 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
XCR-Bench: A Multi-Task Benchmark for Evaluating Cultural Reasoning in LLMs
Jan 20, 2026Cross-cultural competence in large language models (LLMs) requires the ability to identify Culture-Specific Items (CSIs) and to adapt them appropriately across cultural contexts. Progress in evaluating this capability has been constrained by the scarcity of high-quality CSI-annotated corpora with parallel cross-cultural sentence pairs. To address this limitation, we introduce XCR-Bench, a Cross(X)-Cultural Reasoning Benchmark consisting of 4.9k parallel sentences and 1,098 unique CSIs, spanning three distinct reasoning tasks with corresponding evaluation metrics. Our corpus integrates Newmark's CSI framework with Hall's Triad of Culture, enabling systematic analysis of cultural reasoning beyond surface-level artifacts and into semi-visible and invisible cultural elements such as social norms, beliefs, and values. Our findings show that state-of-the-art LLMs exhibit consistent weaknesses in identifying and adapting CSIs related to social etiquette and cultural reference. Additionally, we find evidence that LLMs encode regional and ethno-religious biases even within a single linguistic setting during cultural adaptation. We release our corpus and code to facilitate future research on cross-cultural NLP.
Vision Language Models for Optimization-Driven Intent Processing in Autonomous Networks
Jan 19, 2026Intent-Based Networking (IBN) allows operators to specify high-level network goals rather than low-level configurations. While recent work demonstrates that large language models can automate configuration tasks, a distinct class of intents requires generating optimization code to compute provably optimal solutions for traffic engineering, routing, and resource allocation. Current systems assume text-based intent expression, requiring operators to enumerate topologies and parameters in prose. Network practitioners naturally reason about structure through diagrams, yet whether Vision-Language Models (VLMs) can process annotated network sketches into correct optimization code remains unexplored. We present IntentOpt, a benchmark of 85 optimization problems across 17 categories, evaluating four VLMs (GPT-5-Mini, Claude-Haiku-4.5, Gemini-2.5-Flash, Llama-3.2-11B-Vision) under three prompting strategies on multimodal versus text-only inputs. Our evaluation shows that visual parameter extraction reduces execution success by 12-21 percentage points (pp), with GPT-5-Mini dropping from 93% to 72%. Program-of-thought prompting decreases performance by up to 13 pp, and open-source models lag behind closed-source ones, with Llama-3.2-11B-Vision reaching 18% compared to 75% for GPT-5-Mini. These results establish baseline capabilities and limitations of current VLMs for optimization code generation within an IBN system. We also demonstrate practical feasibility through a case study that deploys VLM-generated code to network testbed infrastructure using Model Context Protocol.
Semantic Label Drift in Cross-Cultural Translation
Oct 29, 2025Machine Translation (MT) is widely employed to address resource scarcity in low-resource languages by generating synthetic data from high-resource counterparts. While sentiment preservation in translation has long been studied, a critical but underexplored factor is the role of cultural alignment between source and target languages. In this paper, we hypothesize that semantic labels are drifted or altered during MT due to cultural divergence. Through a series of experiments across culturally sensitive and neutral domains, we establish three key findings: (1) MT systems, including modern Large Language Models (LLMs), induce label drift during translation, particularly in culturally sensitive domains; (2) unlike earlier statistical MT tools, LLMs encode cultural knowledge, and leveraging this knowledge can amplify label drift; and (3) cultural similarity or dissimilarity between source and target languages is a crucial determinant of label preservation. Our findings highlight that neglecting cultural factors in MT not only undermines label fidelity but also risks misinterpretation and cultural conflict in downstream applications.
