 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAAMSE: Framework for Evolutionary Security Evaluation of Agents
Feb 07, 2026AI agents are increasingly deployed in production, yet their security evaluations remain bottlenecked by manual red-teaming or static benchmarks that fail to model adaptive, multi-turn adversaries. We propose NAAMSE, an evolutionary framework that reframes agent security evaluation as a feedback-driven optimization problem. Our system employs a single autonomous agent that orchestrates a lifecycle of genetic prompt mutation, hierarchical corpus exploration, and asymmetric behavioral scoring. By using model responses as a fitness signal, the framework iteratively compounds effective attack strategies while simultaneously ensuring "benign-use correctness", preventing the degenerate security of blanket refusal. Our experiments on Gemini 2.5 Flash demonstrate that evolutionary mutation systematically amplifies vulnerabilities missed by one-shot methods, with controlled ablations revealing that the synergy between exploration and targeted mutation uncovers high-severity failure modes. We show that this adaptive approach provides a more realistic and scalable assessment of agent robustness in the face of evolving threats. The code for NAAMSE is open source and available at https://github.com/HASHIRU-AI/NAAMSE.
How Many Instructions Can LLMs Follow at Once?
Jul 15, 2025Production-grade LLM systems require robust adherence to dozens or even hundreds of instructions simultaneously. However, the instruction-following capabilities of LLMs at high instruction densities have not yet been characterized, as existing benchmarks only evaluate models on tasks with a single or few instructions. We introduce IFScale, a simple benchmark of 500 keyword-inclusion instructions for a business report writing task to measure how instruction-following performance degrades as instruction density increases. We evaluate 20 state-of-the-art models across seven major providers and find that even the best frontier models only achieve 68% accuracy at the max density of 500 instructions. Our analysis reveals model size and reasoning capability to correlate with 3 distinct performance degradation patterns, bias towards earlier instructions, and distinct categories of instruction-following errors. Our insights can help inform design of instruction-dense prompts in real-world applications and highlight important performance-latency tradeoffs. We open-source the benchmark and all results for further analysis at https://distylai.github.io/IFScale.
On Adversarial Robustness and Out-of-Distribution Robustness of Large Language Models
Dec 13, 2024The increasing reliance on large language models (LLMs) for diverse applications necessitates a thorough understanding of their robustness to adversarial perturbations and out-of-distribution (OOD) inputs. In this study, we investigate the correlation between adversarial robustness and OOD robustness in LLMs, addressing a critical gap in robustness evaluation. By applying methods originally designed to improve one robustness type across both contexts, we analyze their performance on adversarial and out-of-distribution benchmark datasets. The input of the model consists of text samples, with the output prediction evaluated in terms of accuracy, precision, recall, and F1 scores in various natural language inference tasks. Our findings highlight nuanced interactions between adversarial robustness and OOD robustness, with results indicating limited transferability between the two robustness types. Through targeted ablations, we evaluate how these correlations evolve with different model sizes and architectures, uncovering model-specific trends: smaller models like LLaMA2-7b exhibit neutral correlations, larger models like LLaMA2-13b show negative correlations, and Mixtral demonstrates positive correlations, potentially due to domain-specific alignment. These results underscore the importance of hybrid robustness frameworks that integrate adversarial and OOD strategies tailored to specific models and domains. Further research is needed to evaluate these interactions across larger models and varied architectures, offering a pathway to more reliable and generalizable LLMs.
