 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Alignment Protocol: Making Sense of the Unlabeled Data in New Domains
May 27, 2025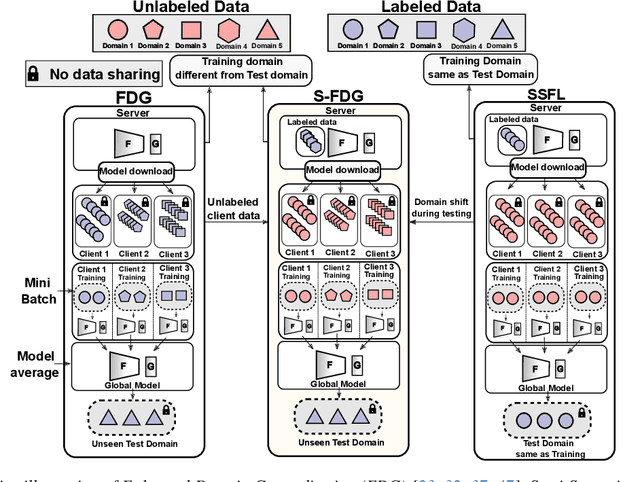

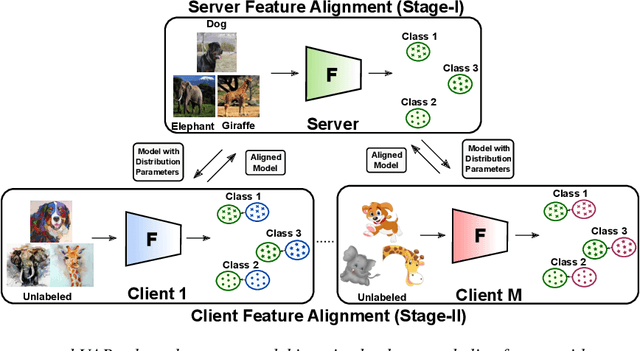
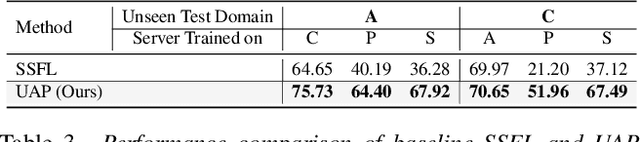
Semi-Supervised Federated Learning (SSFL) is gaining popularity over conventional Federated Learning in many real-world applications. Due to the practical limitation of limited labeled data on the client side, SSFL considers that participating clients train with unlabeled data, and only the central server has the necessary resources to access limited labeled data, making it an ideal fit for real-world applications (e.g., healthcare). However, traditional SSFL assumes that the data distributions in the training phase and testing phase are the same. In practice, however, domain shifts frequently occur, making it essential for SSFL to incorporate generalization capabilities and enhance their practicality. The core challenge is improving model generalization to new, unseen domains while the client participate in SSFL. However, the decentralized setup of SSFL and unsupervised client training necessitates innovation to achieve improved generalization across domains. To achieve this, we propose a novel framework called the Unified Alignment Protocol (UAP), which consists of an alternating two-stage training process. The first stage involves training the server model to learn and align the features with a parametric distribution, which is subsequently communicated to clients without additional communication overhead. The second stage proposes a novel training algorithm that utilizes the server feature distribution to align client features accordingly. Our extensive experiments on standard domain generalization benchmark datasets across multiple model architectures reveal that proposed UAP successfully achieves SOTA generalization performance in SSFL setting.
