 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Language Models for Optimization-Driven Intent Processing in Autonomous Networks
Jan 19, 2026Intent-Based Networking (IBN) allows operators to specify high-level network goals rather than low-level configurations. While recent work demonstrates that large language models can automate configuration tasks, a distinct class of intents requires generating optimization code to compute provably optimal solutions for traffic engineering, routing, and resource allocation. Current systems assume text-based intent expression, requiring operators to enumerate topologies and parameters in prose. Network practitioners naturally reason about structure through diagrams, yet whether Vision-Language Models (VLMs) can process annotated network sketches into correct optimization code remains unexplored. We present IntentOpt, a benchmark of 85 optimization problems across 17 categories, evaluating four VLMs (GPT-5-Mini, Claude-Haiku-4.5, Gemini-2.5-Flash, Llama-3.2-11B-Vision) under three prompting strategies on multimodal versus text-only inputs. Our evaluation shows that visual parameter extraction reduces execution success by 12-21 percentage points (pp), with GPT-5-Mini dropping from 93% to 72%. Program-of-thought prompting decreases performance by up to 13 pp, and open-source models lag behind closed-source ones, with Llama-3.2-11B-Vision reaching 18% compared to 75% for GPT-5-Mini. These results establish baseline capabilities and limitations of current VLMs for optimization code generation within an IBN system. We also demonstrate practical feasibility through a case study that deploys VLM-generated code to network testbed infrastructure using Model Context Protocol.
mind_call: A Dataset for Mental Health Function Calling with Large Language Models
Jan 11, 2026Large Language Model (LLM)-based systems increasingly rely on function calling to enable structured and controllable interaction with external data sources, yet existing datasets do not address mental health-oriented access to wearable sensor data. This paper presents a synthetic function-calling dataset designed for mental health assistance grounded in wearable health signals such as sleep, physical activity, cardiovascular measures, stress indicators, and metabolic data. The dataset maps diverse natural language queries to standardized API calls derived from a widely adopted health data schema. Each sample includes a user query, a query category, an explicit reasoning step, a normalized temporal parameter, and a target function. The dataset covers explicit, implicit, behavioral, symptom-based, and metaphorical expressions, which reflect realistic mental health-related user interactions. This resource supports research on intent grounding, temporal reasoning, and reliable function invocation in LLM-based mental health agents and is publicly released to promote reproducibility and future work.
SLA-Centric Automated Algorithm Selection Framework for Cloud Environments
Jul 29, 2025Cloud computing offers on-demand resource access, regulated by Service-Level Agreements (SLAs) between consumers and Cloud Service Providers (CSPs). SLA violations can impact efficiency and CSP profitability. In this work, we propose an SLA-aware automated algorithm-selection framework for combinatorial optimization problems in resource-constrained cloud environments. The framework uses an ensemble of machine learning models to predict performance and rank algorithm-hardware pairs based on SLA constraints. We also apply our framework to the 0-1 knapsack problem. We curate a dataset comprising instance specific features along with memory usage, runtime, and optimality gap for 6 algorithms. As an empirical benchmark, we evaluate the framework on both classification and regression tasks. Our ablation study explores the impact of hyperparameters, learning approaches, and large language models effectiveness in regression, and SHAP-based interpretability.
CHORUS: Zero-shot Hierarchical Retrieval and Orchestration for Generating Linear Programming Code
May 02, 2025
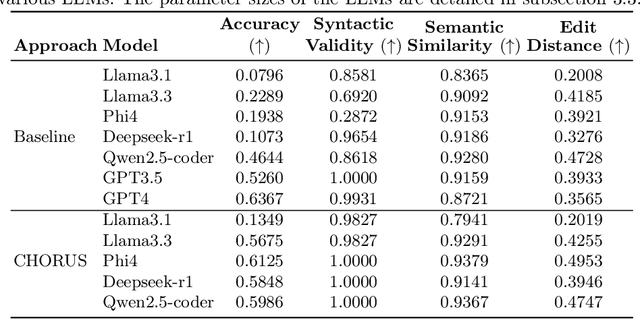