SLA-Centric Automated Algorithm Selection Framework for Cloud Environments
Jul 29, 2025



Cloud computing offers on-demand resource access, regulated by Service-Level Agreements (SLAs) between consumers and Cloud Service Providers (CSPs). SLA violations can impact efficiency and CSP profitability. In this work, we propose an SLA-aware automated algorithm-selection framework for combinatorial optimization problems in resource-constrained cloud environments. The framework uses an ensemble of machine learning models to predict performance and rank algorithm-hardware pairs based on SLA constraints. We also apply our framework to the 0-1 knapsack problem. We curate a dataset comprising instance specific features along with memory usage, runtime, and optimality gap for 6 algorithms. As an empirical benchmark, we evaluate the framework on both classification and regression tasks. Our ablation study explores the impact of hyperparameters, learning approaches, and large language models effectiveness in regression, and SHAP-based interpretability.
CHORUS: Zero-shot Hierarchical Retrieval and Orchestration for Generating Linear Programming Code
May 02, 2025
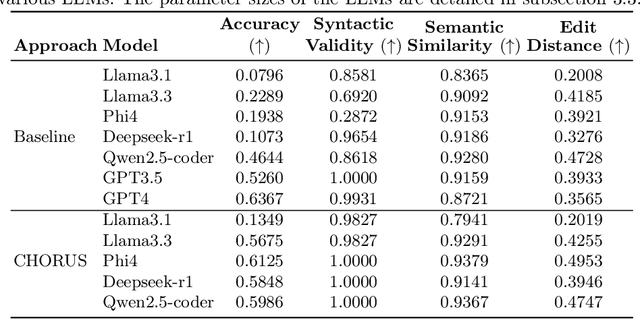

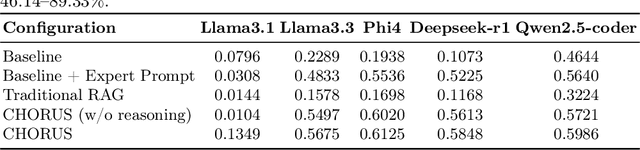
Linear Programming (LP) problems aim to find the optimal solution to an objective under constraints. These problems typically require domain knowledge, mathematical skills, and programming ability, presenting significant challenges for non-experts. This study explores the efficiency of Large Language Models (LLMs) in generating solver-specific LP code. We propose CHORUS, a retrieval-augmented generation (RAG) framework for synthesizing Gurobi-based LP code from natural language problem statements. CHORUS incorporates a hierarchical tree-like chunking strategy for theoretical contents and generates additional metadata based on code examples from documentation to facilitate self-contained, semantically coherent retrieval. Two-stage retrieval approach of CHORUS followed by cross-encoder reranking further ensures contextual relevance. Finally, expertly crafted prompt and structured parser with reasoning steps improve code generation performance significantly. Experiments on the NL4Opt-Code benchmark show that CHORUS improves the performance of open-source LLMs such as Llama3.1 (8B), Llama3.3 (70B), Phi4 (14B), Deepseek-r1 (32B), and Qwen2.5-coder (32B) by a significant margin compared to baseline and conventional RAG. It also allows these open-source LLMs to outperform or match the performance of much stronger baselines-GPT3.5 and GPT4 while requiring far fewer computational resources. Ablation studies further demonstrate the importance of expert prompting, hierarchical chunking, and structured reasoning.
Precision Cancer Classification and Biomarker Identification from mRNA Gene Expression via Dimensionality Reduction and Explainable AI
Oct 08, 2024Gene expression analysis is a critical method for cancer classification, enabling precise diagnoses through the identification of unique molecular signatures associated with various tumors. Identifying cancer-specific genes from gene expression values enables a more tailored and personalized treatment approach. However, the high dimensionality of mRNA gene expression data poses challenges for analysis and data extraction. This research presents a comprehensive pipeline designed to accurately identify 33 distinct cancer types and their corresponding gene sets. It incorporates a combination of normalization and feature selection techniques to reduce dataset dimensionality effectively while ensuring high performance. Notably, our pipeline successfully identifies a substantial number of cancer-specific genes using a reduced feature set of just 500, in contrast to using the full dataset comprising 19,238 features. By employing an ensemble approach that combines three top-performing classifiers, a classification accuracy of 96.61% was achieved. Furthermore, we leverage Explainable AI to elucidate the biological significance of the identified cancer-specific genes, employing Differential Gene Expression (DGE) analysis.
