 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoprompter: an ensemble of foundational models for zero-shot video understanding
Oct 23, 2023



Vision-language models (VLMs) classify the query video by calculating a similarity score between the visual features and text-based class label representations. Recently, large language models (LLMs) have been used to enrich the text-based class labels by enhancing the descriptiveness of the class names. However, these improvements are restricted to the text-based classifier only, and the query visual features are not considered. In this paper, we propose a framework which combines pre-trained discriminative VLMs with pre-trained generative video-to-text and text-to-text models. We introduce two key modifications to the standard zero-shot setting. First, we propose language-guided visual feature enhancement and employ a video-to-text model to convert the query video to its descriptive form. The resulting descriptions contain vital visual cues of the query video, such as what objects are present and their spatio-temporal interactions. These descriptive cues provide additional semantic knowledge to VLMs to enhance their zeroshot performance. Second, we propose video-specific prompts to LLMs to generate more meaningful descriptions to enrich class label representations. Specifically, we introduce prompt techniques to create a Tree Hierarchy of Categories for class names, offering a higher-level action context for additional visual cues, We demonstrate the effectiveness of our approach in video understanding across three different zero-shot settings: 1) video action recognition, 2) video-to-text and textto-video retrieval, and 3) time-sensitive video tasks. Consistent improvements across multiple benchmarks and with various VLMs demonstrate the effectiveness of our proposed framework. Our code will be made publicly available.
EventTransAct: A video transformer-based framework for Event-camera based action recognition
Aug 25, 2023
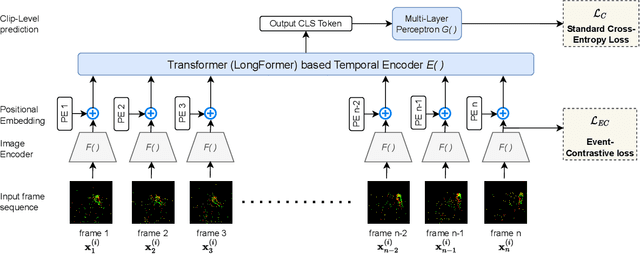
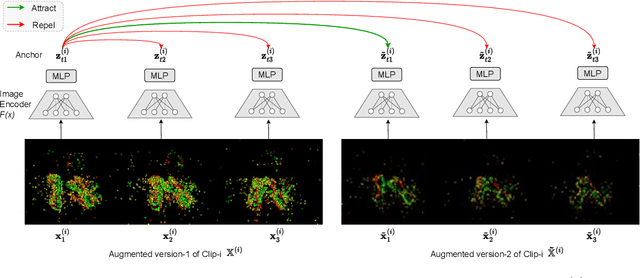
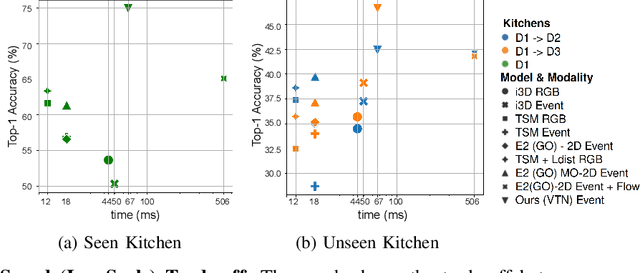
Recognizing and comprehending human actions and gestures is a crucial perception requirement for robots to interact with humans and carry out tasks in diverse domains, including service robotics, healthcare, and manufacturing. Event cameras, with their ability to capture fast-moving objects at a high temporal resolution, offer new opportunities compared to standard action recognition in RGB videos. However, previous research on event camera action recognition has primarily focused on sensor-specific network architectures and image encoding, which may not be suitable for new sensors and limit the use of recent advancements in transformer-based architectures. In this study, we employ a computationally efficient model, namely the video transformer network (VTN), which initially acquires spatial embeddings per event-frame and then utilizes a temporal self-attention mechanism. In order to better adopt the VTN for the sparse and fine-grained nature of event data, we design Event-Contrastive Loss ($\mathcal{L}_{EC}$) and event-specific augmentations. Proposed $\mathcal{L}_{EC}$ promotes learning fine-grained spatial cues in the spatial backbone of VTN by contrasting temporally misaligned frames. We evaluate our method on real-world action recognition of N-EPIC Kitchens dataset, and achieve state-of-the-art results on both protocols - testing in seen kitchen (\textbf{74.9\%} accuracy) and testing in unseen kitchens (\textbf{42.43\% and 46.66\% Accuracy}). Our approach also takes less computation time compared to competitive prior approaches, which demonstrates the potential of our framework \textit{EventTransAct} for real-world applications of event-camera based action recognition. Project Page: \url{https://tristandb8.github.io/EventTransAct_webpage/}