 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Bringing Multimodality to Amazon Visual Search System
Dec 17, 2024



Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
Diffusion Models for Multi-Task Generative Modeling
Jul 24, 2024
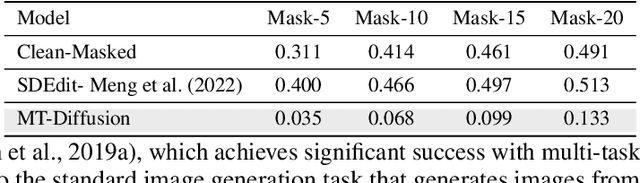
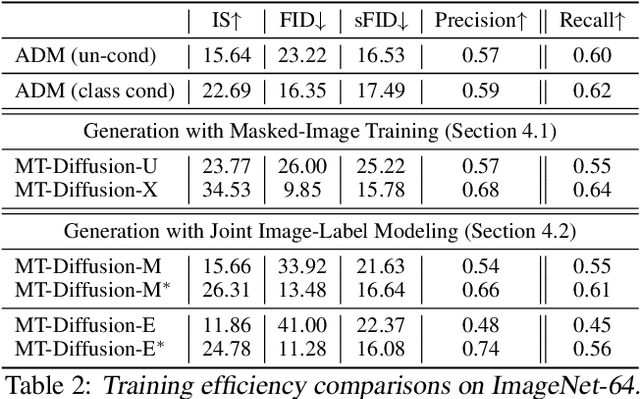
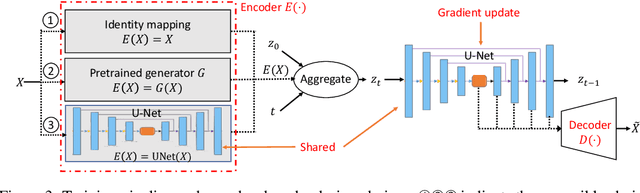
Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal diffusion model in a common diffusion space. We define the forward diffusion process to be driven by an information aggregation from multiple types of task-data, e.g., images for a generation task and labels for a classification task. In the reverse process, we enforce information sharing by parameterizing a shared backbone denoising network with additional modality-specific decoder heads. Such a structure can simultaneously learn to generate different types of multi-modal data with a multi-task loss, which is derived from a new multi-modal variational lower bound that generalizes the standard diffusion model. We propose several multimodal generation settings to verify our framework, including image transition, masked-image training, joint image-label and joint image-representation generative modeling. Extensive experimental results on ImageNet indicate the effectiveness of our framework for various multi-modal generative modeling, which we believe is an important research direction worthy of more future explorations.