Nuclei Instance Segmentation of Cryosectioned H&E Stained Histological Images using Triple U-Net Architecture
Apr 19, 2024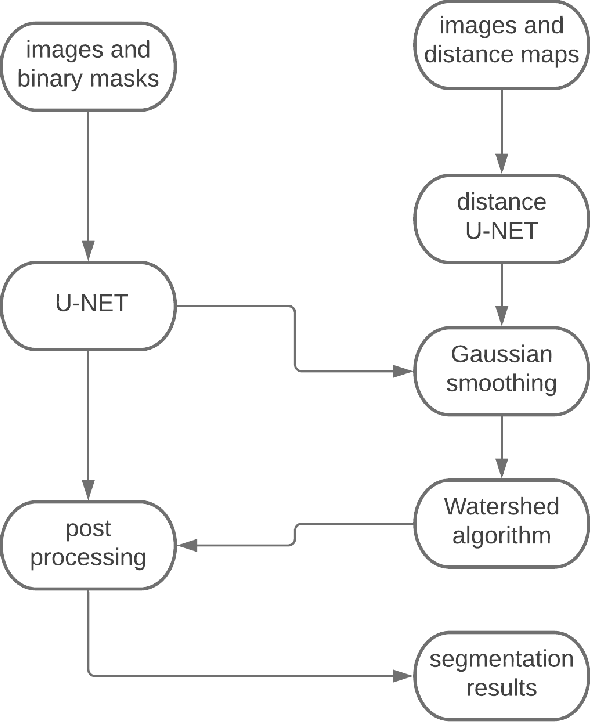

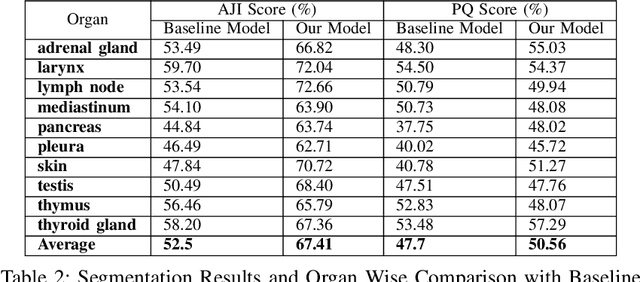
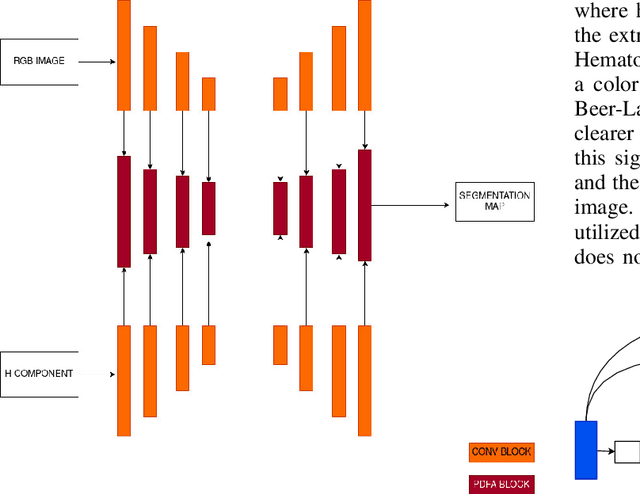
Nuclei instance segmentation is crucial in oncological diagnosis and cancer pathology research. H&E stained images are commonly used for medical diagnosis, but pre-processing is necessary before using them for image processing tasks. Two principal pre-processing methods are formalin-fixed paraffin-embedded samples (FFPE) and frozen tissue samples (FS). While FFPE is widely used, it is time-consuming, while FS samples can be processed quickly. Analyzing H&E stained images derived from fast sample preparation, staining, and scanning can pose difficulties due to the swift process, which can result in the degradation of image quality. This paper proposes a method that leverages the unique optical characteristics of H&E stained images. A three-branch U-Net architecture has been implemented, where each branch contributes to the final segmentation results. The process includes applying watershed algorithm to separate overlapping regions and enhance accuracy. The Triple U-Net architecture comprises an RGB branch, a Hematoxylin branch, and a Segmentation branch. This study focuses on a novel dataset named CryoNuSeg. The results obtained through robust experiments outperform the state-of-the-art results across various metrics. The benchmark score for this dataset is AJI 52.5 and PQ 47.7, achieved through the implementation of U-Net Architecture. However, the proposed Triple U-Net architecture achieves an AJI score of 67.41 and PQ of 50.56. The proposed architecture improves more on AJI than other evaluation metrics, which further justifies the superiority of the Triple U-Net architecture over the baseline U-Net model, as AJI is a more strict evaluation metric. The use of the three-branch U-Net model, followed by watershed post-processing, significantly surpasses the benchmark scores, showing substantial improvement in the AJI score
LM4OPT: Unveiling the Potential of Large Language Models in Formulating Mathematical Optimization Problems
Mar 02, 2024In the rapidly evolving field of natural language processing, the translation of linguistic descriptions into mathematical formulation of optimization problems presents a formidable challenge, demanding intricate understanding and processing capabilities from Large Language Models (LLMs). This study compares prominent LLMs, including GPT-3.5, GPT-4, and Llama-2-7b, in zero-shot and one-shot settings for this task. Our findings show GPT-4's superior performance, particularly in the one-shot scenario. A central part of this