 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
Bringing Multimodality to Amazon Visual Search System
Dec 17, 2024



Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
DreamBlend: Advancing Personalized Fine-tuning of Text-to-Image Diffusion Models
Nov 28, 2024



Given a small number of images of a subject, personalized image generation techniques can fine-tune large pre-trained text-to-image diffusion models to generate images of the subject in novel contexts, conditioned on text prompts. In doing so, a trade-off is made between prompt fidelity, subject fidelity and diversity. As the pre-trained model is fine-tuned, earlier checkpoints synthesize images with low subject fidelity but high prompt fidelity and diversity. In contrast, later checkpoints generate images with low prompt fidelity and diversity but high subject fidelity. This inherent trade-off limits the prompt fidelity, subject fidelity and diversity of generated images. In this work, we propose DreamBlend to combine the prompt fidelity from earlier checkpoints and the subject fidelity from later checkpoints during inference. We perform a cross attention guided image synthesis from a later checkpoint, guided by an image generated by an earlier checkpoint, for the same prompt. This enables generation of images with better subject fidelity, prompt fidelity and diversity on challenging prompts, outperforming state-of-the-art fine-tuning methods.
X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
Jul 18, 2024



Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by integrating visual perception capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and detailed visual representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) and MAE-ViT (MIM-based). It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding detailed visual understanding. Extensive evaluations indicate that X-Former excels in visual reasoning tasks involving both structural and semantic categories in the GQA dataset. Assessment on fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.
MLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling
Sep 24, 2021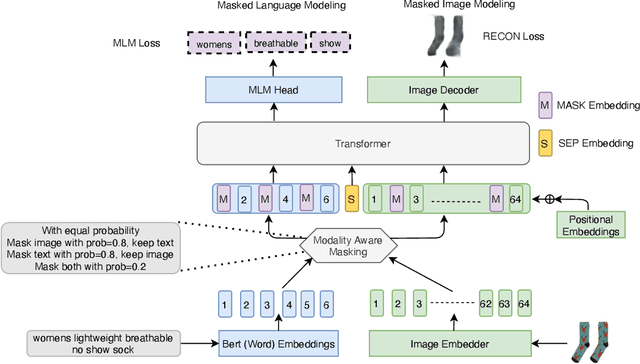

