 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartSumm: A Comprehensive Benchmark for Automatic Chart Summarization of Long and Short Summaries
Apr 29, 2023Automatic chart to text summarization is an effective tool for the visually impaired people along with providing precise insights of tabular data in natural language to the user. A large and well-structured dataset is always a key part for data driven models. In this paper, we propose ChartSumm: a large-scale benchmark dataset consisting of a total of 84,363 charts along with their metadata and descriptions covering a wide range of topics and chart types to generate short and long summaries. Extensive experiments with strong baseline models show that even though these models generate fluent and informative summaries by achieving decent scores in various automatic evaluation metrics, they often face issues like suffering from hallucination, missing out important data points, in addition to incorrect explanation of complex trends in the charts. We also investigated the potential of expanding ChartSumm to other languages using automated translation tools. These make our dataset a challenging benchmark for future research.
An Efficient Transfer Learning-based Approach for Apple Leaf Disease Classification
Apr 10, 2023
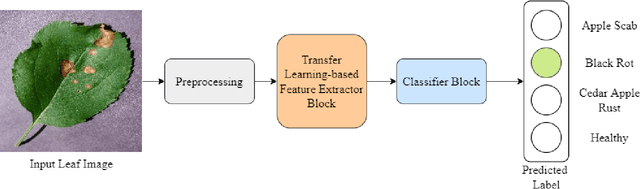
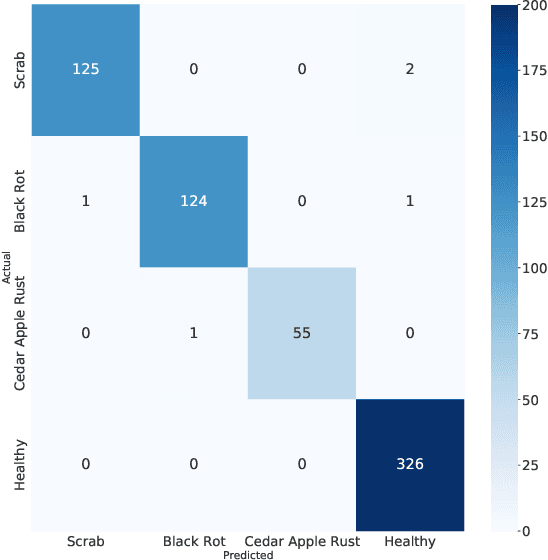
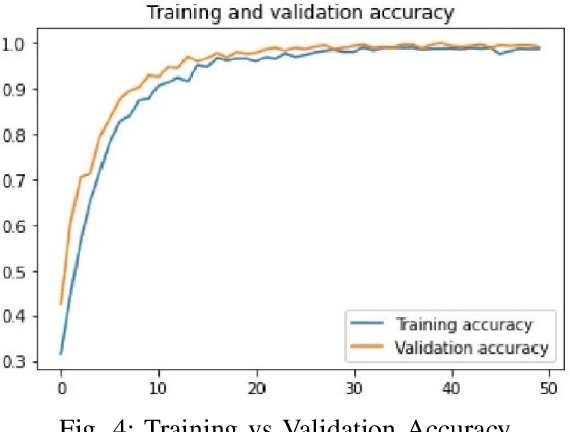
Correct identification and categorization of plant diseases are crucial for ensuring the safety of the global food supply and the overall financial success of stakeholders. In this regard, a wide range of solutions has been made available by introducing deep learning-based classification systems for different staple crops. Despite being one of the most important commercial crops in many parts of the globe, research proposing a smart solution for automatically classifying apple leaf diseases remains relatively unexplored. This study presents a technique for identifying apple leaf diseases based on transfer learning. The system extracts features using a pretrained EfficientNetV2S architecture and passes to a classifier block for effective prediction. The class imbalance issues are tackled by utilizing runtime data augmentation. The effect of various hyperparameters, such as input resolution, learning rate, number of epochs, etc., has been investigated carefully. The competence of the proposed pipeline has been evaluated on the apple leaf disease subset from the publicly available `PlantVillage' dataset, where it achieved an accuracy of 99.21%, outperforming the existing works.