FinePseudo: Improving Pseudo-Labelling through Temporal-Alignablity for Semi-Supervised Fine-Grained Action Recognition
Sep 02, 2024
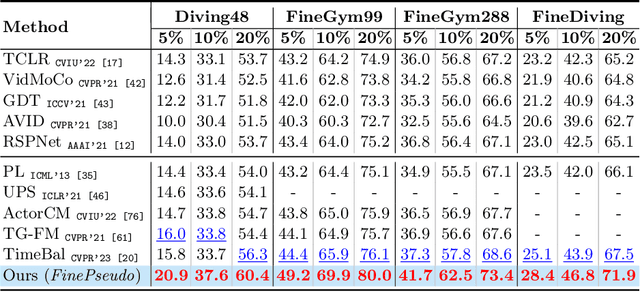
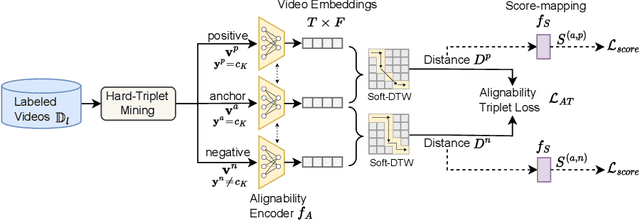

Real-life applications of action recognition often require a fine-grained understanding of subtle movements, e.g., in sports analytics, user interactions in AR/VR, and surgical videos. Although fine-grained actions are more costly to annotate, existing semi-supervised action recognition has mainly focused on coarse-grained action recognition. Since fine-grained actions are more challenging due to the absence of scene bias, classifying these actions requires an understanding of action-phases. Hence, existing coarse-grained semi-supervised methods do not work effectively. In this work, we for the first time thoroughly investigate semi-supervised fine-grained action recognition (FGAR). We observe that alignment distances like dynamic time warping (DTW) provide a suitable action-phase-aware measure for comparing fine-grained actions, a concept previously unexploited in FGAR. However, since regular DTW distance is pairwise and assumes strict alignment between pairs, it is not directly suitable for classifying fine-grained actions. To utilize such alignment distances in a limited-label setting, we propose an Alignability-Verification-based Metric learning technique to effectively discriminate between fine-grained action pairs. Our learnable alignability score provides a better phase-aware measure, which we use to refine the pseudo-labels of the primary video encoder. Our collaborative pseudo-labeling-based framework `\textit{FinePseudo}' significantly outperforms prior methods on four fine-grained action recognition datasets: Diving48, FineGym99, FineGym288, and FineDiving, and shows improvement on existing coarse-grained datasets: Kinetics400 and Something-SomethingV2. We also demonstrate the robustness of our collaborative pseudo-labeling in handling novel unlabeled classes in open-world semi-supervised setups. Project Page: https://daveishan.github.io/finepsuedo-webpage/.
GAReT: Cross-view Video Geolocalization with Adapters and Auto-Regressive Transformers
Aug 05, 2024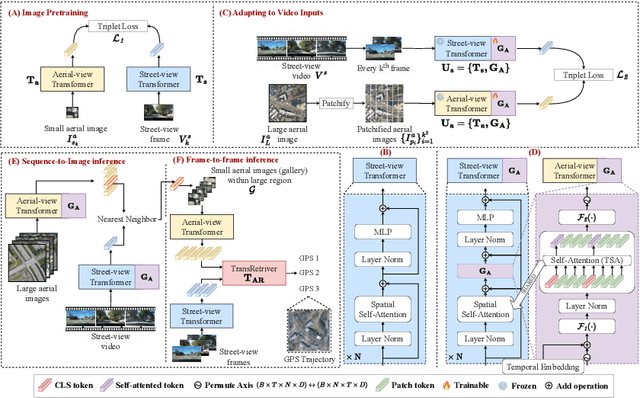
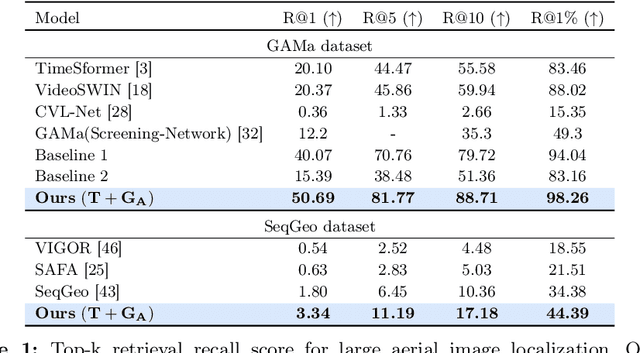
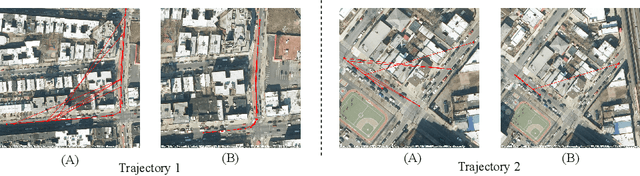
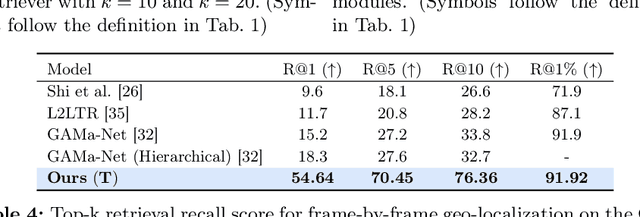