Adaptive Fine-Grained Sketch-Based Image Retrieval
Jul 06, 2022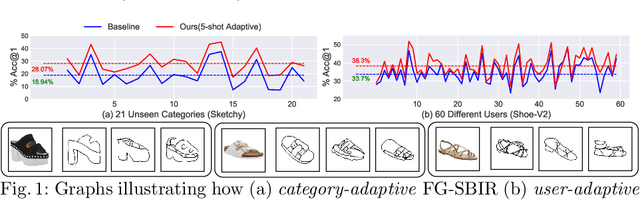
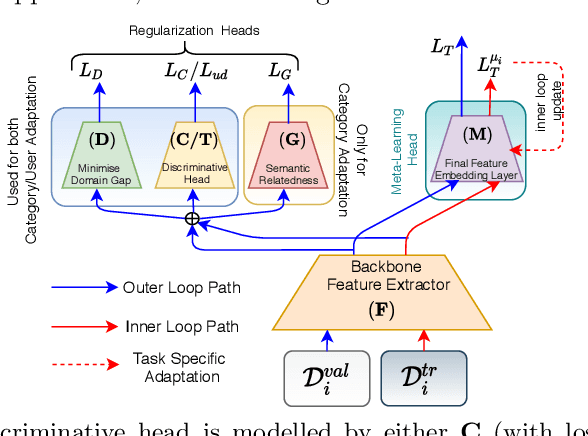
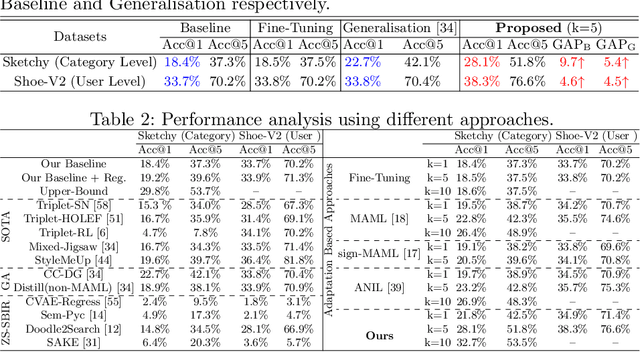
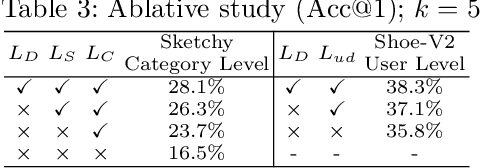
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted towards generalising a model to new categories without any training data from them. In real-world applications, however, a trained FG-SBIR model is often applied to both new categories and different human sketchers, i.e., different drawing styles. Although this complicates the generalisation problem, fortunately, a handful of examples are typically available, enabling the model to adapt to the new category/style. In this paper, we offer a novel perspective -- instead of asking for a model that generalises, we advocate for one that quickly adapts, with just very few samples during testing (in a few-shot manner). To solve this new problem, we introduce a novel model-agnostic meta-learning (MAML) based framework with several key modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the MAML training in the inner loop to make it more stable and tractable. (2) The margin in our contrastive loss is also meta-learned with the rest of the model. (3) Three additional regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR model more effective for category/style adaptation. Extensive experiments on public datasets suggest a large gain over generalisation and zero-shot based approaches, and a few strong few-shot baselines.
Knowledge Base Inference for Regular Expression Queries
May 01, 2020

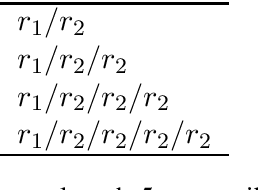

Two common types of tasks on Knowledge Bases have been studied -- single link prediction (Knowledge Base Completion) and path query answering. However, our analysis of user queries on a real-world knowledge base reveals that a significant fraction of queries specify paths using regular expressions(regex). Such regex queries cannot be handled by any of the existing link prediction or path query answering models. In response, we present Regex Query Answering, the novel task of answering regex queries on incomplete KBs. We contribute two datasets for the task, including one where test queries are harvested from actual user querylogs. We train baseline neural models for our new task and propose novel ways to handle disjunction and Kleene plus regex operators.
