 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativeVR: Diffusion-Prior-Guided Approach for Structure and Motion Restoration in Generative and Real Videos
Dec 12, 2025Modern text-to-video (T2V) diffusion models can synthesize visually compelling clips, yet they remain brittle at fine-scale structure: even state-of-the-art generators often produce distorted faces and hands, warped backgrounds, and temporally inconsistent motion. Such severe structural artifacts also appear in very low-quality real-world videos. Classical video restoration and super-resolution (VR/VSR) methods, in contrast, are tuned for synthetic degradations such as blur and downsampling and tend to stabilize these artifacts rather than repair them, while diffusion-prior restorers are usually trained on photometric noise and offer little control over the trade-off between perceptual quality and fidelity. We introduce CreativeVR, a diffusion-prior-guided video restoration framework for AI-generated (AIGC) and real videos with severe structural and temporal artifacts. Our deep-adapter-based method exposes a single precision knob that controls how strongly the model follows the input, smoothly trading off between precise restoration on standard degradations and stronger structure- and motion-corrective behavior on challenging content. Our key novelty is a temporally coherent degradation module used during training, which applies carefully designed transformations that produce realistic structural failures. To evaluate AIGC-artifact restoration, we propose the AIGC54 benchmark with FIQA, semantic and perceptual metrics, and multi-aspect scoring. CreativeVR achieves state-of-the-art results on videos with severe artifacts and performs competitively on standard video restoration benchmarks, while running at practical throughput (about 13 FPS at 720p on a single 80-GB A100). Project page: https://daveishan.github.io/creativevr-webpage/.
Privacy Beyond Pixels: Latent Anonymization for Privacy-Preserving Video Understanding
Nov 11, 2025We introduce a novel formulation of visual privacy preservation for video foundation models that operates entirely in the latent space. While spatio-temporal features learned by foundation models have deepened general understanding of video content, sharing or storing these extracted visual features for downstream tasks inadvertently reveals sensitive personal information like skin color, gender, or clothing. Current privacy preservation methods focus on input-pixel-level anonymization, which requires retraining the entire utility video model and results in task-specific anonymization, making them unsuitable for recent video foundational models. To address these challenges, we introduce a lightweight Anonymizing Adapter Module (AAM) that removes private information from video features while retaining general task utility. AAM can be applied in a plug-and-play fashion to frozen video encoders, minimizing the computational burden of finetuning and re-extracting features. Our framework employs three newly designed training objectives: (1) a clip-level self-supervised privacy objective to reduce mutual information between static clips, (2) a co-training objective to retain utility across seen tasks, and (3) a latent consistency loss for generalization on unseen tasks. Our extensive evaluations demonstrate a significant 35% reduction in privacy leakage while maintaining near-baseline utility performance across various downstream tasks: Action Recognition (Kinetics400, UCF101, HMDB51), Temporal Action Detection (THUMOS14), and Anomaly Detection (UCF-Crime). We also provide an analysis on anonymization for sensitive temporal attribute recognition. Additionally, we propose new protocols for assessing gender bias in action recognition models, showing that our method effectively mitigates such biases and promotes more equitable video understanding.
