtime augmentation for enhanced performance. Evaluation on the MangoLeafBD dataset demonstrates a 99.43% accuracy, outperforming existing methods in terms of model size, parameter count, and FLOPs count.
Unified Alignment Protocol: Making Sense of the Unlabeled Data in New Domains
May 27, 2025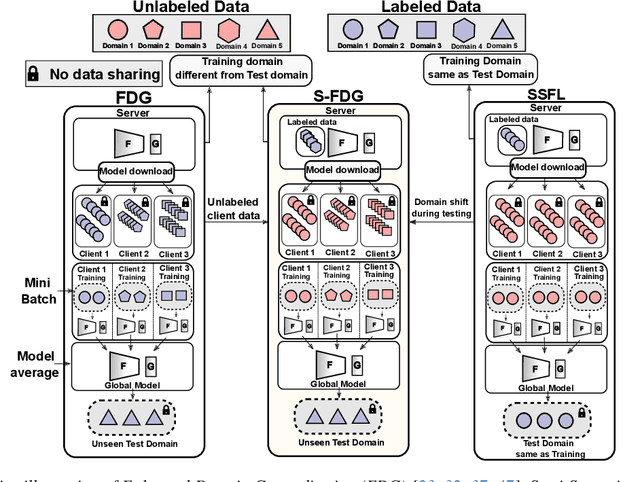

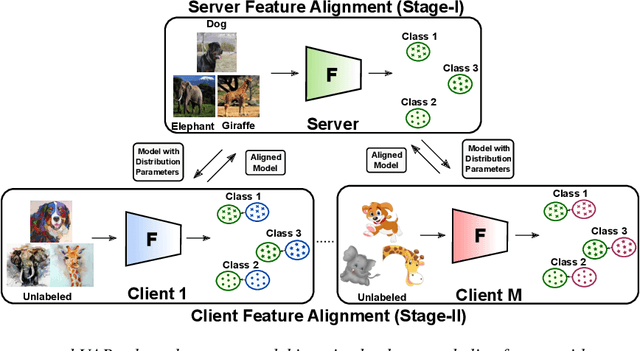
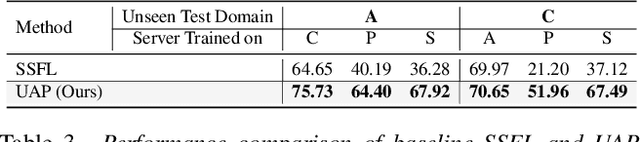
Semi-Supervised Federated Learning (SSFL) is gaining popularity over conventional Federated Learning in many real-world applications. Due to the practical limitation of limited labeled data on the client side, SSFL considers that participating clients train with unlabeled data, and only the central server has the necessary resources to access limited labeled data, making it an ideal fit for real-world applications (e.g., healthcare). However, traditional SSFL assumes that the data distributions in the training phase and testing phase are the same. In practice, however, domain shifts frequently occur, making it essential for SSFL to incorporate generalization capabilities and enhance their practicality. The core challenge is improving model generalization to new, unseen domains while the client participate in SSFL. However, the decentralized setup of SSFL and unsupervised client training necessitates innovation to achieve improved generalization across domains. To achieve this, we propose a novel framework called the Unified Alignment Protocol (UAP), which consists of an alternating two-stage training process. The first stage involves training the server model to learn and align the features with a parametric distribution, which is subsequently communicated to clients without additional communication overhead. The second stage proposes a novel training algorithm that utilizes the server feature distribution to align client features accordingly. Our extensive experiments on standard domain generalization benchmark datasets across multiple model architectures reveal that proposed UAP successfully achieves SOTA generalization performance in SSFL setting.