Neural Machine Translation System of Indic Languages -- An Attention based Approach
Feb 02, 2020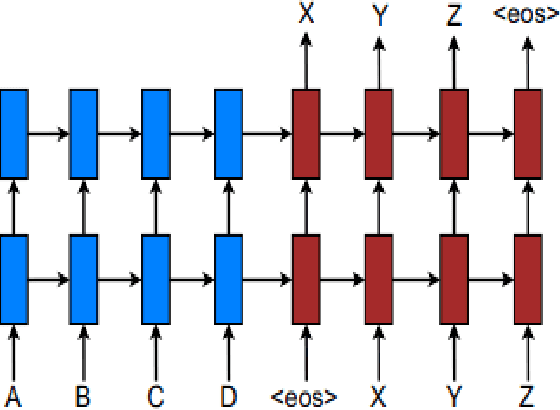
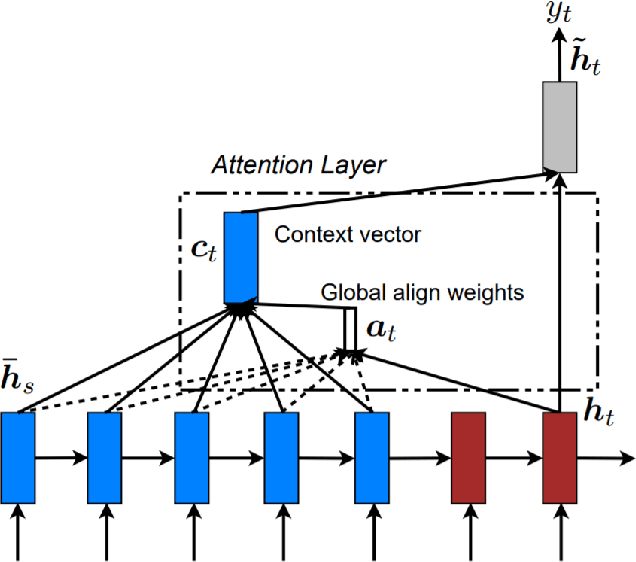
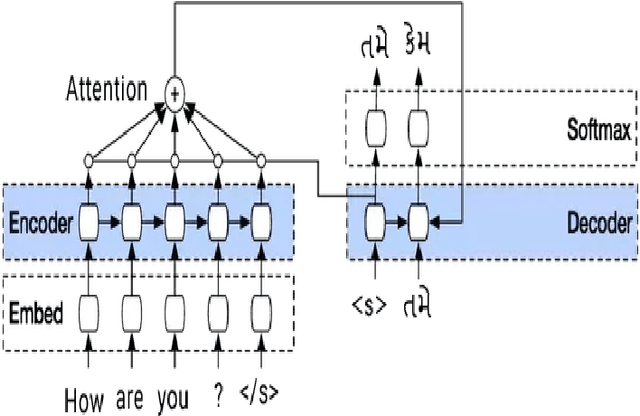
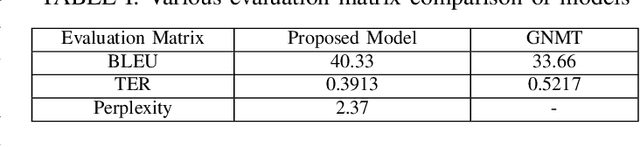
Neural machine translation (NMT) is a recent and effective technique which led to remarkable improvements in comparison of conventional machine translation techniques. Proposed neural machine translation model developed for the Gujarati language contains encoder-decoder with attention mechanism. In India, almost all the languages are originated from their ancestral language - Sanskrit. They are having inevitable similarities including lexical and named entity similarity. Translating into Indic languages is always be a challenging task. In this paper, we have presented the neural machine translation system (NMT) that can efficiently translate Indic languages like Hindi and Gujarati that together covers more than 58.49 percentage of total speakers in the country. We have compared the performance of our NMT model with automatic evaluation matrices such as BLEU, perplexity and TER matrix. The comparison of our network with Google translate is also presented where it outperformed with a margin of 6 BLEU score on English-Gujarati translation.
Nonlinear Semi-Parametric Models for Survival Analysis
May 14, 2019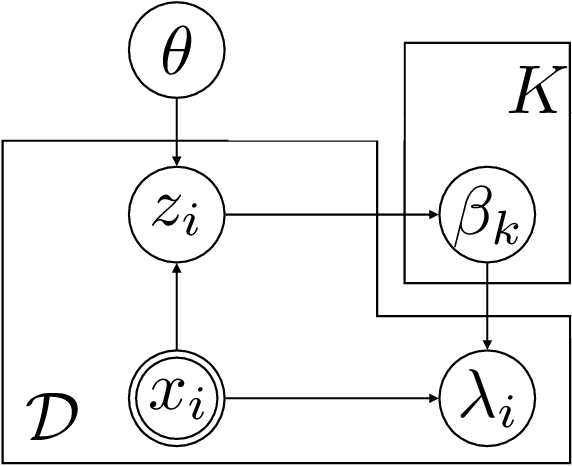
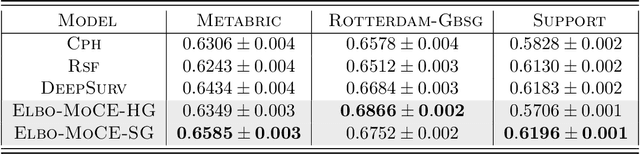
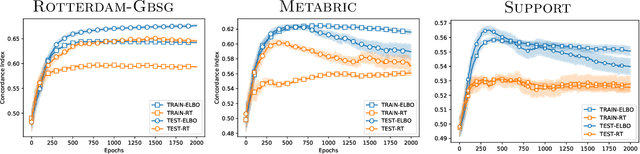

Semi-parametric survival analysis methods like the Cox Proportional Hazards (CPH) regression (Cox, 1972) are a popular approach for survival analysis. These methods involve fitting of the log-proportional hazard as a function of the covariates and are convenient as they do not require estimation of the baseline hazard rate. Recent approaches have involved learning non-linear representations of the input covariates and demonstrate improved performance. In this paper we argue against such deep parameterizations for survival analysis and experimentally demonstrate that more interpretable semi-parametric models inspired from mixtures of experts perform equally well or in some cases better than such overly parameterized deep models.