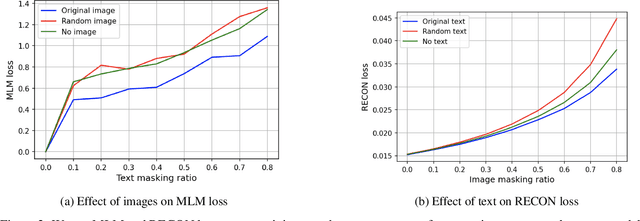
Vision-and-Language Pre-training (VLP) improves model performance for downstream tasks that require image and text inputs. Current VLP approaches differ on (i) model architecture (especially image embedders), (ii) loss functions, and (iii) masking policies. Image embedders are either deep models like ResNet or linear projections that directly feed image-pixels into the transformer. Typically, in addition to the Masked Language Modeling (MLM) loss, alignment-based objectives are used for cross-modality interaction, and RoI feature regression and classification tasks for Masked Image-Region Modeling (MIRM). Both alignment and MIRM objectives mostly do not have ground truth. Alignment-based objectives require pairings of image and text and heuristic objective functions. MIRM relies on object detectors. Masking policies either do not take advantage of multi-modality or are strictly coupled with alignments generated by other models. In this paper, we present Masked Language and Image Modeling (MLIM) for VLP. MLIM uses two loss functions: Masked Language Modeling (MLM) loss and image reconstruction (RECON) loss. We propose Modality Aware Masking (MAM) to boost cross-modality interaction and take advantage of MLM and RECON losses that separately capture text and image reconstruction quality. Using MLM + RECON tasks coupled with MAM, we present a simplified VLP methodology and show that it has better downstream task performance on a proprietary e-commerce multi-modal dataset.
Hypergraph Pre-training with Graph Neural Networks
May 23, 2021
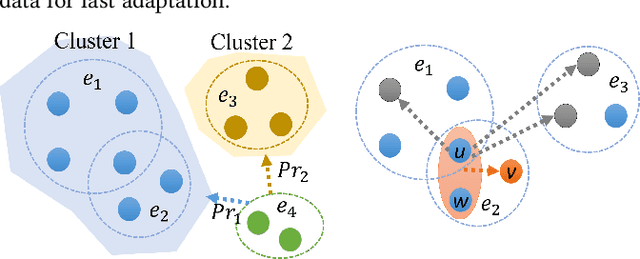
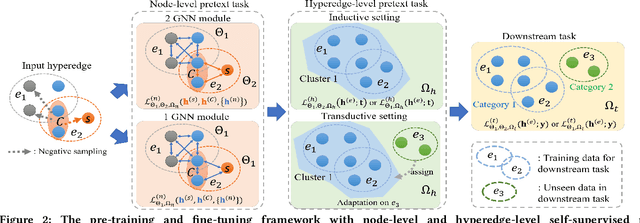
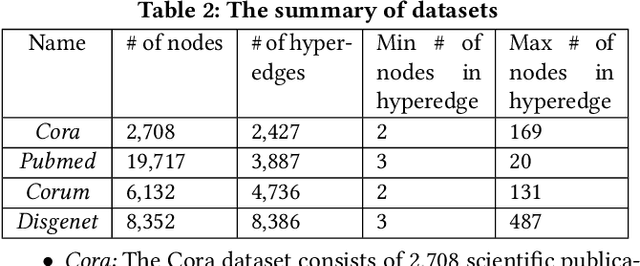
Despite the prevalence of hypergraphs in a variety of high-impact applications, there are relatively few works on hypergraph representation learning, most of which primarily focus on hyperlink prediction, often restricted to the transductive learning setting. Among others, a major hurdle for effective hypergraph representation learning lies in the label scarcity of nodes and/or hyperedges. To address this issue, this paper presents an end-to-end, bi-level pre-training strategy with Graph Neural Networks for hypergraphs. The proposed framework named HyperGene bears three distinctive advantages. First, it is capable of ingesting the labeling information when available, but more importantly, it is mainly designed in the self-supervised fashion which significantly broadens its applicability. Second, at the heart of the proposed HyperGene are two carefully designed pretexts, one on the node level and the other on the hyperedge level, which enable us to encode both the local and the global context in a mutually complementary way. Third, the proposed framework can work in both transductive and inductive settings. When applying the two proposed pretexts in tandem, it can accelerate the adaptation of the knowledge from the pre-trained model to downstream applications in the transductive setting, thanks to the bi-level nature of the proposed method. The extensive experimental results demonstrate that: (1) HyperGene achieves up to 5.69% improvements in hyperedge classification, and (2) improves pre-training efficiency by up to 42.80% on average.
Graph Neural Networks for Inconsistent Cluster Detection in Incremental Entity Resolution
May 12, 2021
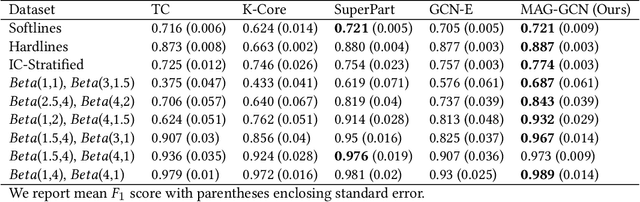
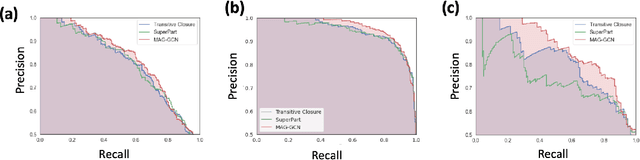
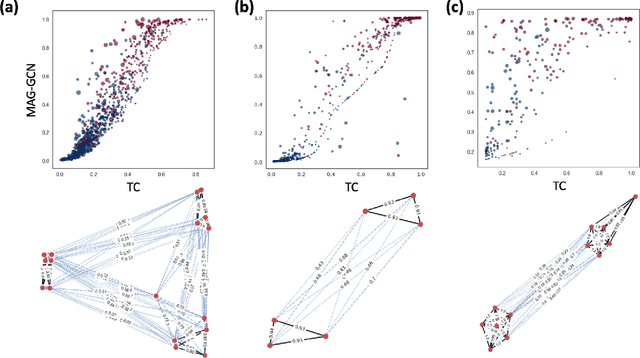
Online stores often utilize product relationships such as bundles and substitutes to improve their catalog quality and guide customers through myriad choices. Entity resolution using pairwise product matching models offers a means of inferring relationships between products. In mature data repositories, the relationships may be mostly correct but require incremental improvements owing to errors in the original data or in the entity resolution system. It is critical to devise incremental entity resolution (IER) approaches for improving the health of relationships. However, most existing research on IER focuses on the addition of new products or information into existing relationships. Relatively little research has been done for detecting low quality within current relationships. This paper proposes a novel method for identifying inconsistent clusters (IC), existing groups of related products that do not belong together. We propose to treat the identification of inconsistent clusters as a supervised learning task which predicts whether a graph of products with similarities as weighted edges should be partitioned into multiple clusters. In this case, the problem becomes a classification task on weighted graphs and represents an interesting application area for modern tools such as Graph Neural Networks (GNNs). We demonstrate that existing Message Passing neural networks perform well at this task, exceeding traditional graph processing techniques. We also develop a novel message aggregation scheme for Message Passing Neural Networks that further improves the performance of GNNs on this task. We apply the model to synthetic datasets, a public benchmark dataset, and an internal application. Our results demonstrate the value of graph classification in IER and the ability of graph neural networks to develop useful representations for graph partitioning.