 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Price Per Unit Problem Around the World: Formulating Fact Extraction as Question Answering
Apr 12, 2022


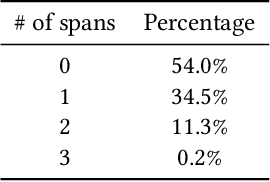
Price Per Unit (PPU) is an essential information for consumers shopping on e-commerce websites when comparing products. Finding total quantity in a product is required for computing PPU, which is not always provided by the sellers. To predict total quantity, all relevant quantities given in a product attributes such as title, description and image need to be inferred correctly. We formulate this problem as a question-answering (QA) task rather than named entity recognition (NER) task for fact extraction. In our QA approach, we first predict the unit of measure (UoM) type (e.g., volume, weight or count), that formulates the desired question (e.g., "What is the total volume?") and then use this question to find all the relevant answers. Our model architecture consists of two subnetworks for the two subtasks: a classifier to predict UoM type (or the question) and an extractor to extract the relevant quantities. We use a deep character-level CNN architecture for both subtasks, which enables (1) easy expansion to new stores with similar alphabets, (2) multi-span answering due to its span-image architecture and (3) easy deployment by keeping model-inference latency low. Our QA approach outperforms rule-based methods by 34.4% in precision and also BERT-based fact extraction approach in all stores globally, with largest precision lift of 10.6% in the US store.
MLIM: Vision-and-Language Model Pre-training with Masked Language and Image Modeling
Sep 24, 2021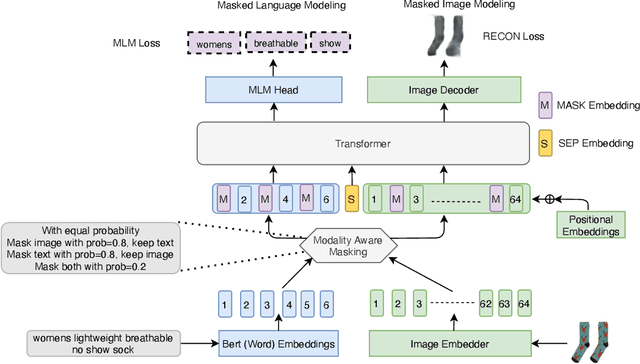

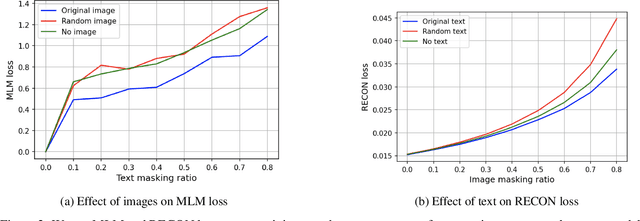
Vision-and-Language Pre-training (VLP) improves model performance for downstream tasks that require image and text inputs. Current VLP approaches differ on (i) model architecture (especially image embedders), (ii) loss functions, and (iii) masking policies. Image embedders are either deep models like ResNet or linear projections that directly feed image-pixels into the transformer. Typically, in addition to the Masked Language Modeling (MLM) loss, alignment-based objectives are used for cross-modality interaction, and RoI feature regression and classification tasks for Masked Image-Region Modeling (MIRM). Both alignment and MIRM objectives mostly do not have ground truth. Alignment-based objectives require pairings of image and text and heuristic objective functions. MIRM relies on object detectors. Masking policies either do not take advantage of multi-modality or are strictly coupled with alignments generated by other models. In this paper, we present Masked Language and Image Modeling (MLIM) for VLP. MLIM uses two loss functions: Masked Language Modeling (MLM) loss and image reconstruction (RECON) loss. We propose Modality Aware Masking (MAM) to boost cross-modality interaction and take advantage of MLM and RECON losses that separately capture text and image reconstruction quality. Using MLM + RECON tasks coupled with MAM, we present a simplified VLP methodology and show that it has better downstream task performance on a proprietary e-commerce multi-modal dataset.
Associative Adversarial Networks
Nov 18, 2016
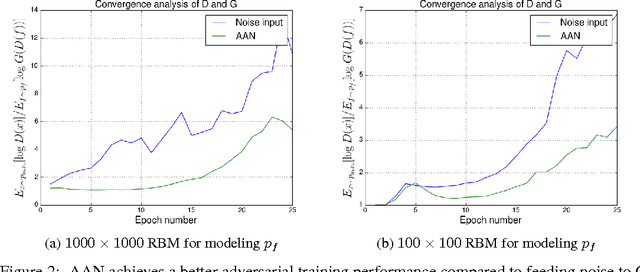

We propose a higher-level associative memory for learning adversarial networks. Generative adversarial network (GAN) framework has a discriminator and a generator network. The generator (G) maps white noise (z) to data samples while the discriminator (D) maps data samples to a single scalar. To do so, G learns how to map from high-level representation space to data space, and D learns to do the opposite. We argue that higher-level representation spaces need not necessarily follow a uniform probability distribution. In this work, we use Restricted Boltzmann Machines (RBMs) as a higher-level associative memory and learn the probability distribution for the high-level features generated by D. The associative memory samples its underlying probability distribution and G learns how to map these samples to data space. The proposed associative adversarial networks (AANs) are generative models in the higher-levels of the learning, and use adversarial non-stochastic models D and G for learning the mapping between data and higher-level representation spaces. Experiments show the potential of the proposed networks.