From Play to Replay: Composed Video Retrieval for Temporally Fine-Grained Videos
Jun 05, 2025
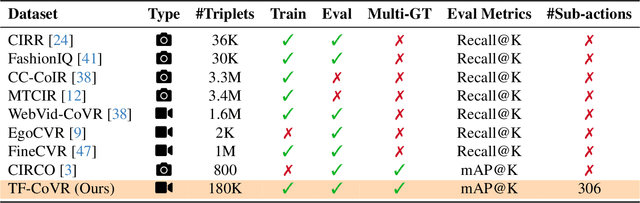
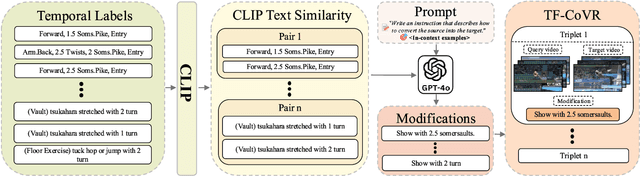
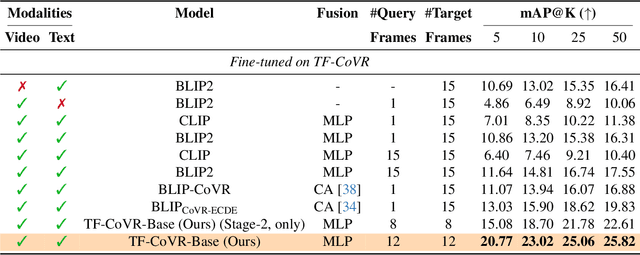
Composed Video Retrieval (CoVR) retrieves a target video given a query video and a modification text describing the intended change. Existing CoVR benchmarks emphasize appearance shifts or coarse event changes and therefore do not test the ability to capture subtle, fast-paced temporal differences. We introduce TF-CoVR, the first large-scale benchmark dedicated to temporally fine-grained CoVR. TF-CoVR focuses on gymnastics and diving and provides 180K triplets drawn from FineGym and FineDiving. Previous CoVR benchmarks focusing on temporal aspect, link each query to a single target segment taken from the same video, limiting practical usefulness. In TF-CoVR, we instead construct each <query, modification> pair by prompting an LLM with the label differences between clips drawn from different videos; every pair is thus associated with multiple valid target videos (3.9 on average), reflecting real-world tasks such as sports-highlight generation. To model these temporal dynamics we propose TF-CoVR-Base, a concise two-stage training framework: (i) pre-train a video encoder on fine-grained action classification to obtain temporally discriminative embeddings; (ii) align the composed query with candidate videos using contrastive learning. We conduct the first comprehensive study of image, video, and general multimodal embedding (GME) models on temporally fine-grained composed retrieval in both zero-shot and fine-tuning regimes. On TF-CoVR, TF-CoVR-Base improves zero-shot mAP@50 from 5.92 (LanguageBind) to 7.51, and after fine-tuning raises the state-of-the-art from 19.83 to 25.82.
FinePseudo: Improving Pseudo-Labelling through Temporal-Alignablity for Semi-Supervised Fine-Grained Action Recognition
Sep 02, 2024
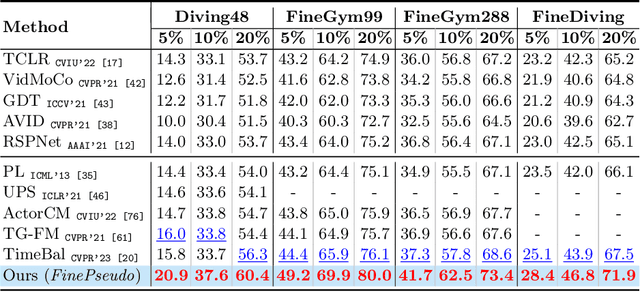
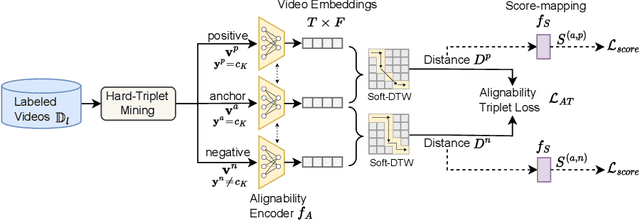

Real-life applications of action recognition often require a fine-grained understanding of subtle movements, e.g., in sports analytics, user interactions in AR/VR, and surgical videos. Although fine-grained actions are more costly to annotate, existing semi-supervised action recognition has mainly focused on coarse-grained action recognition. Since fine-grained actions are more challenging due to the absence of scene bias, classifying these actions requires an understanding of action-phases. Hence, existing coarse-grained semi-supervised methods do not work effectively. In this work, we for the first time thoroughly investigate semi-supervised fine-grained action recognition (FGAR). We observe that alignment distances like dynamic time warping (DTW) provide a suitable action-phase-aware measure for comparing fine-grained actions, a concept previously unexploited in FGAR. However, since regular DTW distance is pairwise and assumes strict alignment between pairs, it is not directly suitable for classifying fine-grained actions. To utilize such alignment distances in a limited-label setting, we propose an Alignability-Verification-based Metric learning technique to effectively discriminate between fine-grained action pairs. Our learnable alignability score provides a better phase-aware measure, which we use to refine the pseudo-labels of the primary video encoder. Our collaborative pseudo-labeling-based framework `\textit{FinePseudo}' significantly outperforms prior methods on four fine-grained action recognition datasets: Diving48, FineGym99, FineGym288, and FineDiving, and shows improvement on existing coarse-grained datasets: Kinetics400 and Something-SomethingV2. We also demonstrate the robustness of our collaborative pseudo-labeling in handling novel unlabeled classes in open-world semi-supervised setups. Project Page: https://daveishan.github.io/finepsuedo-webpage/.