Optimal Approach for Image Recognition using Deep Convolutional Architecture
Apr 25, 2019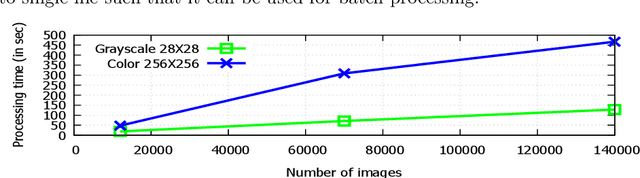
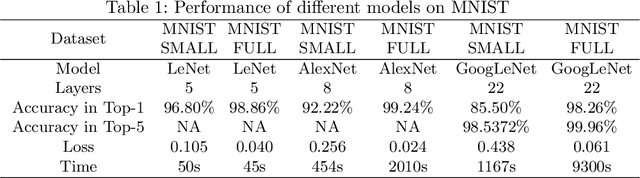
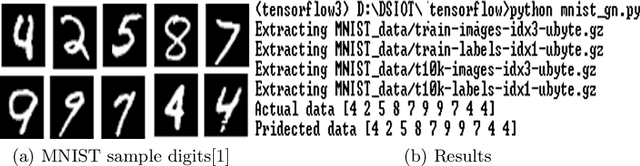
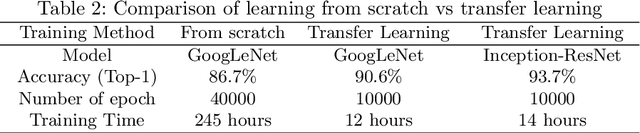
In the recent time deep learning has achieved huge popularity due to its performance in various machine learning algorithms. Deep learning as hierarchical or structured learning attempts to model high level abstractions in data by using a group of processing layers. The foundation of deep learning architectures is inspired by the understanding of information processing and neural responses in human brain. The architectures are created by stacking multiple linear or non-linear operations. The article mainly focuses on the state-of-art deep learning models and various real world applications specific training methods. Selecting optimal architecture for specific problem is a challenging task, at a closing stage of the article we proposed optimal approach to deep convolutional architecture for the application of image recognition.
Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks
Mar 08, 2019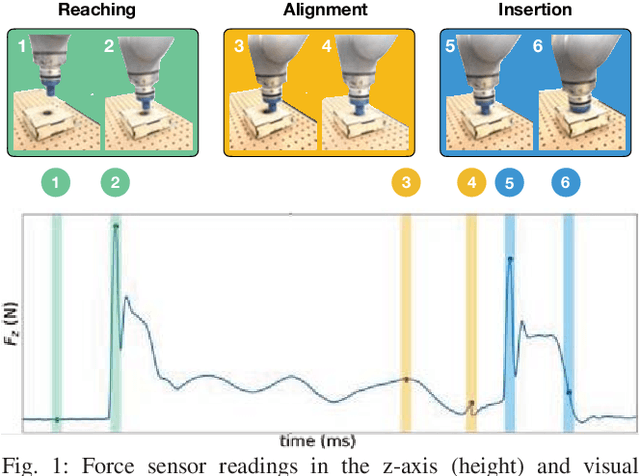
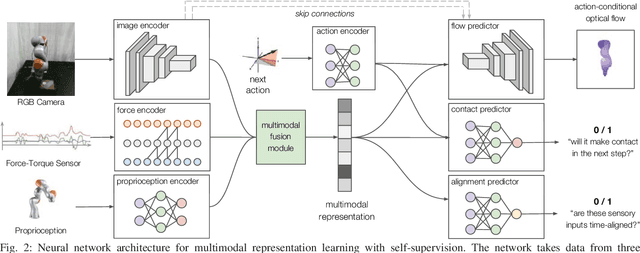

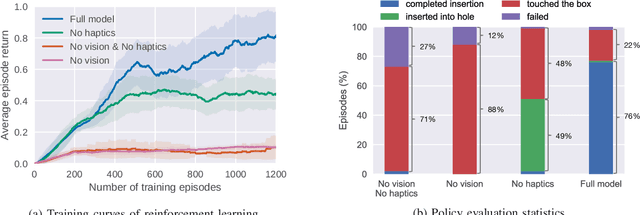
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. However, it is non-trivial to manually design a robot controller that combines modalities with very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. We use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. We evaluate our method on a peg insertion task, generalizing over different geometry, configurations, and clearances, while being robust to external perturbations. Results for simulated and real robot experiments are presented.
