 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Question Answering with Reformulations over Knowledge Graph
Dec 27, 2023



conversational question answering (convQA) over knowledge graphs (KGs) involves answering multi-turn natural language questions about information contained in a KG. State-of-the-art methods of ConvQA often struggle with inexplicit question-answer pairs. These inputs are easy for human beings to understand given a conversation history, but hard for a machine to interpret, which can degrade ConvQA performance. To address this problem, we propose a reinforcement learning (RL) based model, CornNet, which utilizes question reformulations generated by large language models (LLMs) to improve ConvQA performance. CornNet adopts a teacher-student architecture where a teacher model learns question representations using human writing reformulations, and a student model to mimic the teacher model's output via reformulations generated by LLMs. The learned question representation is then used by an RL model to locate the correct answer in a KG. Extensive experimental results show that CornNet outperforms state-of-the-art convQA models.
Hierarchical Multi-Marginal Optimal Transport for Network Alignment
Oct 06, 2023Finding node correspondence across networks, namely multi-network alignment, is an essential prerequisite for joint learning on multiple networks. Despite great success in aligning networks in pairs, the literature on multi-network alignment is sparse due to the exponentially growing solution space and lack of high-order discrepancy measures. To fill this gap, we propose a hierarchical multi-marginal optimal transport framework named HOT for multi-network alignment. To handle the large solution space, multiple networks are decomposed into smaller aligned clusters via the fused Gromov-Wasserstein (FGW) barycenter. To depict high-order relationships across multiple networks, the FGW distance is generalized to the multi-marginal setting, based on which networks can be aligned jointly. A fast proximal point method is further developed with guaranteed convergence to a local optimum. Extensive experiments and analysis show that our proposed HOT achieves significant improvements over the state-of-the-art in both effectiveness and scalability.
Neural Multi-network Diffusion towards Social Recommendation
Apr 11, 2023Graph Neural Networks (GNNs) have been widely applied on a variety of real-world applications, such as social recommendation. However, existing GNN-based models on social recommendation suffer from serious problems of generalization and oversmoothness, because of the underexplored negative sampling method and the direct implanting of the off-the-shelf GNN models. In this paper, we propose a succinct multi-network GNN-based neural model (NeMo) for social recommendation. Compared with the existing methods, the proposed model explores a generative negative sampling strategy, and leverages both the positive and negative user-item interactions for users' interest propagation. The experiments show that NeMo outperforms the state-of-the-art baselines on various real-world benchmark datasets (e.g., by up to 38.8% in terms of NDCG@15).
Geometric Matrix Completion via Sylvester Multi-Graph Neural Network
Jun 19, 2022
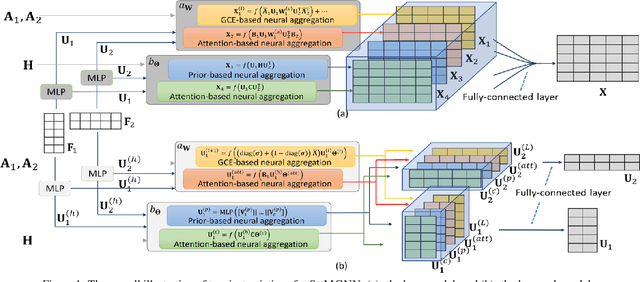
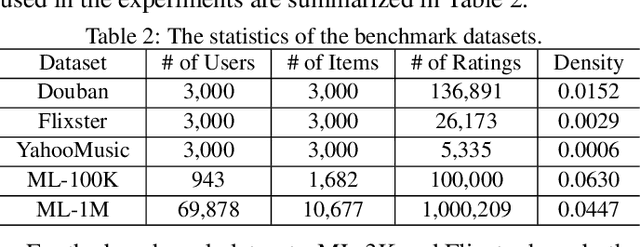
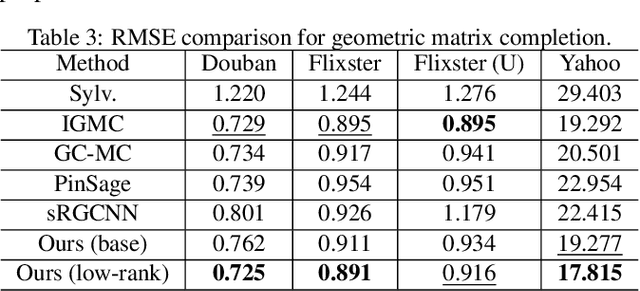
Despite the success of the Sylvester equation empowered methods on various graph mining applications, such as semi-supervised label learning and network alignment, there also exists several limitations. The Sylvester equation's inability of modeling non-linear relations and the inflexibility of tuning towards different tasks restrict its performance. In this paper, we propose an end-to-end neural framework, SYMGNN, which consists of a multi-network neural aggregation module and a prior multi-network association incorporation learning module. The proposed framework inherits the key ideas of the Sylvester equation, and meanwhile generalizes it to overcome aforementioned limitations. Empirical evaluations on real-world datasets show that the instantiations of SYMGNN overall outperform the baselines in geometric matrix completion task, and its low-rank instantiation could further reduce the memory consumption by 16.98\% on average.