Sync from the Sea: Retrieving Alignable Videos from Large-Scale Datasets
Sep 02, 2024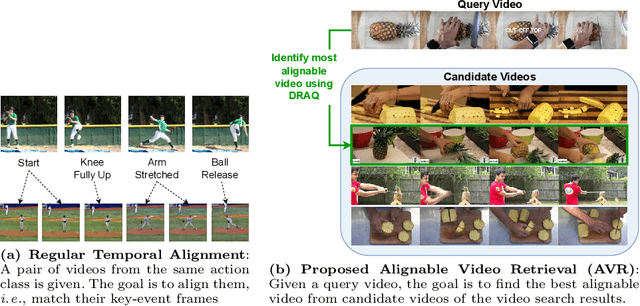

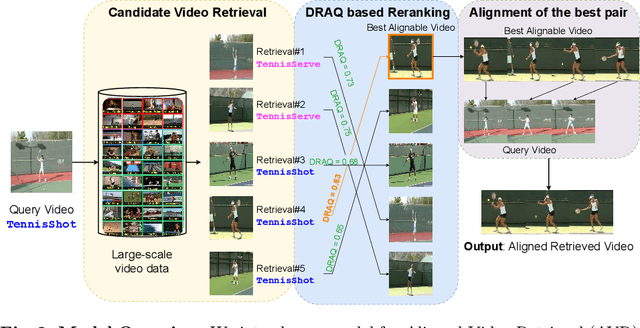

Temporal video alignment aims to synchronize the key events like object interactions or action phase transitions in two videos. Such methods could benefit various video editing, processing, and understanding tasks. However, existing approaches operate under the restrictive assumption that a suitable video pair for alignment is given, significantly limiting their broader applicability. To address this, we re-pose temporal alignment as a search problem and introduce the task of Alignable Video Retrieval (AVR). Given a query video, our approach can identify well-alignable videos from a large collection of clips and temporally synchronize them to the query. To achieve this, we make three key contributions: 1) we introduce DRAQ, a video alignability indicator to identify and re-rank the best alignable video from a set of candidates; 2) we propose an effective and generalizable frame-level video feature design to improve the alignment performance of several off-the-shelf feature representations, and 3) we propose a novel benchmark and evaluation protocol for AVR using cycle-consistency metrics. Our experiments on 3 datasets, including large-scale Kinetics700, demonstrate the effectiveness of our approach in identifying alignable video pairs from diverse datasets. Project Page: https://daveishan.github.io/avr-webpage/.
CodaMal: Contrastive Domain Adaptation for Malaria Detection in Low-Cost Microscopes
Feb 16, 2024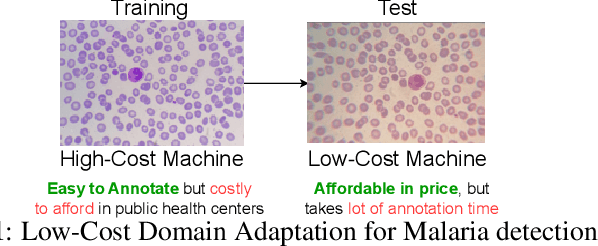
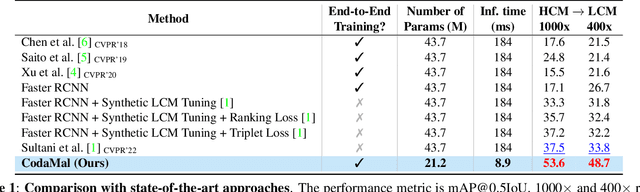
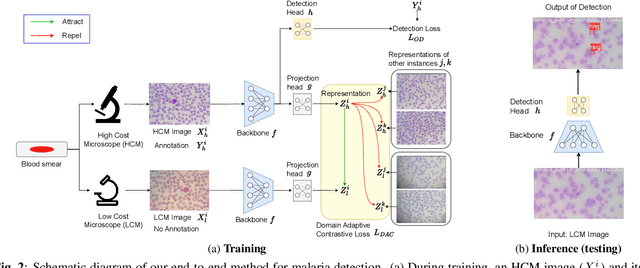

Malaria is a major health issue worldwide, and its diagnosis requires scalable solutions that can work effectively with low-cost microscopes (LCM). Deep learning-based methods have shown success in computer-aided diagnosis from microscopic images. However, these methods need annotated images that show cells affected by malaria parasites and their life stages. Annotating images from LCM significantly increases the burden on medical experts compared to annotating images from high-cost microscopes (HCM). For this reason, a practical solution would be trained on HCM images which should generalize well on LCM images during testing. While earlier methods adopted a multi-stage learning process, they did not offer an end-to-end approach. In this work, we present an end-to-end learning framework, named CodaMal (Contrastive Domain Adpation for Malaria). In order to bridge the gap between HCM (training) and LCM (testing), we propose a domain adaptive contrastive loss. It reduces the domain shift by promoting similarity between the representations of HCM and its corresponding LCM image, without imposing an additional annotation burden. In addition, the training objective includes object detection objectives with carefully designed augmentations, ensuring the accurate detection of malaria parasites. On the publicly available large-scale M5-dataset, our proposed method shows a significant improvement of 16% over the state-of-the-art methods in terms of the mean average precision metric (mAP), provides 21x speed up during inference, and requires only half learnable parameters than the prior methods. Our code is publicly available.