research is the introduction of `LM4OPT,' a progressive fine-tuning framework for Llama-2-7b that utilizes noisy embeddings and specialized datasets. However, this research highlights a notable gap in the contextual understanding capabilities of smaller models such as Llama-2-7b compared to larger counterparts, especially in processing lengthy and complex input contexts. Our empirical investigation, utilizing the NL4Opt dataset, unveils that GPT-4 surpasses the baseline performance established by previous research, achieving an F1-score of 0.63, solely based on the problem description in natural language, and without relying on any additional named entity information. GPT-3.5 follows closely, both outperforming the fine-tuned Llama-2-7b. These findings not only benchmark the current capabilities of LLMs in a novel application area but also lay the groundwork for future improvements in mathematical formulation of optimization problems from natural language input.
Linguistic Intelligence in Large Language Models for Telecommunications
Feb 24, 2024



Large Language Models (LLMs) have emerged as a significant advancement in the field of Natural Language Processing (NLP), demonstrating remarkable capabilities in language generation and other language-centric tasks. Despite their evaluation across a multitude of analytical and reasoning tasks in various scientific domains, a comprehensive exploration of their knowledge and understanding within the realm of natural language tasks in the telecommunications domain is still needed. This study, therefore, seeks to evaluate the knowledge and understanding capabilities of LLMs within this domain. To achieve this, we conduct an exhaustive zero-shot evaluation of four prominent LLMs-Llama-2, Falcon, Mistral, and Zephyr. These models require fewer resources than ChatGPT, making them suitable for resource-constrained environments. Their performance is compared with state-of-the-art, fine-tuned models. To the best of our knowledge, this is the first work to extensively evaluate and compare the understanding of LLMs across multiple language-centric tasks in this domain. Our evaluation reveals that zero-shot LLMs can achieve performance levels comparable to the current state-of-the-art fine-tuned models. This indicates that pretraining on extensive text corpora equips LLMs with a degree of specialization, even within the telecommunications domain. We also observe that no single LLM consistently outperforms others, and the performance of different LLMs can fluctuate. Although their performance lags behind fine-tuned models, our findings underscore the potential of LLMs as a valuable resource for understanding various aspects of this field that lack large annotated data.