Two Decades of Bengali Handwritten Digit Recognition: A Survey
Jun 05, 2022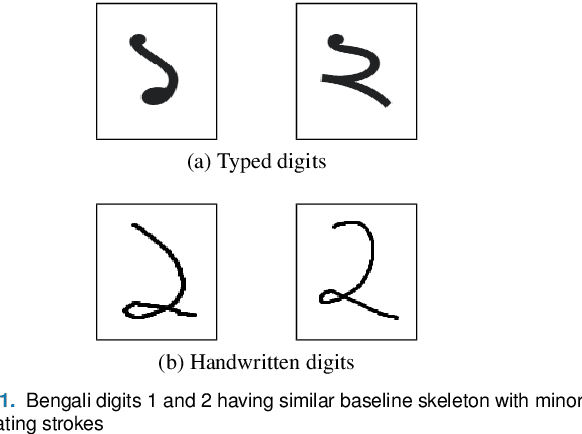
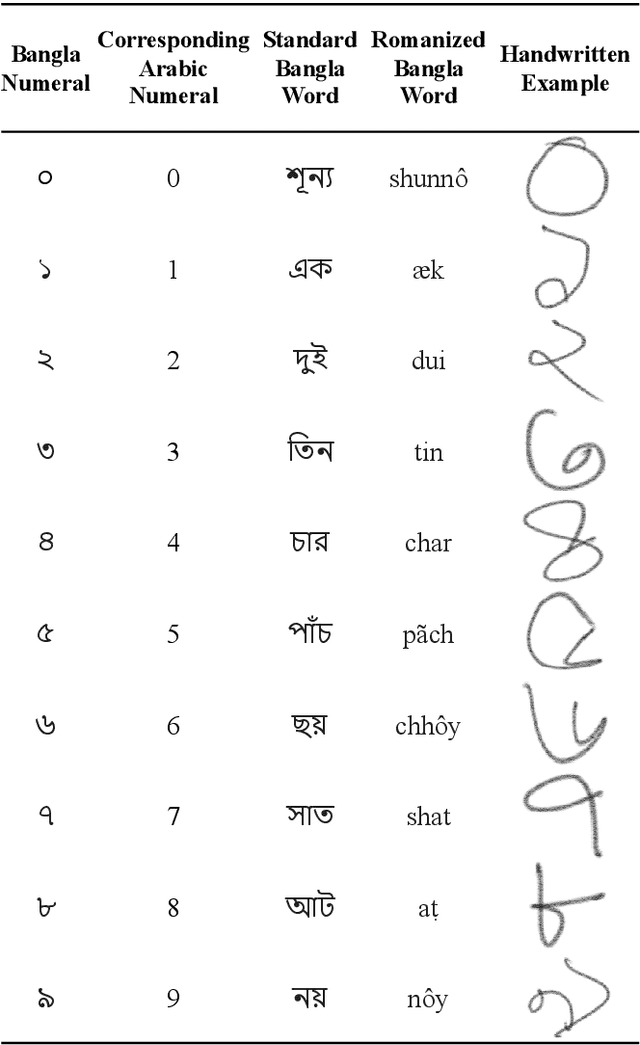
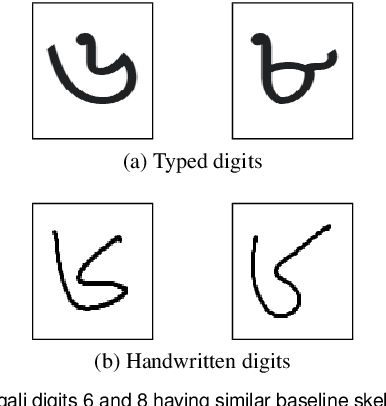

Handwritten Digit Recognition (HDR) is one of the most challenging tasks in the domain of Optical Character Recognition (OCR). Irrespective of language, there are some inherent challenges of HDR, which mostly arise due to the variations in writing styles across individuals, writing medium and environment, inability to maintain the same strokes while writing any digit repeatedly, etc. In addition to that, the structural complexities of the digits of a particular language may lead to ambiguous scenarios of HDR. Over the years, researchers have developed numerous offline and online HDR pipelines, where different image processing techniques are combined with traditional Machine Learning (ML)-based and/or Deep Learning (DL)-based architectures. Although evidence of extensive review studies on HDR exists in the literature for languages, such as: English, Arabic, Indian, Farsi, Chinese, etc., few surveys on Bengali HDR (BHDR) can be found, which lack a comprehensive analysis of the challenges, the underlying recognition process, and possible future directions. In this paper, the characteristics and inherent ambiguities of Bengali handwritten digits along with a comprehensive insight of two decades of the state-of-the-art datasets and approaches towards offline BHDR have been analyzed. Furthermore, several real-life application-specific studies, which involve BHDR, have also been discussed in detail. This paper will also serve as a compendium for researchers interested in the science behind offline BHDR, instigating the exploration of newer avenues of relevant research that may further lead to better offline recognition of Bengali handwritten digits in different application areas.