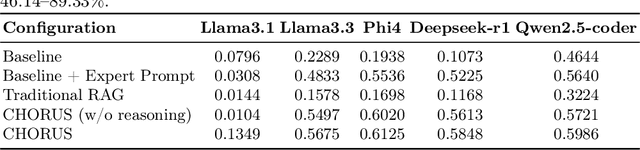
Linear Programming (LP) problems aim to find the optimal solution to an objective under constraints. These problems typically require domain knowledge, mathematical skills, and programming ability, presenting significant challenges for non-experts. This study explores the efficiency of Large Language Models (LLMs) in generating solver-specific LP code. We propose CHORUS, a retrieval-augmented generation (RAG) framework for synthesizing Gurobi-based LP code from natural language problem statements. CHORUS incorporates a hierarchical tree-like chunking strategy for theoretical contents and generates additional metadata based on code examples from documentation to facilitate self-contained, semantically coherent retrieval. Two-stage retrieval approach of CHORUS followed by cross-encoder reranking further ensures contextual relevance. Finally, expertly crafted prompt and structured parser with reasoning steps improve code generation performance significantly. Experiments on the NL4Opt-Code benchmark show that CHORUS improves the performance of open-source LLMs such as Llama3.1 (8B), Llama3.3 (70B), Phi4 (14B), Deepseek-r1 (32B), and Qwen2.5-coder (32B) by a significant margin compared to baseline and conventional RAG. It also allows these open-source LLMs to outperform or match the performance of much stronger baselines-GPT3.5 and GPT4 while requiring far fewer computational resources. Ablation studies further demonstrate the importance of expert prompting, hierarchical chunking, and structured reasoning.
LM4OPT: Unveiling the Potential of Large Language Models in Formulating Mathematical Optimization Problems
Mar 02, 2024In the rapidly evolving field of natural language processing, the translation of linguistic descriptions into mathematical formulation of optimization problems presents a formidable challenge, demanding intricate understanding and processing capabilities from Large Language Models (LLMs). This study compares prominent LLMs, including GPT-3.5, GPT-4, and Llama-2-7b, in zero-shot and one-shot settings for this task. Our findings show GPT-4's superior performance, particularly in the one-shot scenario. A central part of this research is the introduction of `LM4OPT,' a progressive fine-tuning framework for Llama-2-7b that utilizes noisy embeddings and specialized datasets. However, this research highlights a notable gap in the contextual understanding capabilities of smaller models such as Llama-2-7b compared to larger counterparts, especially in processing lengthy and complex input contexts. Our empirical investigation, utilizing the NL4Opt dataset, unveils that GPT-4 surpasses the baseline performance established by previous research, achieving an F1-score of 0.63, solely based on the problem description in natural language, and without relying on any additional named entity information. GPT-3.5 follows closely, both outperforming the fine-tuned Llama-2-7b. These findings not only benchmark the current capabilities of LLMs in a novel application area but also lay the groundwork for future improvements in mathematical formulation of optimization problems from natural language input.
Linguistic Intelligence in Large Language Models for Telecommunications
Feb 24, 2024



Large Language Models (LLMs) have emerged as a significant advancement in the field of Natural Language Processing (NLP), demonstrating remarkable capabilities in language generation and other language-centric tasks. Despite their evaluation across a multitude of analytical and reasoning tasks in various scientific domains, a comprehensive exploration of their knowledge and understanding within the realm of natural language tasks in the telecommunications domain is still needed. This study, therefore, seeks to evaluate the knowledge and understanding capabilities of LLMs within this domain. To achieve this, we conduct an exhaustive zero-shot evaluation of four prominent LLMs-Llama-2, Falcon, Mistral, and Zephyr. These models require fewer resources than ChatGPT, making them suitable for resource-constrained environments. Their performance is compared with state-of-the-art, fine-tuned models. To the best of our knowledge, this is the first work to extensively evaluate and compare the understanding of LLMs across multiple language-centric tasks in this domain. Our evaluation reveals that zero-shot LLMs can achieve performance levels comparable to the current state-of-the-art fine-tuned models. This indicates that pretraining on extensive text corpora equips LLMs with a degree of specialization, even within the telecommunications domain. We also observe that no single LLM consistently outperforms others, and the performance of different LLMs can fluctuate. Although their performance lags behind fine-tuned models, our findings underscore the potential of LLMs as a valuable resource for understanding various aspects of this field that lack large annotated data.
A Multi-faceted Semi-Synthetic Dataset for Automated Cyberbullying Detection
Feb 09, 2024



In recent years, the rising use of social media has propelled automated cyberbullying detection into a prominent research domain. However, challenges persist due to the absence of a standardized definition and universally accepted datasets. Many researchers now view cyberbullying as a facet of cyberaggression, encompassing factors like repetition, peer relationships, and harmful intent in addition to online aggression. Acquiring comprehensive data reflective of all cyberbullying components from social media networks proves to be a complex task. This paper provides a description of an extensive semi-synthetic cyberbullying dataset that incorporates all of the essential aspects of cyberbullying, including aggression, repetition, peer relationships, and intent to harm. The method of creating the dataset is succinctly outlined, and a detailed overview of the publicly accessible dataset is additionally presented. This accompanying data article provides an in-depth look at the dataset, increasing transparency and enabling replication. It also aids in a deeper understanding of the data, supporting broader research use.
Utilizing Deep Learning to Identify Drug Use on Twitter Data
Mar 08, 2020