Cross-view video geo-localization (CVGL) aims to derive GPS trajectories from street-view videos by aligning them with aerial-view images. Despite their promising performance, current CVGL methods face significant challenges. These methods use camera and odometry data, typically absent in real-world scenarios. They utilize multiple adjacent frames and various encoders for feature extraction, resulting in high computational costs. Moreover, these approaches independently predict each street-view frame's location, resulting in temporally inconsistent GPS trajectories. To address these challenges, in this work, we propose GAReT, a fully transformer-based method for CVGL that does not require camera and odometry data. We introduce GeoAdapter, a transformer-adapter module designed to efficiently aggregate image-level representations and adapt them for video inputs. Specifically, we train a transformer encoder on video frames and aerial images, then freeze the encoder to optimize the GeoAdapter module to obtain video-level representation. To address temporally inconsistent trajectories, we introduce TransRetriever, an encoder-decoder transformer model that predicts GPS locations of street-view frames by encoding top-k nearest neighbor predictions per frame and auto-regressively decoding the best neighbor based on the previous frame's predictions. Our method's effectiveness is validated through extensive experiments, demonstrating state-of-the-art performance on benchmark datasets. Our code is available at https://github.com/manupillai308/GAReT.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024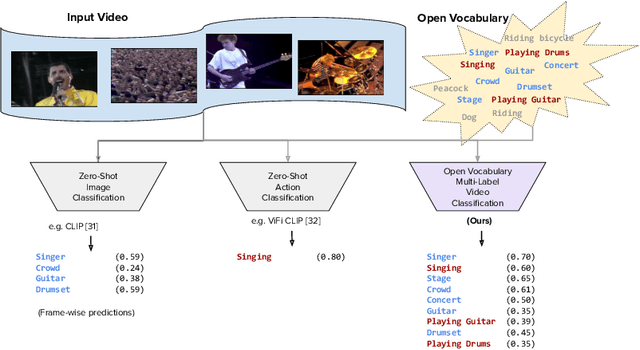
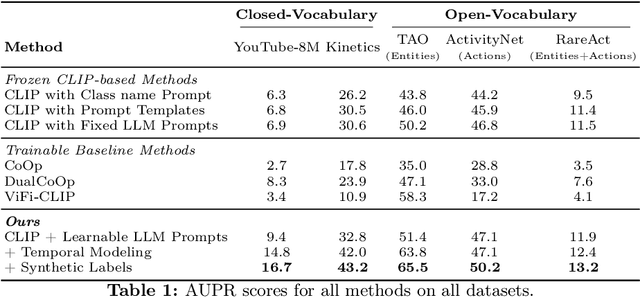
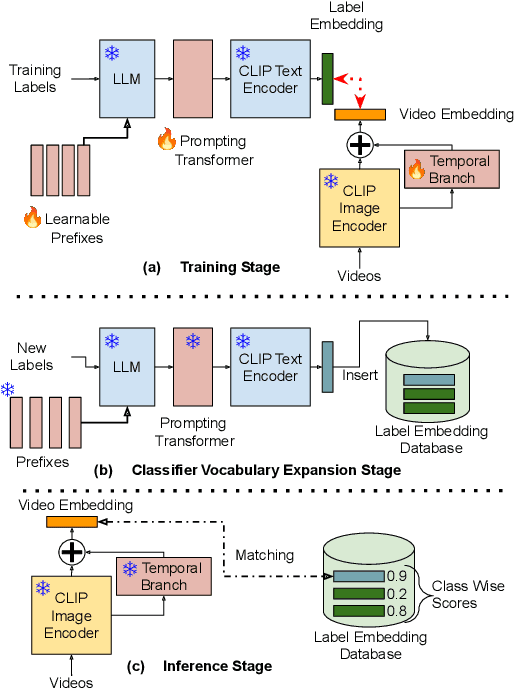
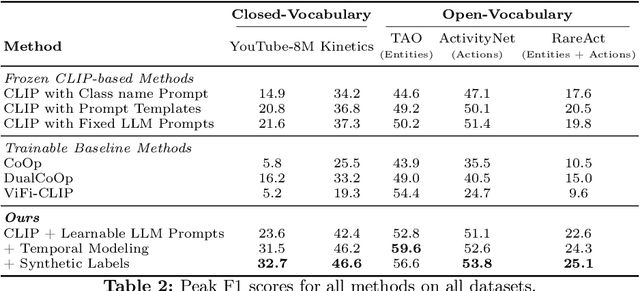
Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
Oct 12, 2023Self-supervised learning has unlocked the potential of scaling up pretraining to billions of images, since annotation is unnecessary. But are we making the best use of data? How more economical can we be? In this work, we attempt to answer this question by making two contributions. First, we investigate first-person videos and introduce a "Walking Tours" dataset. These videos are high-resolution, hours-long, captured in a single uninterrupted take, depicting a large number of objects and actions with natural scene transitions. They are unlabeled and uncurated, thus realistic for self-supervision and comparable with human learning. Second, we introduce a novel self-supervised image pretraining method tailored for learning from continuous videos. Existing methods typically adapt image-based pretraining approaches to incorporate more frames. Instead, we advocate a "tracking to learn to recognize" approach. Our method called DoRA, leads to attention maps that Discover and tRAck objects over time in an end-to-end manner, using transformer cross-attention. We derive multiple views from the tracks and use them in a classical self-supervised distillation loss. Using our novel approach, a single Walking Tours video remarkably becomes a strong competitor to ImageNet for several image and video downstream tasks.
