 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-faceted Semi-Synthetic Dataset for Automated Cyberbullying Detection
Feb 09, 2024



In recent years, the rising use of social media has propelled automated cyberbullying detection into a prominent research domain. However, challenges persist due to the absence of a standardized definition and universally accepted datasets. Many researchers now view cyberbullying as a facet of cyberaggression, encompassing factors like repetition, peer relationships, and harmful intent in addition to online aggression. Acquiring comprehensive data reflective of all cyberbullying components from social media networks proves to be a complex task. This paper provides a description of an extensive semi-synthetic cyberbullying dataset that incorporates all of the essential aspects of cyberbullying, including aggression, repetition, peer relationships, and intent to harm. The method of creating the dataset is succinctly outlined, and a detailed overview of the publicly accessible dataset is additionally presented. This accompanying data article provides an in-depth look at the dataset, increasing transparency and enabling replication. It also aids in a deeper understanding of the data, supporting broader research use.
An Overview of Violence Detection Techniques: Current Challenges and Future Directions
Sep 21, 2022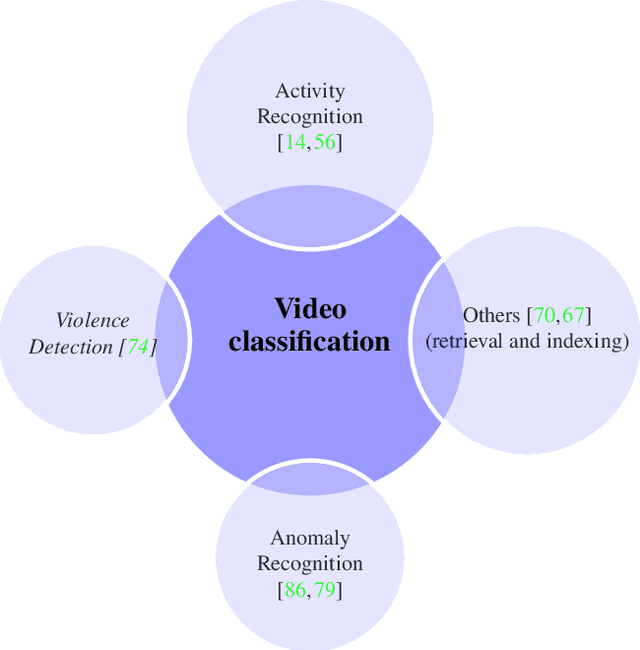
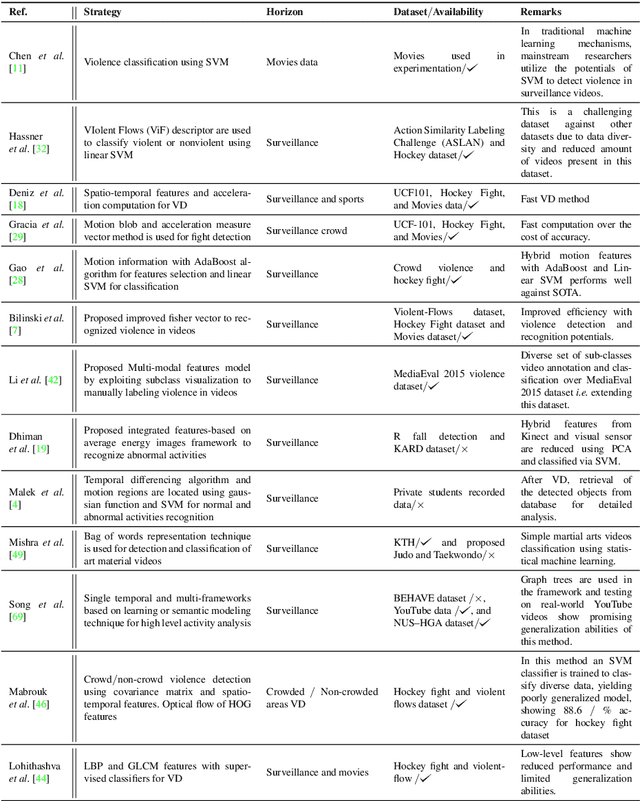

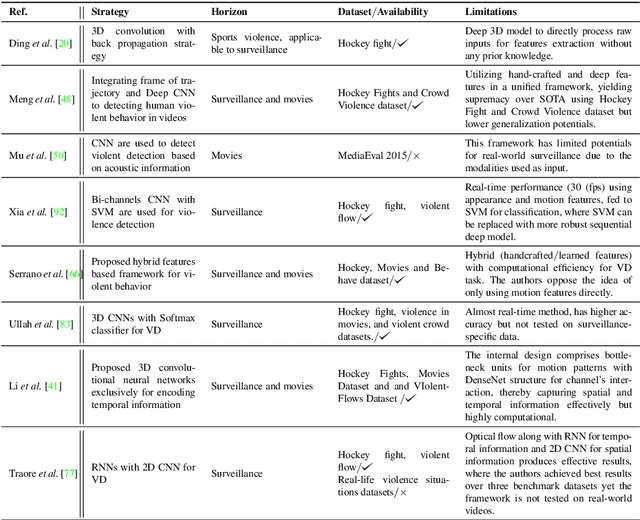
The Big Video Data generated in today's smart cities has raised concerns from its purposeful usage perspective, where surveillance cameras, among many others are the most prominent resources to contribute to the huge volumes of data, making its automated analysis a difficult task in terms of computation and preciseness. Violence Detection (VD), broadly plunging under Action and Activity recognition domain, is used to analyze Big Video data for anomalous actions incurred due to humans. The VD literature is traditionally based on manually engineered features, though advancements to deep learning based standalone models are developed for real-time VD analysis. This paper focuses on overview of deep sequence learning approaches along with localization strategies of the detected violence. This overview also dives into the initial image processing and machine learning-based VD literature and their possible advantages such as efficiency against the current complex models. Furthermore,the datasets are discussed, to provide an analysis of the current models, explaining their pros and cons with future directions in VD domain derived from an in-depth analysis of the previous methods.