 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Box and Block Test with Computer Vision for Post-Stroke Upper Extremity Motor Evaluation
Mar 31, 2026Standard clinical assessments of upper-extremity motor function after stroke either rely on ordinal scoring, which lacks sensitivity, or time-based task metrics, which do not capture movement quality. In this work, we present a computer vision-based framework for analysis of upper-extremity movement during the Box and Block Test (BBT) through world-aligned joint angles of fingers, arm, and trunk without depth sensors or calibration objects. We apply this framework to a dataset of 136 BBT recordings collected from 48 healthy individuals and 7 individuals post stroke. Using unsupervised dimensionality reduction of joint-angle features, we analyze movement patterns without relying on expert clinical labels. The resulting embeddings show separation between healthy movement patterns and stroke-related movement deviations. Importantly, some patients with the same BBT scores can be separated with different postural patterns. These results show that world-aligned joint angles can capture meaningful information of upper-extremity functions beyond standard time-based BBT scores, with no effort from the clinician other than monocular video recordings of the patient using a phone or camera. This work highlights the potential of a camera-based, calibration-free framework to measure movement quality in clinical assessments without changing the widely adopted clinical routine.
Seeing to Ground: Visual Attention for Hallucination-Resilient MDLLMs
Mar 26, 2026Multimodal Diffusion Large Language Models (MDLLMs) achieve high-concurrency generation through parallel masked decoding, yet the architectures remain prone to multimodal hallucinations. This structural vulnerability stems from an algorithmic flaw: the decoder ranks candidate tokens based on textual likelihood without verifying localized visual support. We establish that this language-only ranking induces an objective mismatch, where language probability mass acts as a misspecified proxy for the intended multimodal task. Consequently, we reinterpret hallucination as a localized optimization error, a phenomenon where the decoder exploits language shortcuts to maximize a proxy score at the expense of visual grounding. To address this objective mismatch, we introduce VISAGE, a training-free decoding framework that calibrates the objective at inference time. VISAGE estimates the proxy discrepancy by quantifying the spatial entropy of cross-attention distributions. By