CDFSL-V: Cross-Domain Few-Shot Learning for Videos
Sep 15, 2023



Few-shot video action recognition is an effective approach to recognizing new categories with only a few labeled examples, thereby reducing the challenges associated with collecting and annotating large-scale video datasets. Existing methods in video action recognition rely on large labeled datasets from the same domain. However, this setup is not realistic as novel categories may come from different data domains that may have different spatial and temporal characteristics. This dissimilarity between the source and target domains can pose a significant challenge, rendering traditional few-shot action recognition techniques ineffective. To address this issue, in this work, we propose a novel cross-domain few-shot video action recognition method that leverages self-supervised learning and curriculum learning to balance the information from the source and target domains. To be particular, our method employs a masked autoencoder-based self-supervised training objective to learn from both source and target data in a self-supervised manner. Then a progressive curriculum balances learning the discriminative information from the source dataset with the generic information learned from the target domain. Initially, our curriculum utilizes supervised learning to learn class discriminative features from the source data. As the training progresses, we transition to learning target-domain-specific features. We propose a progressive curriculum to encourage the emergence of rich features in the target domain based on class discriminative supervised features in the source domain. We evaluate our method on several challenging benchmark datasets and demonstrate that our approach outperforms existing cross-domain few-shot learning techniques. Our code is available at https://github.com/Sarinda251/CDFSL-V
Preserving Modality Structure Improves Multi-Modal Learning
Aug 24, 2023