Motion-based Object Segmentation based on Dense RGB-D Scene Flow
Jul 24, 2018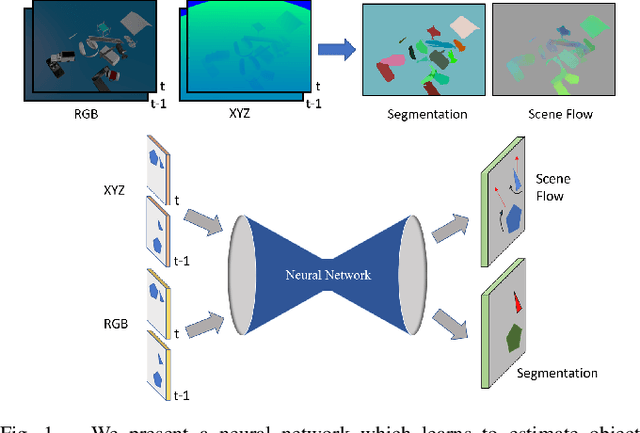
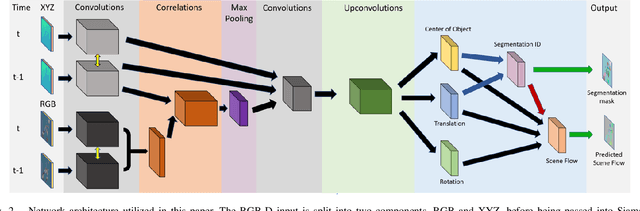
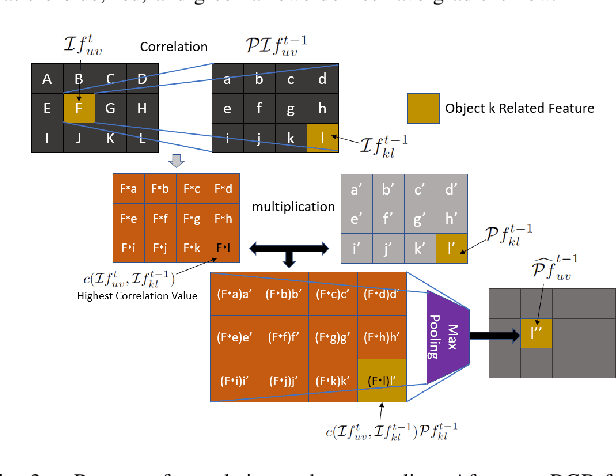
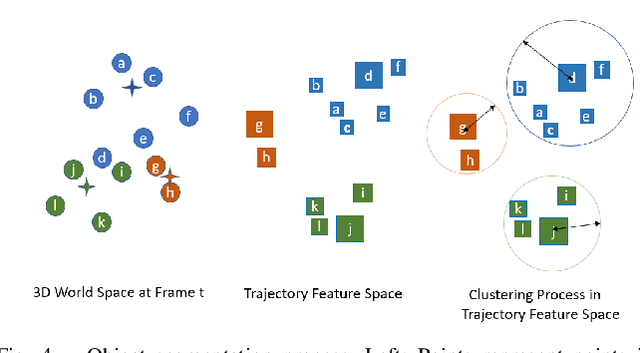
Given two consecutive RGB-D images, we propose a model that estimates a dense 3D motion field, also known as scene flow. We take advantage of the fact that in robot manipulation scenarios, scenes often consist of a set of rigidly moving objects. Our model jointly estimates (i) the segmentation of the scene into an unknown but finite number of objects, (ii) the motion trajectories of these objects and (iii) the object scene flow. We employ an hourglass, deep neural network architecture. In the encoding stage, the RGB and depth images undergo spatial compression and correlation. In the decoding stage, the model outputs three images containing a per-pixel estimate of the corresponding object center as well as object translation and rotation. This forms the basis for inferring the object segmentation and final object scene flow. To evaluate our model, we generated a new and challenging, large-scale, synthetic dataset that is specifically targeted at robotic manipulation: It contains a large number of scenes with a very diverse set of simultaneously moving 3D objects and is recorded with a simulated, static RGB-D camera. In quantitative experiments, we show that we outperform state-of-the-art scene flow and motion-segmentation methods on this data set. In qualitative experiments, we show how our learned model transfers to challenging real-world scenes, visually generating better results than existing methods.