 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Price Per Unit Problem Around the World: Formulating Fact Extraction as Question Answering
Apr 12, 2022


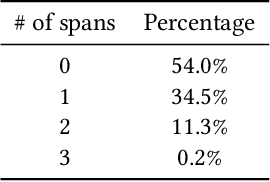
Price Per Unit (PPU) is an essential information for consumers shopping on e-commerce websites when comparing products. Finding total quantity in a product is required for computing PPU, which is not always provided by the sellers. To predict total quantity, all relevant quantities given in a product attributes such as title, description and image need to be inferred correctly. We formulate this problem as a question-answering (QA) task rather than named entity recognition (NER) task for fact extraction. In our QA approach, we first predict the unit of measure (UoM) type (e.g., volume, weight or count), that formulates the desired question (e.g., "What is the total volume?") and then use this question to find all the relevant answers. Our model architecture consists of two subnetworks for the two subtasks: a classifier to predict UoM type (or the question) and an extractor to extract the relevant quantities. We use a deep character-level CNN architecture for both subtasks, which enables (1) easy expansion to new stores with similar alphabets, (2) multi-span answering due to its span-image architecture and (3) easy deployment by keeping model-inference latency low. Our QA approach outperforms rule-based methods by 34.4% in precision and also BERT-based fact extraction approach in all stores globally, with largest precision lift of 10.6% in the US store.