Self-supervised learning on large-scale multi-modal datasets allows learning semantically meaningful embeddings in a joint multi-modal representation space without relying on human annotations. These joint embeddings enable zero-shot cross-modal tasks like retrieval and classification. However, these methods often struggle to generalize well on out-of-domain data as they ignore the semantic structure present in modality-specific embeddings. In this context, we propose a novel Semantic-Structure-Preserving Consistency approach to improve generalizability by preserving the modality-specific relationships in the joint embedding space. To capture modality-specific semantic relationships between samples, we propose to learn multiple anchors and represent the multifaceted relationship between samples with respect to their relationship with these anchors. To assign multiple anchors to each sample, we propose a novel Multi-Assignment Sinkhorn-Knopp algorithm. Our experimentation demonstrates that our proposed approach learns semantically meaningful anchors in a self-supervised manner. Furthermore, our evaluation on MSR-VTT and YouCook2 datasets demonstrates that our proposed multi-anchor assignment based solution achieves state-of-the-art performance and generalizes to both inand out-of-domain datasets. Code: https://github.com/Swetha5/Multi_Sinkhorn_Knopp
TimeBalance: Temporally-Invariant and Temporally-Distinctive Video Representations for Semi-Supervised Action Recognition
Mar 28, 2023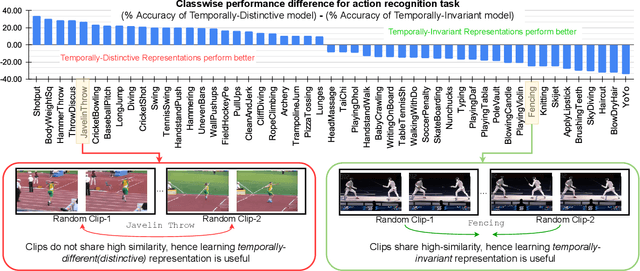
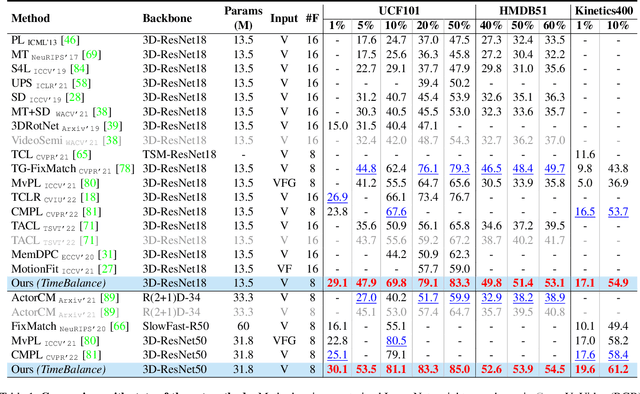
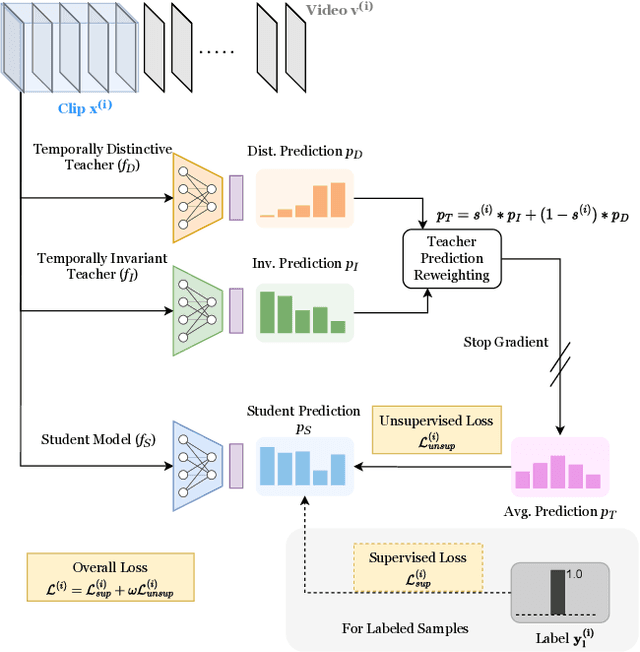

Semi-Supervised Learning can be more beneficial for the video domain compared to images because of its higher annotation cost and dimensionality. Besides, any video understanding task requires reasoning over both spatial and temporal dimensions. In order to learn both the static and motion related features for the semi-supervised action recognition task, existing methods rely on hard input inductive biases like using two-modalities (RGB and Optical-flow) or two-stream of different playback rates. Instead of utilizing unlabeled videos through diverse input streams, we rely on self-supervised video representations, particularly, we utilize temporally-invariant and temporally-distinctive representations. We observe that these representations complement each other depending on the nature of the action. Based on this observation, we propose a student-teacher semi-supervised learning framework, TimeBalance, where we distill the knowledge from a temporally-invariant and a temporally-distinctive teacher. Depending on the nature of the unlabeled video, we dynamically combine the knowledge of these two teachers based on a novel temporal similarity-based reweighting scheme. Our method achieves state-of-the-art performance on three action recognition benchmarks: UCF101, HMDB51, and Kinetics400. Code: https://github.com/DAVEISHAN/TimeBalance