No More Shortcuts: Realizing the Potential of Temporal Self-Supervision
Dec 20, 2023Self-supervised approaches for video have shown impressive results in video understanding tasks. However, unlike early works that leverage temporal self-supervision, current state-of-the-art methods primarily rely on tasks from the image domain (e.g., contrastive learning) that do not explicitly promote the learning of temporal features. We identify two factors that limit existing temporal self-supervision: 1) tasks are too simple, resulting in saturated training performance, and 2) we uncover shortcuts based on local appearance statistics that hinder the learning of high-level features. To address these issues, we propose 1) a more challenging reformulation of temporal self-supervision as frame-level (rather than clip-level) recognition tasks and 2) an effective augmentation strategy to mitigate shortcuts. Our model extends a representation of single video frames, pre-trained through contrastive learning, with a transformer that we train through temporal self-supervision. We demonstrate experimentally that our more challenging frame-level task formulations and the removal of shortcuts drastically improve the quality of features learned through temporal self-supervision. The generalization capability of our self-supervised video method is evidenced by its state-of-the-art performance in a wide range of high-level semantic tasks, including video retrieval, action classification, and video attribute recognition (such as object and scene identification), as well as low-level temporal correspondence tasks like video object segmentation and pose tracking. Additionally, we show that the video representations learned through our method exhibit increased robustness to the input perturbations.
EventTransAct: A video transformer-based framework for Event-camera based action recognition
Aug 25, 2023
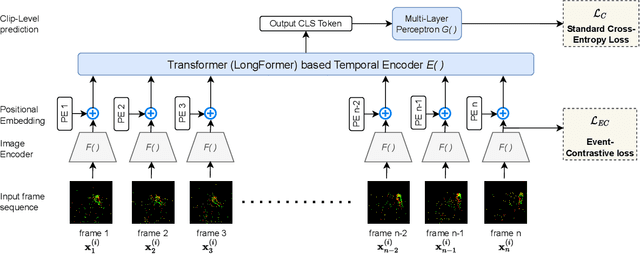
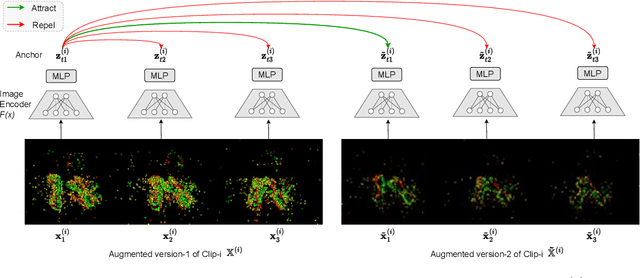
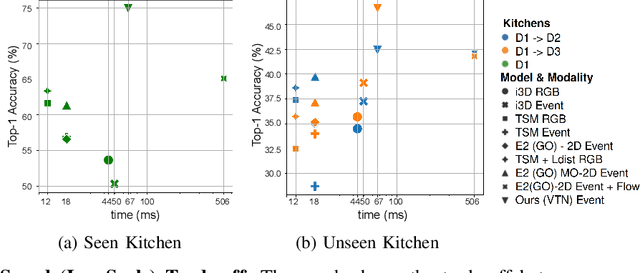