Learning Optimal Propagation for Graph Neural Networks
May 06, 2022
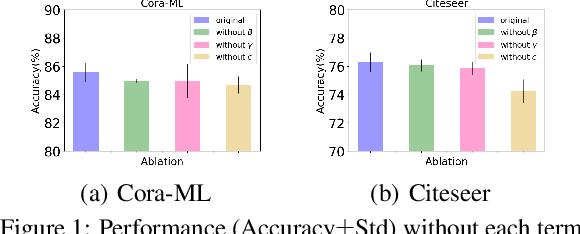
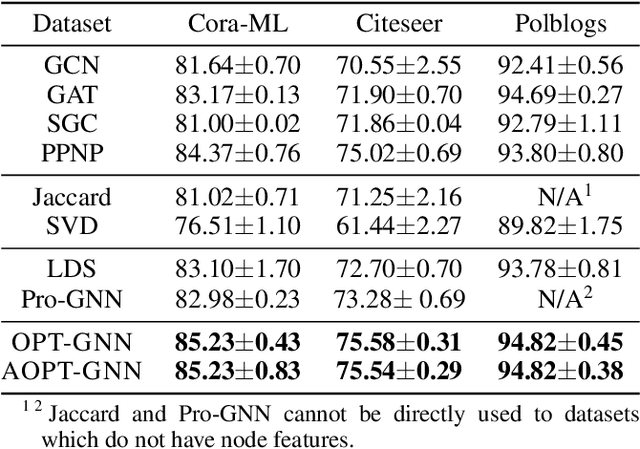
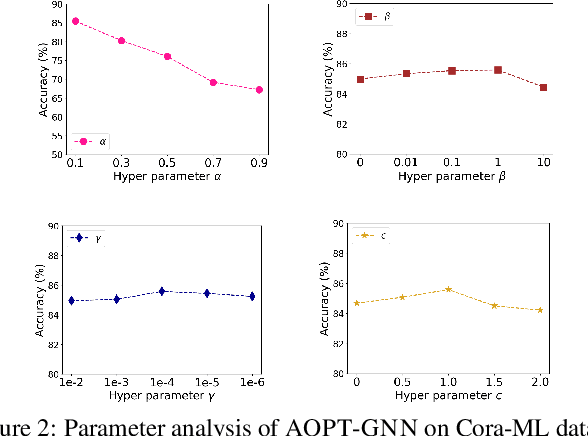
Graph Neural Networks (GNNs) have achieved tremendous success in a variety of real-world applications by relying on the fixed graph data as input. However, the initial input graph might not be optimal in terms of specific downstream tasks, because of information scarcity, noise, adversarial attacks, or discrepancies between the distribution in graph topology, features, and groundtruth labels. In this paper, we propose a bi-level optimization-based approach for learning the optimal graph structure via directly learning the Personalized PageRank propagation matrix as well as the downstream semi-supervised node classification simultaneously. We also explore a low-rank approximation model for further reducing the time complexity. Empirical evaluations show the superior efficacy and robustness of the proposed model over all baseline methods.