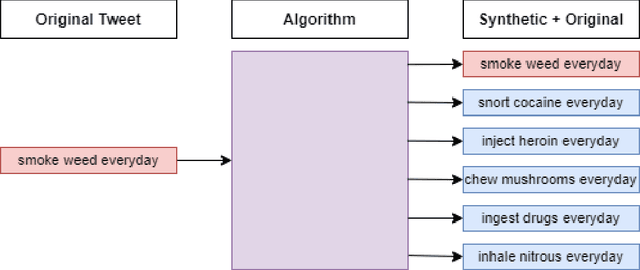

The collection and examination of social media has become a useful mechanism for studying the mental activity and behavior tendencies of users. Through the analysis of collected Twitter data, models were developed for classifying drug-related tweets. Using topic pertaining keywords, such as slang and methods of drug consumption, a set of tweets was generated. Potential candidates were then preprocessed resulting in a dataset of 3,696,150 rows. The classification power of multiple methods was compared including support vector machines (SVM), XGBoost, and convolutional neural network (CNN) based classifiers. Rather than simple feature or attribute analysis, a deep learning approach was implemented to screen and analyze the tweets' semantic meaning. The two CNN-based classifiers presented the best result when compared against other methodologies. The first was trained with 2,661 manually labeled samples, while the other included synthetically generated tweets culminating in 12,142 samples. The accuracy scores were 76.35% and 82.31%, with an AUC of 0.90 and 0.91. Additionally, association rule mining showed that commonly mentioned drugs had a level of correspondence with frequently used illicit substances, proving the practical usefulness of the system. Lastly, the synthetically generated set provided increased scores, improving the classification capability and proving the worth of this methodology.
Algorithms for Optimizing Fleet Scheduling of Air Ambulances
Feb 25, 2020

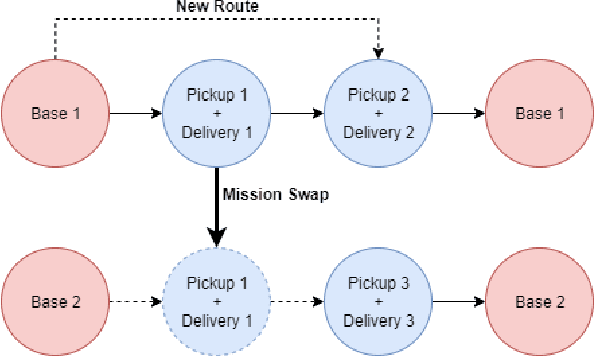

Proper scheduling of air assets can be the difference between life and death for a patient. While poor scheduling can be incredibly problematic during hospital transfers, it can be potentially catastrophic in the case of a disaster. These issues are amplified in the case of an air emergency medical service (EMS) system where populations are dispersed, and resources are limited. There are exact methodologies existing for scheduling missions, although actual calculation times can be quite significant given a large enough problem space. For this research, known coordinates of air and health facilities were used in conjunction with a formulated integer linear programming model. This was the programmed through Gurobi so that performance could be compared against custom algorithmic solutions. Two methods were developed, one based on neighbourhood search and the other on Tabu search. While both were able to achieve results quite close to the Gurobi solution, the Tabu search outperformed the former algorithm. Additionally, it was able to do so in a greatly decreased time, with Gurobi actually being unable to resolve to optimal in larger examples. Parallel variations were also developed with the compute unified device architecture (CUDA), though did not improve the timing given the smaller sample size.
Algorithms for Optimizing Fleet Staging of Air Ambulances
Feb 25, 2020



In a disaster situation, air ambulance rapid response will often be the determining factor in patient survival. Obstacles intensify this circumstance, with geographical remoteness and limitations in vehicle placement making it an arduous task. Considering these elements, the arrangement of responders is a critical decision of the utmost importance. Utilizing real mission data, this research structured an optimal coverage problem with integer linear programming. For accurate comparison, the Gurobi optimizer was programmed with the developed model and timed for performance. A solution implementing base ranking followed by both local and Tabu search-based algorithms was created. The local search algorithm proved insufficient for maximizing coverage, while the Tabu search achieved near-optimal results. In the latter case, the total vehicle travel distance was minimized and the runtime significantly outperformed the one generated by Gurobi. Furthermore, variations utilizing parallel CUDA processing further decreased the algorithmic runtime. These proved superior as the number of test missions increased, while also maintaining the same minimized distance.