 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDFSL-V: Cross-Domain Few-Shot Learning for Videos
Sep 15, 2023



Few-shot video action recognition is an effective approach to recognizing new categories with only a few labeled examples, thereby reducing the challenges associated with collecting and annotating large-scale video datasets. Existing methods in video action recognition rely on large labeled datasets from the same domain. However, this setup is not realistic as novel categories may come from different data domains that may have different spatial and temporal characteristics. This dissimilarity between the source and target domains can pose a significant challenge, rendering traditional few-shot action recognition techniques ineffective. To address this issue, in this work, we propose a novel cross-domain few-shot video action recognition method that leverages self-supervised learning and curriculum learning to balance the information from the source and target domains. To be particular, our method employs a masked autoencoder-based self-supervised training objective to learn from both source and target data in a self-supervised manner. Then a progressive curriculum balances learning the discriminative information from the source dataset with the generic information learned from the target domain. Initially, our curriculum utilizes supervised learning to learn class discriminative features from the source data. As the training progresses, we transition to learning target-domain-specific features. We propose a progressive curriculum to encourage the emergence of rich features in the target domain based on class discriminative supervised features in the source domain. We evaluate our method on several challenging benchmark datasets and demonstrate that our approach outperforms existing cross-domain few-shot learning techniques. Our code is available at https://github.com/Sarinda251/CDFSL-V
Adversarial Training for Face Recognition Systems using Contrastive Adversarial Learning and Triplet Loss Fine-tuning
Oct 09, 2021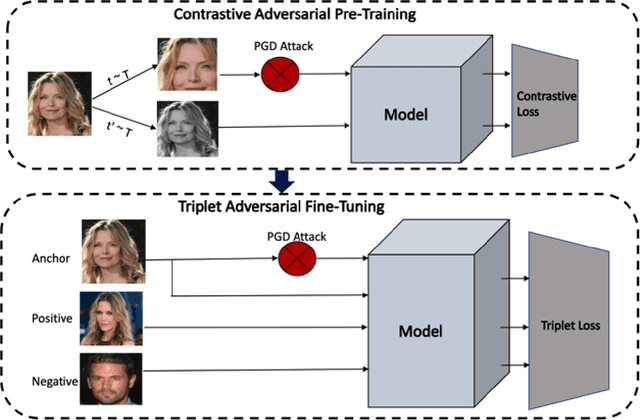

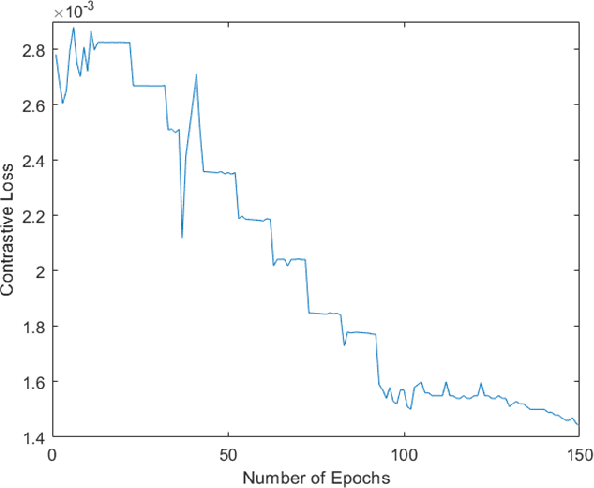

Though much work has been done in the domain of improving the adversarial robustness of facial recognition systems, a surprisingly small percentage of it has focused on self-supervised approaches. In this work, we present an approach that combines Ad-versarial Pre-Training with Triplet Loss AdversarialFine-Tuning. We compare our methods with the pre-trained ResNet50 model that forms the backbone of FaceNet, finetuned on our CelebA dataset. Through comparing adversarial robustness achieved without adversarial training, with triplet loss adversarial training, and our contrastive pre-training combined with triplet loss adversarial fine-tuning, we find that our method achieves comparable results with far fewer epochs re-quired during fine-tuning. This seems promising, increasing the training time for fine-tuning should yield even better results. In addition to this, a modified semi-supervised experiment was conducted, which demonstrated the improvement of contrastive adversarial training with the introduction of small amounts of labels.