Hypergraph Pre-training with Graph Neural Networks
May 23, 2021
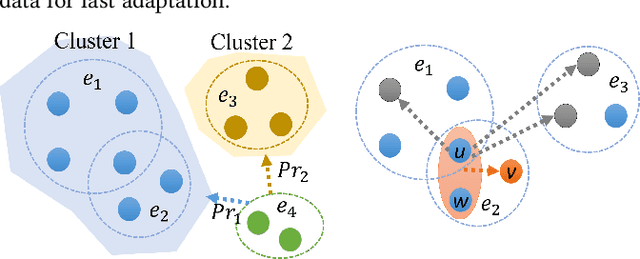
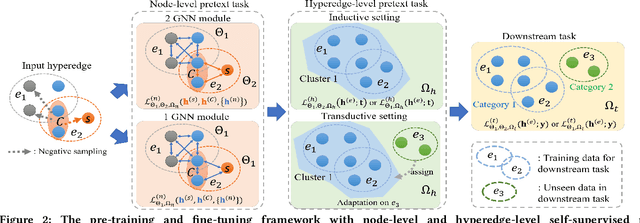
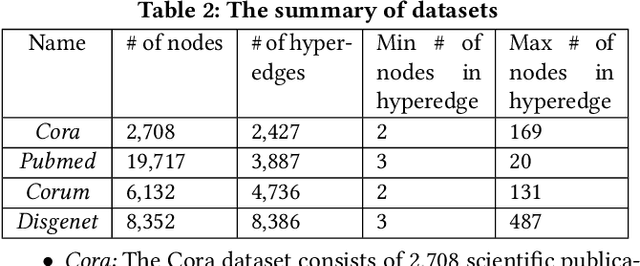
Despite the prevalence of hypergraphs in a variety of high-impact applications, there are relatively few works on hypergraph representation learning, most of which primarily focus on hyperlink prediction, often restricted to the transductive learning setting. Among others, a major hurdle for effective hypergraph representation learning lies in the label scarcity of nodes and/or hyperedges. To address this issue, this paper presents an end-to-end, bi-level pre-training strategy with Graph Neural Networks for hypergraphs. The proposed framework named HyperGene bears three distinctive advantages. First, it is capable of ingesting the labeling information when available, but more importantly, it is mainly designed in the self-supervised fashion which significantly broadens its applicability. Second, at the heart of the proposed HyperGene are two carefully designed pretexts, one on the node level and the other on the hyperedge level, which enable us to encode both the local and the global context in a mutually complementary way. Third, the proposed framework can work in both transductive and inductive settings. When applying the two proposed pretexts in tandem, it can accelerate the adaptation of the knowledge from the pre-trained model to downstream applications in the transductive setting, thanks to the bi-level nature of the proposed method. The extensive experimental results demonstrate that: (1) HyperGene achieves up to 5.69% improvements in hyperedge classification, and (2) improves pre-training efficiency by up to 42.80% on average.
KompaRe: A Knowledge Graph Comparative Reasoning System
Nov 06, 2020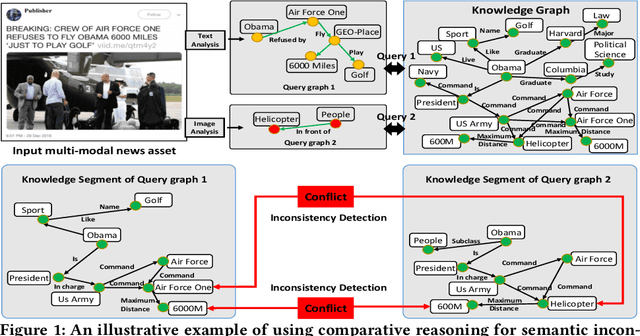
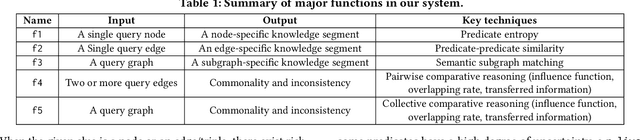
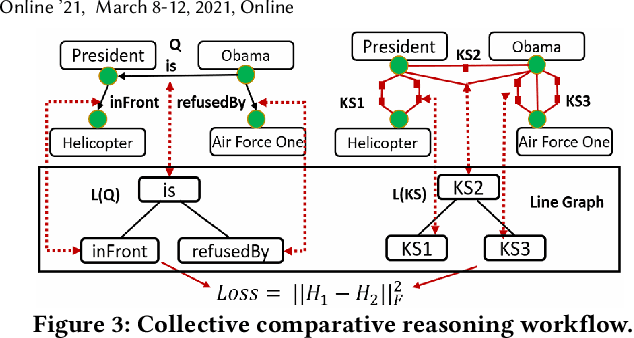
Reasoning is a fundamental capability for harnessing valuable insight, knowledge and patterns from knowledge graphs. Existing work has primarily been focusing on point-wise reasoning, including search, link predication, entity prediction, subgraph matching and so on. This paper introduces comparative reasoning over knowledge graphs, which aims to infer the commonality and inconsistency with respect to multiple pieces of clues. We envision that the comparative reasoning will complement and expand the existing point-wise reasoning over knowledge graphs. In detail, we develop KompaRe, the first of its kind prototype system that provides comparative reasoning capability over large knowledge graphs. We present both the system architecture and its core algorithms, including knowledge segment extraction, pairwise reasoning and collective reasoning. Empirical evaluations demonstrate the efficacy of the proposed KompaRe.