enforcing a localization consensus across attention heads, the method penalizes spatially uniform distributions and re-ranks token commitments to favor visually grounded outcomes. We provide an analytical stability guarantee establishing that VISAGE maintains a bounded objective loss under estimation error. Evaluations across hallucination-sensitive and general-purpose benchmarks demonstrate the robustness of the framework, yielding relative gains of 8.59% on MMMU-val and 7.75% on HallusionBench.
From Play to Replay: Composed Video Retrieval for Temporally Fine-Grained Videos
Jun 05, 2025
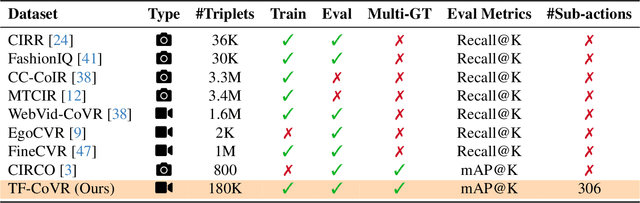
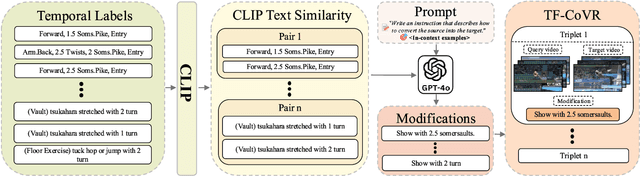
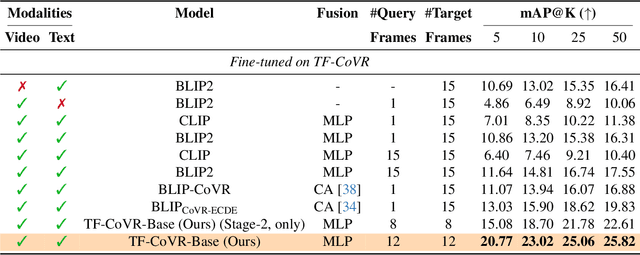
Composed Video Retrieval (CoVR) retrieves a target video given a query video and a modification text describing the intended change. Existing CoVR benchmarks emphasize appearance shifts or coarse event changes and therefore do not test the ability to capture subtle, fast-paced temporal differences. We introduce TF-CoVR, the first large-scale benchmark dedicated to temporally fine-grained CoVR. TF-CoVR focuses on gymnastics and diving and provides 180K triplets drawn from FineGym and FineDiving. Previous CoVR benchmarks focusing on temporal aspect, link each query to a single target segment taken from the same video, limiting practical usefulness. In TF-CoVR, we instead construct each <query, modification> pair by prompting an LLM with the label differences between clips drawn from different videos; every pair is thus associated with multiple valid target videos (3.9 on average), reflecting real-world tasks such as sports-highlight generation. To model these temporal dynamics we propose TF-CoVR-Base, a concise two-stage training framework: (i) pre-train a video encoder on fine-grained action classification to obtain temporally discriminative embeddings; (ii) align the composed query with candidate videos using contrastive learning. We conduct the first comprehensive study of image, video, and general multimodal embedding (GME) models on temporally fine-grained composed retrieval in both zero-shot and fine-tuning regimes. On TF-CoVR, TF-CoVR-Base improves zero-shot mAP@50 from 5.92 (LanguageBind) to 7.51, and after fine-tuning raises the state-of-the-art from 19.83 to 25.82.
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023



Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
Adaptive Fine-Grained Sketch-Based Image Retrieval
Jul 06, 2022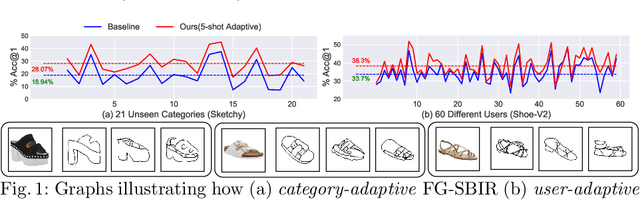
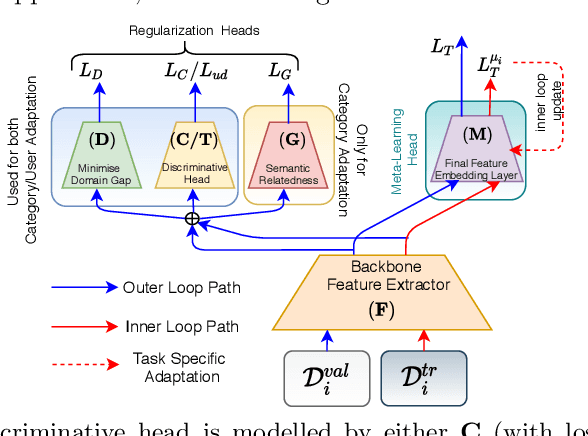
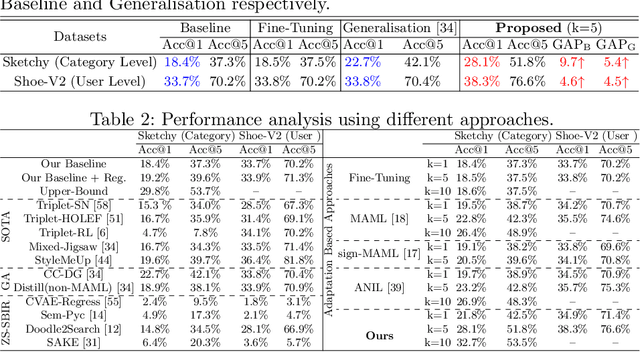