Recognizing and comprehending human actions and gestures is a crucial perception requirement for robots to interact with humans and carry out tasks in diverse domains, including service robotics, healthcare, and manufacturing. Event cameras, with their ability to capture fast-moving objects at a high temporal resolution, offer new opportunities compared to standard action recognition in RGB videos. However, previous research on event camera action recognition has primarily focused on sensor-specific network architectures and image encoding, which may not be suitable for new sensors and limit the use of recent advancements in transformer-based architectures. In this study, we employ a computationally efficient model, namely the video transformer network (VTN), which initially acquires spatial embeddings per event-frame and then utilizes a temporal self-attention mechanism. In order to better adopt the VTN for the sparse and fine-grained nature of event data, we design Event-Contrastive Loss ($\mathcal{L}_{EC}$) and event-specific augmentations. Proposed $\mathcal{L}_{EC}$ promotes learning fine-grained spatial cues in the spatial backbone of VTN by contrasting temporally misaligned frames. We evaluate our method on real-world action recognition of N-EPIC Kitchens dataset, and achieve state-of-the-art results on both protocols - testing in seen kitchen (\textbf{74.9\%} accuracy) and testing in unseen kitchens (\textbf{42.43\% and 46.66\% Accuracy}). Our approach also takes less computation time compared to competitive prior approaches, which demonstrates the potential of our framework \textit{EventTransAct} for real-world applications of event-camera based action recognition. Project Page: \url{https://tristandb8.github.io/EventTransAct_webpage/}
TeD-SPAD: Temporal Distinctiveness for Self-supervised Privacy-preservation for video Anomaly Detection
Aug 21, 2023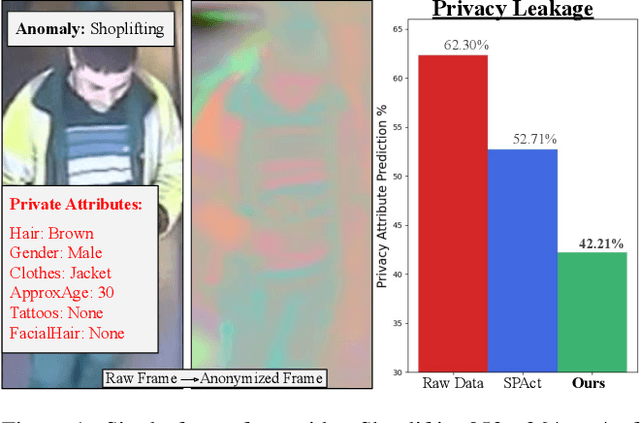

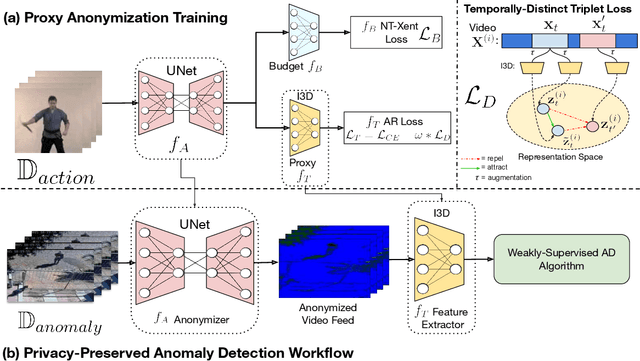

Video anomaly detection (VAD) without human monitoring is a complex computer vision task that can have a positive impact on society if implemented successfully. While recent advances have made significant progress in solving this task, most existing approaches overlook a critical real-world concern: privacy. With the increasing popularity of artificial intelligence technologies, it becomes crucial to implement proper AI ethics into their development. Privacy leakage in VAD allows models to pick up and amplify unnecessary biases related to people's personal information, which may lead to undesirable decision making. In this paper, we propose TeD-SPAD, a privacy-aware video anomaly detection framework that destroys visual private information in a self-supervised manner. In particular, we propose the use of a temporally-distinct triplet loss to promote temporally discriminative features, which complements current weakly-supervised VAD methods. Using TeD-SPAD, we achieve a positive trade-off between privacy protection and utility anomaly detection performance on three popular weakly supervised VAD datasets: UCF-Crime, XD-Violence, and ShanghaiTech. Our proposed anonymization model reduces private attribute prediction by 32.25% while only reducing frame-level ROC AUC on the UCF-Crime anomaly detection dataset by 3.69%. Project Page: https://joefioresi718.github.io/TeD-SPAD_webpage/
TimeBalance: Temporally-Invariant and Temporally-Distinctive Video Representations for Semi-Supervised Action Recognition
Mar 28, 2023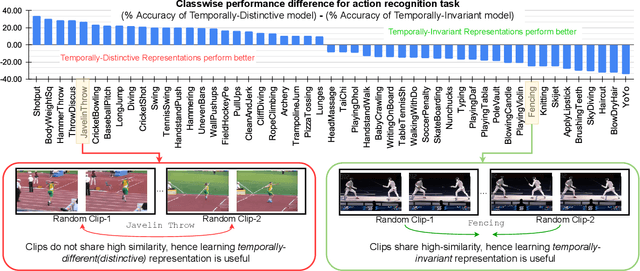
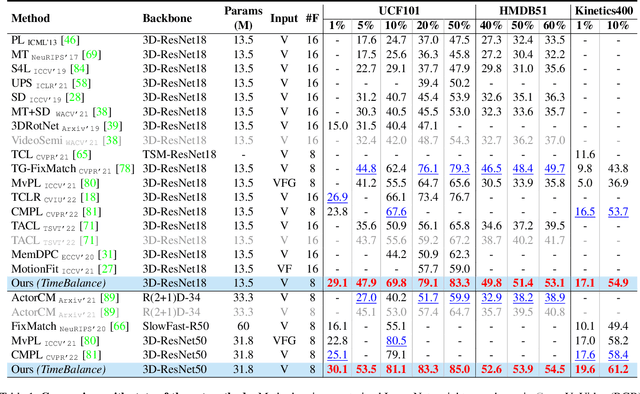
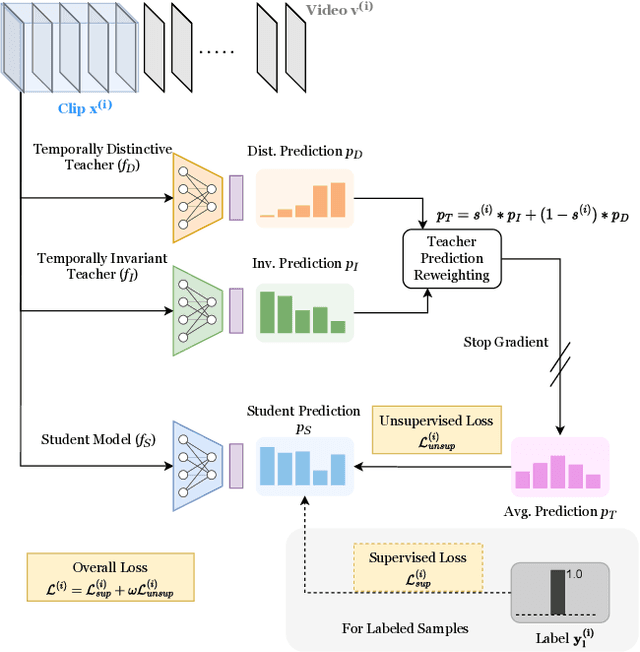

Semi-Supervised Learning can be more beneficial for the video domain compared to images because of its higher annotation cost and dimensionality. Besides, any video understanding task requires reasoning over both spatial and temporal dimensions. In order to learn both the static and motion related features for the semi-supervised action recognition task, existing methods rely on hard input inductive biases like using two-modalities (RGB and Optical-flow) or two-stream of different playback rates. Instead of utilizing unlabeled videos through diverse input streams, we rely on self-supervised video representations, particularly, we utilize temporally-invariant and temporally-distinctive representations. We observe that these representations complement each other depending on the nature of the action. Based on this observation, we propose a student-teacher semi-supervised learning framework, TimeBalance, where we distill the knowledge from a temporally-invariant and a temporally-distinctive teacher. Depending on the nature of the unlabeled video, we dynamically combine the knowledge of these two teachers based on a novel temporal similarity-based reweighting scheme. Our method achieves state-of-the-art performance on three action recognition benchmarks: UCF101, HMDB51, and Kinetics400. Code: https://github.com/DAVEISHAN/TimeBalance