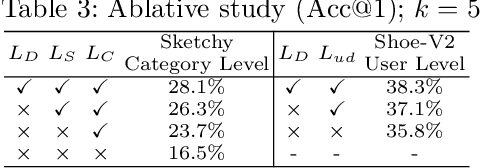
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted towards generalising a model to new categories without any training data from them. In real-world applications, however, a trained FG-SBIR model is often applied to both new categories and different human sketchers, i.e., different drawing styles. Although this complicates the generalisation problem, fortunately, a handful of examples are typically available, enabling the model to adapt to the new category/style. In this paper, we offer a novel perspective -- instead of asking for a model that generalises, we advocate for one that quickly adapts, with just very few samples during testing (in a few-shot manner). To solve this new problem, we introduce a novel model-agnostic meta-learning (MAML) based framework with several key modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the MAML training in the inner loop to make it more stable and tractable. (2) The margin in our contrastive loss is also meta-learned with the rest of the model. (3) Three additional regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR model more effective for category/style adaptation. Extensive experiments on public datasets suggest a large gain over generalisation and zero-shot based approaches, and a few strong few-shot baselines.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021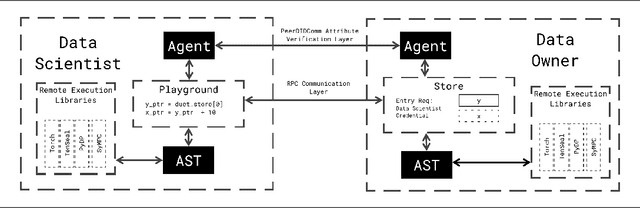
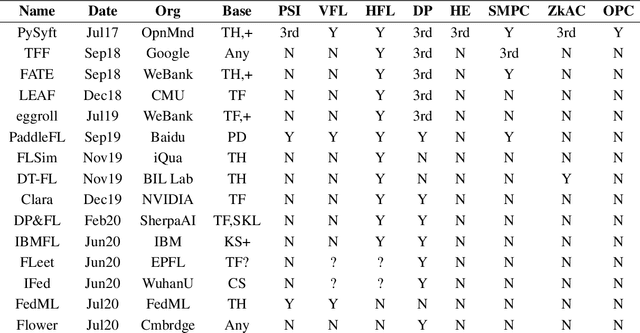
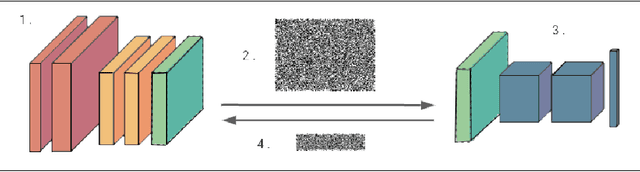
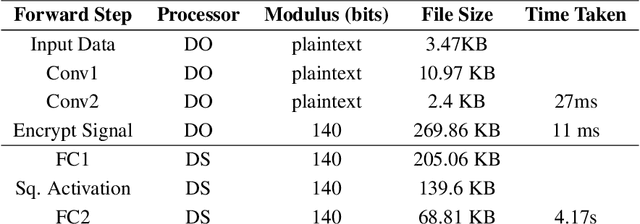
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
[RE] Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Apr 14, 2021![Figure 1 for [RE] Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9adfa9306a3beef2d978220ac01b43ace0bf4206%2F3-Table1-1.png&w=640&q=75)
![Figure 2 for [RE] Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9adfa9306a3beef2d978220ac01b43ace0bf4206%2F5-Figure1-1.png&w=640&q=75)
![Figure 3 for [RE] Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9adfa9306a3beef2d978220ac01b43ace0bf4206%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for [RE] Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F9adfa9306a3beef2d978220ac01b43ace0bf4206%2F5-Table3-1.png&w=640&q=75)
Despite widespread use in natural language processing (NLP) tasks, word embeddings have been criticized for inheriting unintended gender bias from training corpora. programmer is more closely associated with man and homemaker is more closely associated with woman. Such gender bias has also been shown to propagate in downstream tasks.